版权声明:转载请注明出处. https://blog.csdn.net/laodaliubei/article/details/84872174
Why pool?
Dynamically created subprocesses have following inadequacies:
- 动态创建进程或线程比较耗费时间,这将拖慢客户响应;
- 动态创建的进程或线程除非做特殊处理,否则通常只为一个客户服务,导致存在大量的颗粒进程,而进程(线程)间的切换消耗大量cpu时间;
- 动态创建的子进程是当前进程的完整映像,当前进程必须严格管理文件描述符/堆内存等系统资源,否则子进程可能复制它们,导致系统资源被急剧耗尽.
overview
Definition on wikimedia:
- A pool is a collection of resources that are kept ready to use, rather than acquired on use and released afterwards. A pool client requests a resource from the pool and performs desired operations on the returned resource. When the client finishes its use of the resource, it is returned to the pool rather than released and lost.
- The pooling of resources can offer a significant performance boost in situations that have high cost associated with resource acquiring, high rate of the requests for resources, and a low overall count of simultaneously used resources.
- Pooling is useful when the latency is a concern.
- Pooling is useful for expensive-to-compute data, notably large graphic objects like fonts or bitmaps, acting essentially as a data cache or a memoization technique.
- Special cases of pools are connection pools, thread pools, and memory pools.
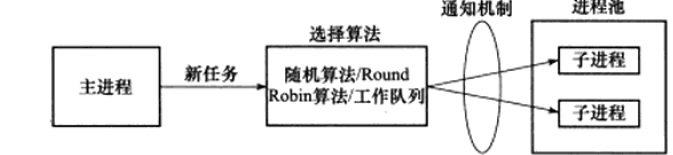
- 进程池是由服务器预先创建的一组子进程,数量大致与cpu数相当.
- 进程池中所有子进程都运行相同的代码,有相同的属性,相对"干净";
- 当新任务到来,主进程通过某种方式从进程池中挑一个来为客户服务,通常有两种方式:
- 采用某种算法. 最简单最常用的是随机算法 or Round Robin(轮流选取),你也可能需要更好的算法来使任务更均匀地分配.
- 共享工作队列.
- 选定子进程后,还需要某种机制来通知子进程,并传递数据. 最简单的方法是通道.
- 父线程和子线程间传递数据就要简单得多: 全局数据能被动所有线程共享.