一. 相关属性
- index
- values
- shape
- size
- dtype
- name
- head tail
Series对象可以通过index与values访问索引与值。其中,我们也可以通过修改index属性来修改Series的索引。
说明:
- 如果没有指定索引,则会自动生成从0开始的整数值索引,也可以使用index显式指定索引。
- Series对象与index具有name属性。Series的name属性可在创建时通过name参数指定。
- 当数值较多时,可以通过head与tail访问前 / 后N个数据。【中间的怎么办?】
- Series对象的数据只能是一维数组类型。
Series也可以通过索引进行访问数据,与Numpy的ndarray数组对象索引是否存在不同?
二. 进一步讲解
1. index
比较实用:可以改变索引,和ndarray的不一样之处
index Series对象的索引
index所以就是获得索引
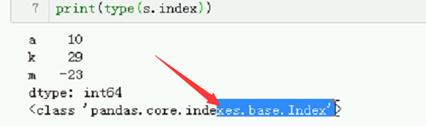
# index Series对象的索引。
# s = pd.Series([10, 29, -23])
# s.index
# 我们也可以修改索引。
# s.index = ["a", "k", "m"]
# print(s)
# print(type(s.index))
比较实用:可以改变索引,和ndarray的不一样之处
index Series对象的索引
index所以就是获得索引
eg. 4622条数据 索引值 到 4611

我们也可以修改索引为列表
s.index = [‘a’,’k’,’m’]

Index也是索引对象
Class A创建类A
A属性也是一个对象B
Def ini
Selb b = B()
Clas B
OK
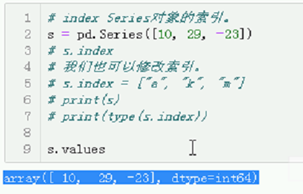
2. values,shape,size,dtype
#vlaues属性,返回Series所关联的值(ndarray数组对象)
# Series类似于字典的映射存储。字典具有keys与vlaues方法。
# Series的index属性就类似于字典的keys方法。Series的vlaues属性就类似于字典的values方法。
# type(s.values)
# 返回Series的形状。(也就是Series所关联的ndarray数组的形状。)
# s.shape
# 返回Series元素的个数。
# s.size
# 返回Series元素的类型。
# s.dtype
index属性相当于字典里的key方法,
所以series类似于字典的映射存储。
字典具有keys values方法,
这里,series的index属性就类似于字典的keys方法,
Series的values属性就类似于字典的values方法。
Values属性返回series所关联的值(ndarray数组对象)

shape
返回series所关联的ndarray数组的形状: 一维,3个。
每个维度的长度,
也可以看出几个维度。
Size
返回series元素的个数。
Dtype
返回series元素的类型,
以上可以看出,Series里元素的类型也是一一致的,
不一致的话,就会找最兼容的。
# 我们可以在创建Series时,显式通过index参数来指定索引。如果没有显式指定,则生成从0开始,增量为1的索引。(0, 1, 2, 3……)
# s = pd.Series([5, 7, 20], index=[5, 10, 20])
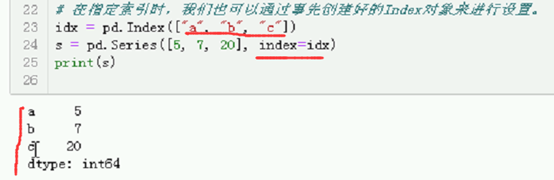
# 在指定索引时,我们也可以通过事先创建好的Index对象来进行设置。
idx = pd.Index(["a", "b", "c"])
s = pd.Series([5, 7, 20], index=idx)
print(s)
指定index
可以在创建series时,显示通过index参数来指定索引,如果没有显示指定,
则生成从0开始,增量为1的索引。

我们再来指定。

# 以上两种方式都可以正常使用。但是,当有多个Series的index相同时,建议先创建好Index对象,然后
# 将该对象指派给每个Series。因为这样,以后索引对象修改时,比较方法,无需去改变每一个Series定义之处。
我们创建完后,通过index属性来修改,
创建之后,再赋值。
在指定索引时,也可以通过事先创建好的Index对象来进行设置,这个index对象就是索引对象。
# 这样定义,以后index发生改变时,每个Series定义之处都需要进行修改。
s1 = pd.Series([5, 7, 20], index=["a", "b", "c"])
s2 = pd.Series([5, 7, 20], index=["a", "b", "c"])
s3 = pd.Series([5, 7, 20], index=["a", "b", "c"])
# 这样定义,以后index发生改变时,无需修改Series定义之处,只需要修改Index对象定义之处。
s1 = pd.Series([5, 7, 20], index=idx)
s2 = pd.Series([5, 7, 20], index=idx)
s3 = pd.Series([5, 7, 20], index=idx)
好处是什么?
多个series对象,不用每个都写索引,直接指定就行了。
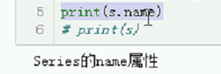
3. name
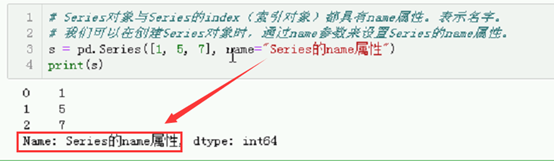
# Series对象与Series的index(索引对象)都具有name属性。表示名字。
# 我们可以在创建Series对象时,通过name参数来设置Series的name属性。
# s = pd.Series([1, 5, 7], name="Series的name属性")
# 我们也可以在创建Series对象后,对name属性进行设置(修改)。
# print(s.name)
# s.name = "修改一下"
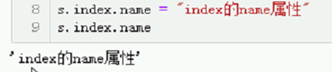
# s.index.name = "index的name属性"
# 我们可以在创建Index对象时,为Index对象指定name属性。
idx = pd.Index(["a", "b", "c"], name="index的name属性")
s = pd.Series([1, 5, 7], name="Series的name属性", index=idx)
print(s)
print(s.index.name)
# Seried的name属性与Series的index的name属性,二者可以在输出中得到体现,但是,二者的价值
# 不仅仅只体现在输出中。
作用目前看就是多了一行,
体现在输出,
不仅仅是在输出有价值,DataFrame
创建好之后,也可以再修改

不仅series,索引对象也具有name属性,
需要设置。
作用?
在输出中得到显示,
价值不仅仅在输出,后面还有关于索引的操作。

s.index.name = ‘index的name属性’

4. head / tail
# head / tail
s = pd.Series(range(30))
# print(s)
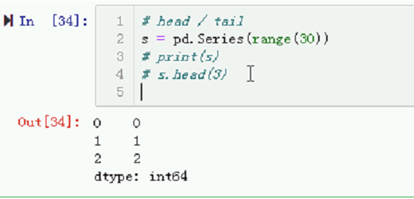
# 显示参数指定的前(后)N条记录。最多显示N条记录。N为最多显示的数量,而不是一定显示的数量。
# s.head(3)
# s.tail(6)
# 当没有参数时,默认值为5。
# s.head()
# Series只能是一维的数据类型。否则会产生错误。
# 错误。
# s = pd.Series(np.ones(shape=(5, 3)))
访问不方便,
可能我们只想看前几条。
前三条
后六条
注意,n为最多,不是一定显示,
数据集里有50条,n想显示100条,不可能。
当没有参数时,默认值为5。
Series只能是一维的数据类型


Series与ndarray都可以通过索引来进行访问,二者之间的区别:
# Series与ndarray都可以通过索引来进行访问,二者之间的区别:
a = np.array([1, 2, 3, 4])
s = pd.Series([1, 2, 3, 4])
# ndarray的索引时基于位置的,当数组创建完成,索引就固定了,我们不能去修改索引。
# Series的索引类似于字典的key-value映射,我们是可以自行指定索引内容的。
# a[-2]
# d = {0:1, 1:2, 2:3, 3:4}
d[0]
d[-2]
Ndarray的索引是基于位置的,不能去修改索引,
Series的索引是可以自己去指定的,相当于字典的key-value
字典也可以自己指定,
A[0]永远是1。
字典可以自己指定。
Key不存在,
S[0]默认的key是0 没有生成-2的的key。

一个是基于位置,
一个是基于字典 映射 key value。