附件【百度云盘:https://pan.baidu.com/s/1c1NPoK0UEvgKgD0xANS0jA 密码:x72k】
首先,先说下流程吧:
1、安装Eclipse(MyEclipse/intellij IDEA)
2、将hadoop-eclipse-plugin-2.6.0.jar(这个jar百度下应该是有的)这个jar放在Myeclipse的安装目录的plugins
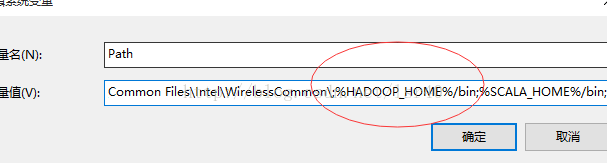
3、在Windows解压hadoop-2.7.6.tar.gz,然后配置hadoop的环境变量(贴两个图上来,就不具体说了,这不就跟配置jdk是一样的嘛~)

4、打开Eclipse,然后看如下的图
打开eclipse --> Window --> Perspective --> Open Perspective --> 点击 Other

这里只要你有把正确的hadoop-eclipse-plugin-2.6.0.jar放到正确的地方,肯定能够找到这个蓝色小象,然后点开就可以看到
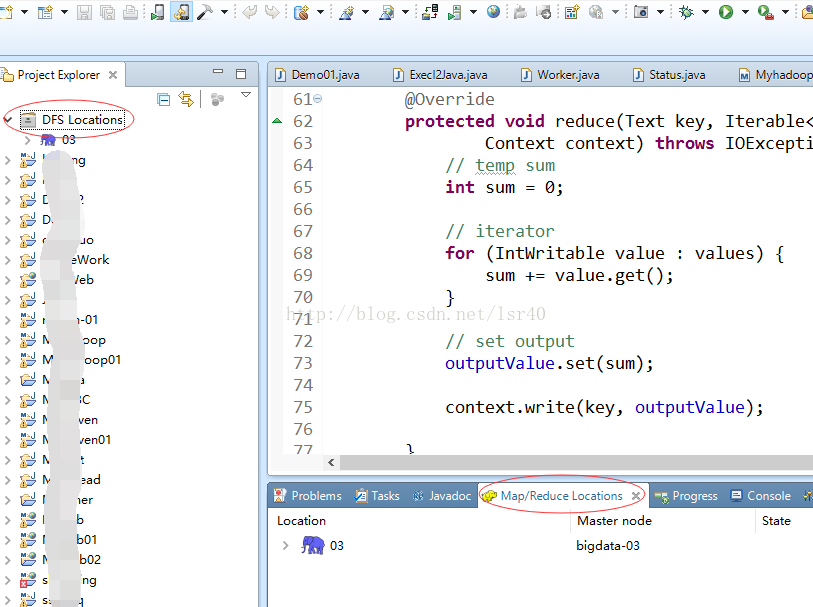
5、有了这个窗口之后,要配置hadoop(这个可以不用配置,不会影响运行)

5、接下来要让Myeclipse连接上我们的HDFS,所以要创建新的连接


6、然后连接(连接前,你肯定要开启你的namenode,并且确保他没问题)
如果这时候,你连接不上,那肯定是你的主机名,ip,映射啊这些没配置好,那就挺麻烦的了,你要重新配置好这些东西,然后重新格式化你的namenode(这里就不在具体说了)
7、好了,连接上了,要开始写代码了
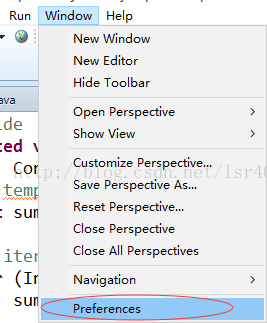
因为代码是用maven管理jar包的,所以还要配置maven
打开eclipse --> Window --> 点击Preference


8、到这里,恶心的配置已经都配置完了,然后可以创建maven project(quick start)来写代码
好,接下来说报错!
首先,贴个自己写的简单代码出来:
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Shell;
public class MyMapReduce {
// 1.自己的map静态类
// 集成Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> 输入的key,输入的value,输出的key,输出的value
public static class MyMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
// 1)、 创建一个IntWritable 类型的对象,给定值为1
IntWritable iw = new IntWritable(1);
Text keystr = new Text();
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
// 2)、 传入每一个map方法的key和value做打印
System.out.println("key : " + key.get() + "---------- value : " + line);
String[] strs = line.split(" ");
for (String str : strs) {
keystr.set(str);
System.out.println("map 的输出 = key : ( " + str + ",1 )" );
context.write(keystr, iw);
}
/*StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
keystr.set(itr.nextToken());
context.write(keystr, iw);
}*/
}
}
// 2.自己的静态reduce类
// reduce类的输入,其实是map类中的map方法的输出 输入key,输出value, 输出key,输出value
public static class MyReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
IntWritable countWritable = new IntWritable();
//Map类的map方法的数据输入到Reduce类的group方法中,再到<text,it(1,1)>,再将这个数据输入到Reduce类的reduce方法中
@Override
protected void reduce(Text inputkey, Iterable<IntWritable> inputvalue,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 1).得到key
String key = inputkey.toString();
// 2).迭代Iterable,把每个值相加
int count = 0;
// 3).循环遍历迭代器中的所有值,做相加
for (IntWritable intWritable : inputvalue) {
count += intWritable.get();
}
// 4). 把值设置到IntWritable ,等待输出
countWritable.set(count);
System.out.println("reduce输出结果 : key = " + key + " , " + count);
context.write(inputkey, countWritable);
}
}
// 3.运行类:run方法
/**
*
* @param args
* @return
* @throws Exception
*/
public int run(String[] args) throws Exception {
//hadoop的配置的上下文
Configuration configuration = new Configuration();
//通过上下文,构建一个job实例并且传入任务名称,单例模式
Job job = Job.getInstance(configuration, this.getClass().getSimpleName());
//必须添加,否则本地运行出现问题,服务器上运行会报错
job.setJarByClass(MyMapReduce.class);
// set job 设置任务从哪里读取数据
// input 调用这个方法的时候,要往args中传入参数,第一个位置上要传入从哪里读取数据
Path inpath = new Path(args[0]);
FileInputFormat.addInputPath(job, inpath);
// output 设置任务结果数据保存到哪里
//调用这个方法的时候,要往args中传入参数,第二个位置要传入的结果数据保存到哪里
Path outPath = new Path(args[1]);
FileOutputFormat.setOutputPath(job, outPath);
// Mapper 设置 Mapper类的参数
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// Reducer 设置 Reducer类的参数
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// submit job -> YARN
boolean isSuccess = job.waitForCompletion(true);
return isSuccess ? 0 : 1;
}
public static void main(String[] args) throws Exception {
args = new String[] {
"hdfs://192.168.211.211:8020/test2.txt",
"hdfs://192.168.211.211:8020/test2" };
// run job
int status = new MyMapReduce().run(args);
System.exit(status);
}
}这样,再上传个文件到hdfs(bin/hdfs dfs -put test2.txt /) 切记必须上传到hdfs,然后运行!
常见问题:
第一种类型、出现各种空指针:例如:Exception in thread "main" java.lang.NullPointerException atjava.lang.ProcessBuilder.start(Unknown Source)
An internal error occurred during: "Map/Reducelocation status updater".java.lang.NullPointerException
如果出现这样的问题,就是上文的配置你没配置好,好好检查下!!!!然后在hdfs上创建目录,上传文件试试,如果配置好了,应该不会有这样的问题
第二种类型、需要修改源码型:
1、Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
一开始看到这样的报错,我是拒绝的!!这里其实是因为在Windows下面运行mr代码必须有个文件叫做winutil.exe,默认解压的hadoop的bin目录下是没有的,自己下载一个然后放到hadoop目录的bin当中,程序会根据HADOOP_HOME找到bin目录下面的winutil.exe,但是有时候其实你都配置好了,它还报这个错,我就想打爆他的狗头,这时候就要修改源码了(看看源码是哪里获取的,你去手动写一个你正确的路径)
那么到底在源码的哪里呢?
在hadoop-common-2.7.6.jar这个jar包当中的org.apache.hadoop.util.Shell这个类里面

就是这个属性,修改下!!那怎么改,有个很简单的方法,Ctrl+A(全选),然后Ctrl+C(复制),把整个类复制下来,然后看下图!

点击画红圈的地方,Ctrl+V粘贴进去,他会自动生成想源码那样的包,然后直接改这个生成的java类,把377行改成:

2、Exception in thread "main"java.lang.UnsatisfiedLinkError:org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
还有这个几乎所有人都会遇到的问题,这个其实就是检查你的文件系统的时候报的错
我在我的另一个帖子里有说怎么修改,就是那个
Hbase在 Windows下运行报错 IllegalArgumentException:
Pathname /D:/download/repository/org/apache/.....
地址:http://blog.csdn.net/lsr40/article/details/77648012
要修改源码差不多也就这两个地方,如果还有别的,请大家在本帖的评论区留言,我研究下~谢谢
第三种类型、修改配置文件
1、
org.apache.hadoop.security.AccessControlException:
Permissiondenied: user=test, access=WRITE,inode="/user/root/output":root:supergroup:drwxr-xr-x
这里的问题是权限问题!
两种解决方法:
第一:使用命令 bin/hdfs dfs -chmod -R 777 / 这个就是将HDFS上面的所有目录都给777的权限,所有人都可以访问
第二:etc/hadoop下的hdfs-site.xml添加
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
然后重启hadoop,在运行应该就没问题了
2、报这个错误

添加日志文件,要到linux系统下的hdoop-2.7.6 --> etc --> hadoop下,把 log4j复制到eclipse里,在eclipse创建一个source Folder 文件夹,
把日志文件放进去


3、
Error: java.lang.RuntimeException: java.lang.ClassNotFoundException:
Class com.ibeifeng.cm.MapReduce$WordMap not found
- <span style="white-space:pre;">Error: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class com.ibeifeng.cm.MapReduce$WordMap not found
- at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:1905)
- at org.apache.hadoop.mapreduce.task.JobContextImpl.getMapperClass(JobContextImpl.java:186)
- at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:722)
- at org.apache.hadoop.mapred.MapTask.run(MapTask.java:340)
- at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:168)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:422)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614)
- at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:163)
- Caused by: java.lang.ClassNotFoundException: Class com.ibeifeng.cm.MapReduce$WordMap not found
- at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:1811)
- at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:1903)
- ... 8 more</span>
这个报错其实很坑的,检查了好久,看不出来,最后终于找到:
因为新建项目的时候,其实有这个,请看下图:

请注意:这里只能添加这3个,如果把yarn-site.xml也copy进来,那样你运行的时候,就会报如上的错误,因为你在mapred-site.xml当中指定了job运行于yarn,(其实你在本地运行的时候,应该是local模式的)你运行的时候,程序去yarn上面找对应的jar,class等信息,结果没找到所以。。。
两种解决方法:
1、把你src/main/resource中,mapred-site.xml这个yarn的值,改成local,就是下图的这个属性!!

2、把yarn-site.xml和mapred-site.xml这两个配置文件从src/main/resource中删除!就不会报这个错误了!!
这是我参考 https://blog.csdn.net/lsr40/article/details/77868113 点击打开链接做的,希望有些帮助