一、前言
1.什么是ORM?
转载的大佬链接,感谢大佬,转载只为学习
https://www.cnblogs.com/slfenng/p/7880734.htmlORM,即Object-Relational Mapping(对象关系映射),它的作用是在关系型数据库和业务实体对象之间作一个映射,这样,我们在具体的操作业务对象的时候,就不需要再去和复杂的SQL语句打交道,只需简单的操作对象的属性和方法。
2.ORM的优缺点是什么?
优点:摆脱复杂的SQL操作,适应快速开发;让数据结构变得简洁;数据库迁移成本更低(如从mysql->oracle)
缺点:性能较差、不适用于大型应用;复杂的SQL操作还需通过SQL语句实现
映射关系:
表名 <-------> 类名字段 <-------> 属性
表记录 <------->类实例对象
ORM有3种关联关系,分别为One-to-One(一对一),Many-to-Many(多对多),One-to-Many(一对多,也被称为外键)
主要区别:
一对一:子表从母表中选出一条数据一一对应,母表中选出来一条就少一条,子表不可以再选择母表中已被选择的那条数据
一对多:子表从母表中选出一条数据一一对应,但母表的这条数据还可以被其他子表数据选择
共同点是在admin中添加数据的话,都会出现一个select选框,但只能单选,因为不论一对一还是一对多,自己都是“一”
多对多:如很多公司,一台服务器可能会有多种用途,归属于多个产品线当中,那么服务器与产品线之间就可以做成对多对,多对多在A表添加manytomany字段或者从B表添加,效果一致
二、创建模型(创建表)
实例:我们来假定下面这些概念,字段和关系
作者模型:一个作者有姓名和年龄。
作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息。作者详情模型和作者模型之间是一对一的关系(one-to-one)
出版商模型:出版商有名称,所在城市以及email。
书籍模型: 书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many);一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many)。
模型建立如下:

class Author(models.Model): nid = models.AutoField(primary_key=True) name=models.CharField( max_length=32) age=models.IntegerField()# 与AuthorDetail建立一对一的关系 authorDetail</span>=models.OneToOneField(to=<span style="color: #800000">"</span><span style="color: #800000">AuthorDetail</span><span style="color: #800000">"</span><span style="color: #000000">)
class AuthorDetail(models.Model):
nid </span>= models.AutoField(primary_key=<span style="color: #000000">True)
birthday</span>=<span style="color: #000000">models.DateField()
telephone</span>=<span style="color: #000000">models.BigIntegerField()
addr</span>=models.CharField( max_length=<span style="color: #800080">64</span><span style="color: #000000">)
class Publish(models.Model):
nid = models.AutoField(primary_key=True)
name=models.CharField( max_length=32)
city=models.CharField( max_length=32)
email=models.EmailField()
class Book(models.Model):
nid </span>= models.AutoField(primary_key=<span style="color: #000000">True)
title </span>= models.CharField( max_length=<span style="color: #800080">32</span><span style="color: #000000">)
publishDate</span>=<span style="color: #000000">models.DateField()
price</span>=models.DecimalField(max_digits=<span style="color: #800080">5</span>,decimal_places=<span style="color: #800080">2</span><span style="color: #000000">)
keepNum</span>=models.IntegerField()<br> commentNum=<span style="color: #000000">models.IntegerField()
# 与Publish建立一对多的关系,外键字段建立在多的一方
publish</span>=models.ForeignKey(to=<span style="color: #800000">"</span><span style="color: #800000">Publish</span><span style="color: #800000">"</span>,to_field=<span style="color: #800000">"</span><span style="color: #800000">nid</span><span style="color: #800000">"</span><span style="color: #000000">)
# 与Author表建立多对多的关系,ManyToManyField可以建在两个模型中的任意一个,自动创建第三张表
authors</span>=models.ManyToManyField(to=<span style="color: #800000">'</span><span style="color: #800000">Author</span><span style="color: #800000">'</span>) </pre>
通过logging可以查看翻译成的sql语句
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
注意事项:
1、 表的名称myapp_modelName,是根据 模型中的元数据自动生成的,也可以覆写为别的名称
2、id 字段是自动添加的
3、对于外键字段,Django 会在字段名上添加"_id" 来创建数据库中的列名
4、这个例子中的CREATE TABLE SQL 语句使用PostgreSQL 语法格式,要注意的是Django 会根据settings 中指定的数据库类型来使用相应的SQL 语句。
5、定义好模型之后,你需要告诉Django _使用_这些模型。你要做的就是修改配置文件中的INSTALL_APPSZ中设置,在其中添加models.py所在应用的名称。
6、外键字段 ForeignKey 有一个 null=True 的设置(它允许外键接受空值 NULL),你可以赋给它空值 None 。
三、增删查改
3.1增加表记录
(1) 普通字段
方式1 publish_obj=Publish(name="人民出版社",city="北京",email="[email protected]") publish_obj.save() # 将数据保存到数据库 1 2 方式2 <br>返回值publish_obj是添加的记录对象 publish_obj=Publish.objects.create(name="人民出版社",city="北京",email="[email protected]")<br><br>方式3<br>表.objects.create(**request.POST.dict())
(2)外键字段
方式1:
publish_obj=Publish.objects.get(nid=1)
Book.objects.create(title="金瓶眉",publishDate="2012-12-12",price=665,pageNum=334,publish=publish_obj)
方式2:
Book.objects.create(title=“金瓶眉”,publishDate=“2012-12-12”,price=665,pageNum=334,publish_id=1)
(3)多对多字段
book_obj=Book.objects.create(title="追风筝的人",publishDate="2012-11-12",price=69,pageNum=314,publish_id=1)
author_yuan=Author.objects.create(name=“yuan”,age=23,authorDetail_id=1)
author_egon=Author.objects.create(name=“egon”,age=32,authorDetail_id=2)
book_obj.authors.add(author_egon,author_yuan) # 将某个特定的 model 对象添加到被关联对象集合中。 ======= book_obj.authors.add(*[])
book_obj.authors.create() #创建并保存一个新对象,然后将这个对象加被关联对象的集合中,然后返回这个新对象。
解除关系:
|
1
2
|
book_obj.authors.remove()
# 将某个特定的对象从被关联对象集合中去除。 ====== book_obj.authors.remove(*[])
book_obj.authors.clear()
#清空被关联对象集合。
|
把指定的模型对象添加到关联对象集中。
例如:
>>> b = Blog.objects.get(id=1)
>>> e = Entry.objects.get(id=234)
>>> b.entry_set.add(e) # Associates Entry e with Blog b.
在上面的例子中,对于ForeignKey关系,e.save()由关联管理器调用,执行更新操作。然而,在多对多关系中使用add()并不会调用任何 save()方法,而是由QuerySet.bulk_create()创建关系。
延伸:
1 *[]的使用
>>> book_obj = Book.objects.get(id=1)
>>> author_list = Author.objects.filter(id__gt=2)
>>> book_obj.authors.add(*author_list)
2 直接绑定主键
book_obj.authors.add(*[1,3]) # 将id=1和id=3的作者对象添加到这本书的作者集合中
# 应用: 添加或者编辑时,提交作者信息时可以用到.
create(**kwargs)
创建一个新的对象,保存对象,并将它添加到关联对象集之中。返回新创建的对象:
>>> b = Blog.objects.get(id=1)
>>> e = b.entry_set.create(
… headline=‘Hello’,
… body_text=‘Hi’,
… pub_date=datetime.date(2005, 1, 1)
… )
No need to call e.save() at this point – it’s already been saved.
这完全等价于(不过更加简洁于):
>>> b = Blog.objects.get(id=1)
>>> e = Entry(
… blog=b,
… headline=‘Hello’,
… body_text=‘Hi’,
… pub_date=datetime.date(2005, 1, 1)
… )
>>> e.save(force_insert=True)
要注意我们并不需要指定模型中用于定义关系的关键词参数。在上面的例子中,我们并没有传入blog参数给create()。Django会明白新的 Entry对象blog 应该添加到b中。
remove(obj1[, obj2, ...])
从关联对象集中移除执行的模型对象:
>>> b = Blog.objects.get(id=1)
>>> e = Entry.objects.get(id=234)
>>> b.entry_set.remove(e) # Disassociates Entry e from Blog b.
对于ForeignKey对象,这个方法仅在null=True时存在。
clear()
从关联对象集中移除一切对象。
>>> b = Blog.objects.get(id=1)
>>> b.entry_set.clear()
注意这样不会删除对象 —— 只会删除他们之间的关联。
就像 remove() 方法一样,clear()只能在 null=True的ForeignKey上被调用。
set()方法
先清空,在设置,编辑书籍时即可用到
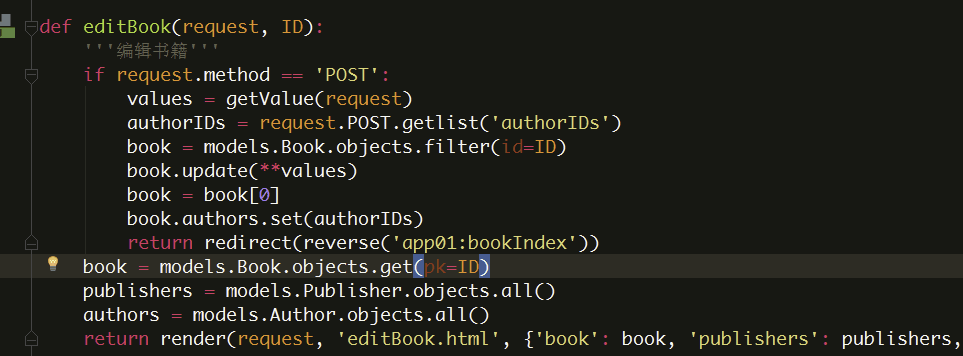
注意
对于所有类型的关联字段,add()、create()、remove()和clear(),set()都会马上更新数据库。换句话说,在关联的任何一端,都不需要再调用save()方法。
直接赋值:
通过赋值一个新的可迭代的对象,关联对象集可以被整体替换掉。
|
1
2
|
>>> new_list
=
[obj1, obj2, obj3]
>>> e.related_set
=
new_list
|
如果外键关系满足null=True,关联管理器会在添加new_list中的内容之前,首先调用clear()方法来解除关联集中一切已存在对象的关联。否则, new_list中的对象会在已存在的关联的基础上被添加。
3.2 查询表记录
查询相关API
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
<
1
>
all
(): 查询所有结果
<
2
>
filter
(
*
*
kwargs): 它包含了与所给筛选条件相匹配的对象
<
3
> get(
*
*
kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,
如果符合筛选条件的对象超过一个或者没有都会抛出错误。
<
5
> exclude(
*
*
kwargs): 它包含了与所给筛选条件不匹配的对象
<
4
> values(
*
field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列
model的实例化对象,而是一个可迭代的字典序列
<
9
> values_list(
*
field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
<
6
> order_by(
*
field): 对查询结果排序
<
7
> reverse(): 对查询结果反向排序
<
8
> distinct(): 从返回结果中剔除重复纪录
<
10
> count(): 返回数据库中匹配查询(QuerySet)的对象数量。
<
11
> first(): 返回第一条记录
<
12
> last(): 返回最后一条记录
<
13
> exists(): 如果QuerySet包含数据,就返回
True
,否则返回
False
|
注意:一定区分object与querySet的区别 !!!
双下划线之单表查询
|
1
2
3
4
5
6
7
8
9
10
11
|
models.Tb1.objects.
filter
(id__lt
=
10
, id__gt
=
1
)
# 获取id大于1 且 小于10的值
models.Tb1.objects.
filter
(id__in
=
[
11
,
22
,
33
])
# 获取id等于11、22、33的数据
models.Tb1.objects.exclude(id__in
=
[
11
,
22
,
33
])
# not in
models.Tb1.objects.
filter
(name__contains
=
"ven"
)
models.Tb1.objects.
filter
(name__icontains
=
"ven"
)
# icontains大小写不敏感
models.Tb1.objects.
filter
(id__range
=
[
1
,
2
])
# 范围bettwen and
startswith,istartswith, endswith, iendswith
|
基于对象的跨表查询
一对多查询(Publish 与 Book)
正向查询(按字段:publish):
|
1
2
|
# 查询nid=1的书籍的出版社所在的城市<br>
book_obj
=
Book.objects.get(nid
=
1
)<br>
print
(book_obj.publish.city)
# book_obj.publish 是nid=1的书籍对象关联的出版社对象
|
反向查询(按表名:book_set):
|
1
2
3
4
5
6
7
8
|
# 查询 人民出版社出版过的所有书籍
publish
=
Publish.objects.get(name
=
"人民出版社"
)
book_list
=
publish.book_set.
all
()
# 与人民出版社关联的所有书籍对象集合
for
book_obj in book_list:
print
(book_obj.title)
|
一对一查询(Author 与 AuthorDetail)
正向查询(按字段:authorDetail):
|
1
2
3
4
|
# 查询egon作者的手机号
author_egon
=
Author.objects.get(name
=
"egon"
)
print
(author_egon.authorDetail.telephone)
|
反向查询(按表名:author):
|
1
2
3
4
5
6
|
# 查询所有住址在北京的作者的姓名
authorDetail_list
=
AuthorDetail.objects.
filter
(addr
=
"beijing"
)
for
obj in authorDetail_list:
print
(obj.author.name)
|
多对多查询 (Author 与 Book)
正向查询(按字段:authors):
|
1
2
3
4
5
6
7
8
9
|
# 金瓶眉所有作者的名字以及手机号
book_obj
=
Book.objects.
filter
(title
=
"金瓶眉"
).first()
authors
=
book_obj.authors.
all
()
for
author_obj in authors:
print
(author_obj.name,author_obj.authorDetail.telephone)
|
反向查询(按表名:book_set):
|
1
2
3
4
5
6
7
|
# 查询egon出过的所有书籍的名字
author_obj
=
Author.objects.get(name
=
"egon"
)
book_list
=
author_obj.book_set.
all
()
#与egon作者相关的所有书籍
for
book_obj in book_list:
print
(book_obj.title)
|
注意:
你可以通过在 ForeignKey() 和ManyToManyField的定义中设置 related_name 的值来覆写 FOO_set 的名称。例如,如果 Article model 中做一下更改: publish = ForeignKey(Blog, related_name='bookList'),那么接下来就会如我们看到这般:
|
1
2
3
4
5
|
# 查询 人民出版社出版过的所有书籍
publish
=
Publish.objects.get(name
=
"人民出版社"
)
book_list
=
publish.bookList.
all
()
# 与人民出版社关联的所有书籍对象集合
|
基于双下划线的跨表查询
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的 model 为止。
关键点:正向查询按字段,反向查询按表明。
# 练习1: 查询人民出版社出版过的所有书籍的名字与价格(一对多)# 正向查询 按字段:publish queryResult=Book.objects<br> .filter(publish__name="人民出版社")<br> .values_list("title","price") # 反向查询 按表名:book queryResult=Publish.objects<br> .filter(name="人民出版社")<br> .values_list("book__title","book__price")
练习2: 查询egon出过的所有书籍的名字(多对多)
# 正向查询 按字段:authors:
queryResult=Book.objects<br> .filter(authors__name="yuan")<br> .values_list("title")
# 反向查询 按表名:book
queryResult=Author.objects<br> .filter(name="yuan")<br> .values_list("book__title","book__price")
练习3: 查询人民出版社出版过的所有书籍的名字以及作者的姓名
# 正向查询
queryResult=Book.objects<br> .filter(publish__name="人民出版社")<br> .values_list("title","authors__name")
# 反向查询
queryResult=Publish.objects<br> .filter(name="人民出版社")<br> .values_list("book__title","book__authors__age","book__authors__name")
练习4: 手机号以151开头的作者出版过的所有书籍名称以及出版社名称
queryResult=Book.objects<br> .filter(authors__authorDetail__telephone__regex="151")<br> .values_list("title","publish__name")</pre>
查询实例
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
|
ORM跨表查询(
1
基于对象
2
基于双下划线)
#####基于对象的跨表查询
###########################################一对多查询########################
# 正向查询: 按字段
# 查询 python这本书的出版社的名称和地址
# book_python=models.Book.objects.filter(title="python").first()
#
# print(book_python.title)
# print(book_python.price)
#
# print(book_python.publisher) # Publish object : 与这本书关联的出版社的对象
# print(book_python.publisher.name)
# print(book_python.publisher.addr)
# 反向查询:按关联的表名(小写)_set
# 查询人民出版社出版过的所有书籍名称及价格
# pub_obj=models.Publish.objects.get(name="renmin")
# book_list=pub_obj.book_set.all() # QuerySet 与这个出版社关联的所有书籍对象
#
# for obj in book_list:
# print(obj.title,obj.price)
###########################################一对一查询########################
# 正向查询: 按字段
# 查询addr在沙河的作者
authorDetail
=
models.AuthorDetail.objects.get(addr
=
"shahe"
)
print
(authorDetail.author.name)
# alex
# 反向查询:按 表名(小写)
# 查询 alex混迹在哪里
alex
=
models.Author.objects.get(name
=
"alex"
)
print
(alex.authordetail.addr)
# shahe
###########################################多对多查询########################
# 多对多的正向 查询: 按字段
# 查询 python这本书的所有作者的姓名和年龄
# book_python=models.Book.objects.get(title="python")
# author_list=book_python.authors.all()
# for obj in author_list:
# print(obj.name,obj.age)
#
# book_pythons = models.Book.objects.filter(title="python")
# for book_python in book_pythons:
# author_list = book_python.authors.all()
# for obj in author_list:
# print(obj.name, obj.age)
# 多对多的反向查询 按关联的表名(小写)_set
# alex出版过的所有书籍的明显名称
# alex=models.Author.objects.get(name="alex")
# book_list=alex.book_set.all()
# for i in book_list:
# print(i.title,i.price)
#####基于双下划线的跨表查询
JS:
var eles_p
=
document.getElementByTagName(
"p"
); [p1,p2,p3,p4,p5]
for
(var i
=
0
;i<eles_p.length;i
+
+
){
eles_p[i].style.color
=
"red"
}
jquery:
$(
"p"
).css(
"color"
,
"red"
)
正向查询:按字段
反向查询:按表明
# 查询 python这本书的价格
ret
=
models.Book.objects.
filter
(title
=
"python"
).values(
"price"
,
"title"
)
print
(ret)
# <QuerySet [{'price': Decimal('122.00')}]>
#查询python这本书的出版社的名称和地址
# 正向查询 按字段 基于book表
# ret2=models.Book.objects.filter(title="python").values_list("publisher__name")
# print(ret2)
#
# # 反向查询 按表名 if 设置了related_name: 按设置值
# ret3=models.Publish.objects.filter(bookList__price=333).values_list("name","addr").distinct()
# print(ret3)
# 查询人民出版社出版过的所有书籍名称及价格
# ret4=models.Book.objects.filter(publisher__name="renmin").values("title","price")
# print(ret4.count())
# ret5=models.Publish.objects.filter(name="renmin").values("bookList__title","bookList__price")
# print(ret5.count())
#查询egon出过的所有书籍的名字(多对多)
# ret6=models.Author.objects.filter(name="egon").values_list("book__title")
# print(ret6)
# ret7=models.Book.objects.filter(authors__name__contains="eg").values("title")
# print(ret7)
# 地址以沙河开头的的作者出版过的所有书籍名称以及出版社名称
# ret8=models.Book.objects.filter(authors__authordetail__addr__startswith="sha").values("title","publisher__name")
# print(ret8)
sql与ORM:
SELECT `app01_publish`.`name`
FROM `app01_book`
INNER JOIN `app01_publish`
ON (`app01_book`.`publisher_id`
=
`app01_publish`.`
id
`)
WHERE `app01_book`.`title`
=
'python'
LIMIT
21
;
SELECT `app01_publish`.`name`
FROM `app01_publish` INNER JOIN `app01_book`
ON (`app01_publish`.`
id
`
=
`app01_book`.`publisher_id`)
WHERE `app01_book`.`title`
=
'python'
LIMIT
21
;
|
注意:
反向查询时,如果定义了related_name ,则用related_name替换表名,例如: publish = ForeignKey(Blog, related_name='bookList'):
|
1
2
3
4
5
6
7
|
# 练习1: 查询人民出版社出版过的所有书籍的名字与价格(一对多)
# 反向查询 不再按表名:book,而是related_name:bookList
queryResult
=
Publish.objects
.
filter
(name
=
"人民出版社"
)
.values_list(
"bookList__title"
,
"bookList__price"
)
|
聚合查询与分组查询
先了解sql中的聚合与分组概念
聚合:aggregate(*args, **kwargs)
|
1
2
3
4
|
# 计算所有图书的平均价格
>>>
from
django.db.models import Avg
>>> Book.objects.
all
().aggregate(Avg(
'price'
))
{
'price__avg'
:
34.35
}
|
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
|
1
2
|
>>> Book.objects.aggregate(average_price
=
Avg(
'price'
))
{
'average_price'
:
34.35
}
|
如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。所以,如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
|
1
2
3
|
>>>
from
django.db.models import Avg, Max, Min
>>> Book.objects.aggregate(Avg(
'price'
),
Max
(
'price'
),
Min
(
'price'
))
{
'price__avg'
:
34.35
,
'price__max'
: Decimal(
'81.20'
),
'price__min'
: Decimal(
'12.99'
)}
|
分组:annotate()
为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数)。
(1) 练习:统计每一本书的作者个数
|
1
2
3
|
bookList
=
Book.objects.annotate(authorsNum
=
Count(
'authors'
))
for
book_obj in bookList:
print
(book_obj.title,book_obj.authorsNum)
|
F查询与Q查询
F查询
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
|
1
2
3
4
|
# 查询评论数大于收藏数的书籍
from
django.db.models import F
Book.objects.
filter
(commnetNum__lt
=
F(
'keepNum'
))
|
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
|
1
2
|
# 查询评论数大于收藏数2倍的书籍
Book.objects.
filter
(commnetNum__lt
=
F(
'keepNum'
)
*
2
)
|
修改操作也可以使用F函数,比如将每一本书的价格提高30元:
|
1
|
Book.objects.
all
().update(price
=
F(
"price"
)
+
30
)
|
Q查询
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
|
1
2
|
from
django.db.models import Q
Q(title__startswith
=
'Py'
)
|
Q 对象可以使用& 和| 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
|
1
|
bookList
=
Book.objects.
filter
(Q(authors__name
=
"yuan"
)|Q(authors__name
=
"egon"
))
|
等同于下面的SQL WHERE 子句:
|
1
|
WHERE name
=
"yuan"
OR name ="egon"
|
你可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询:
|
1
|
bookList
=
Book.objects.
filter
(Q(authors__name
=
"yuan"
) & ~Q(publishDate__year
=
2017
)).values_list(
"title"
)
|
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。例如:
bookList=Book.objects.filter(Q(publishDate__year=2016) | Q(publishDate__year=2017),
title__icontains="python"
)
3.3 修改表记录
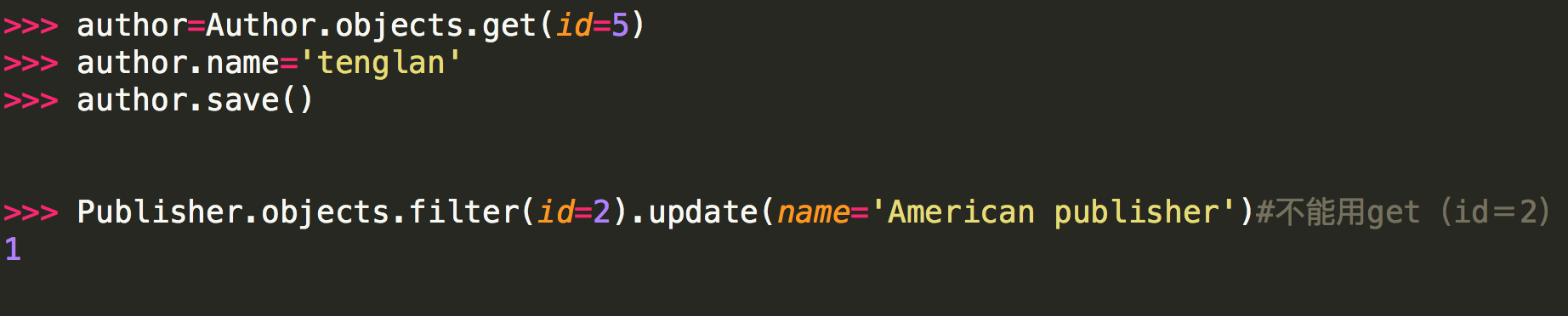
注意:
<1> 第二种方式修改不能用get的原因是:update是QuerySet对象的方法,get返回的是一个model对象,它没有update方法,而filter返回的是一个QuerySet对象(filter里面的条件可能有多个条件符合,比如name='alvin',可能有两个name='alvin'的行数据)。
<2>在“插入和更新数据”小节中,我们有提到模型的save()方法,这个方法会更新一行里的所有列。 而某些情况下,我们只需要更新行里的某几列。
此外,update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录update()方法会返回一个整型数值,表示受影响的记录条数。
注意,这里因为update返回的是一个整形,所以没法用query属性;对于每次创建一个对象,想显示对应的raw sql,需要在settings加上日志记录部分
3.4删除表记录
删除方法就是 delete()。它运行时立即删除对象而不返回任何值。例如:
|
1
|
e.delete()
|
你也可以一次性删除多个对象。每个 QuerySet 都有一个 delete() 方法,它一次性删除 QuerySet 中所有的对象。
例如,下面的代码将删除 pub_date 是2005年的 Entry 对象:
|
1
|
Entry.objects.
filter
(pub_date__year
=
2005
).delete()
|
要牢记这一点:无论在什么情况下,QuerySet 中的 delete() 方法都只使用一条 SQL 语句一次性删除所有对象,而并不是分别删除每个对象。如果你想使用在 model 中自定义的 delete() 方法,就要自行调用每个对象的delete 方法。(例如,遍历 QuerySet,在每个对象上调用 delete()方法),而不是使用 QuerySet 中的 delete()方法。
在 Django 删除对象时,会模仿 SQL 约束 ON DELETE CASCADE 的行为,换句话说,删除一个对象时也会删除与它相关联的外键对象。例如:
|
1
2
3
|
b
=
Blog.objects.get(pk=1)
# This will delete the Blog and all of its Entry objects.
b.delete()
|
要注意的是: delete() 方法是 QuerySet 上的方法,但并不适用于 Manager 本身。这是一种保护机制,是为了避免意外地调用 Entry.objects.delete() 方法导致 所有的 记录被误删除。如果你确认要删除所有的对象,那么你必须显式地调用:
|
1
|
Entry.objects.
all
().delete()
|
如果不想级联删除,可以设置为:
pubHouse = models.ForeignKey(to='Publisher', on_delete=models.SET_NULL, blank=True, null=True)