目录
5.1.1 简单查询
select * from person; -- 查询所有
select name,SEX from person; -- 按指定字段查询
select name,SEX as'性别' from person; -- as 表示为字段起别名
select salary+200 from person; -- 可以进行数据列运算
select DISTINCT age,name FROM person; -- 去重复查询(必须全部一样才可以去重)5.5.2 条件查询
- 运算符 > < >= <= = <>(!=)
select * FROM person WHERE age >20;
select * FROM person WHERE age <=20;
select * FROM person WHERE age <>20;
select * FROM person WHERE age !=20;- null 关键字 is null , not null
select * FROM person where dept_id is null; 真的是空的
select * FROM person where dept_id is not null; 真的不是空的
select * FROM person where name =''; -- 字符串为空- 逻辑运算符 and or
select * from person where age = 28 and salary =53000;
select * from person where age = 23 or salary =2000;
select * from person where not(age = 28 and salary =53000);5.1.3 区间查询
关键字 between 10 and 20 :表示 获得10 到 20 区间的内容
select * from person where age BETWEEN 18 and 20;
ps: between...and 前后包含所指定的值
等价于 select * from person where salary >= 4000 and salary <= 8000; 5.1.4集合查询
select * from person where id = 1 or id = 3 or id = 5;
等价于:
select * from person where id not in(1,3,5); ##关键字in
5.1.5 模糊查询---用在搜索上
关键字 like , not like
%: 任意多个字符
_ : 只能是单个字符
select * from person where name like '%e%'; -- 包含指定参数
select * from person where name like '%e'; -- 以什么结尾
select * from person where name like 'e%'; -- 以什么开头
select * from person where name like '__'; -- _表示单个字符站位符
elect * from person where name like '__e%'; 5.1.6 排序查询 ORDER BY
排序查询格式:
select 字段|* from 表名 [where 条件过滤] [order by 字段[ASC][DESC]]升序: ASC 默认为升序
降序: DESC
PS:排序order by 要写在select语句末尾
select * from person where age >30 ORDER BY salary desc; -- ASC正序 DESC倒序-写在最后
select * from person ORDER BY CONVERT(name USING gbk);-- 中文排序 --因为中文不支持排序所以要换成gbk5.1.7 聚合函数
聚合: 将分散的聚集到一起.
聚合函数: 对列进行操作,返回的结果是一个单一的值,除了 COUNT 以外,都会忽略空值
COUNT:统计指定列不为NULL的记录行数;
SUM:计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
MAX:计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
MIN:计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
AVG:计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
-- 格式:
select 聚合函数(字段) from 表名;
-- 统计人员中最大年龄、最小年龄,平均年龄分别是多少
select max(age),min(age),avg(age) from person;5.1.7 分组查询
分组的含义: 将一些具有相同特征的数据 进行归类.比如:性别,部门,岗位等等
怎么区分什么时候需要分组呢?
套路: 遇到 "每" 字,一般需要进行分组操作.
例如: 1. 公司每个部门有多少人.
2. 公司中有 多少男员工 和 多少女员工.
分组查询格式:
select 被分组的字段 from 表名 group by 分组字段 [having 条件字段]
ps: 分组查询可以与 聚合函数 组合使用.栗子:
-- 查询每个部门的平均薪资
select avg(salary),dept from person GROUP BY dept;
-- 查询每个部门的平均薪资 并且看看这个部门的员工都有谁?
select avg(salary),dept,GROUP_CONCAT(name) from person GROUP BY dept;
#GROUP_CONCAT(expr):按照分组,将expr字符串按逗号分隔,组合起来
-- 查询平均薪资大于10000的部门, 并且看看这个部门的员工都有谁?
select avg(salary),dept,GROUP_CONCAT(name) from person GROUP BY dept; having avg(salary)>10000;where 与 having区别:
执行优先级从高到低:where > group by > having
1. Where 发生在分组group by之前,因而Where中可以有任意字段,但是绝对不能使用聚合函数。
2. Having发生在分组group by之后,因而Having中可以使用分组的字段,无法直接取到其他字段,可以使用聚合函数
5.1.7 分组查询
好处:限制查询数据条数,提高查询效率
-- 查询前5条数据
select * from person limit 5;
-- 查询第5条到第10条数据
select * from person limit 5,5;
-- 查询第10条到第15条数据
select * from person limit 10,5;
ps: limit (起始条数),(查询多少条数);5.1.8 正则表达式
5.1.9 SQL 语句关键字的执行顺序
栗子查询:姓名不同人员的最高工资,并且要求大于5000元,同时按最大工资进行排序并取出前5条.
select name, max(salary)
from person
where name is not null
group by name
having max(salary) > 5000
order by max(salary)
limit 0,5执行顺序:
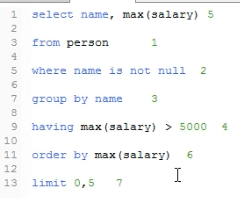
在上面的示例中 SQL 语句的执行顺序如下:
(1). 首先执行 FROM 子句, 从 person 表 组装数据源的数据
(2). 执行 WHERE 子句, 筛选 person 表中 name 不为 NULL 的数据
(3). 执行 GROUP BY 子句, 把 person 表按 "name" 列进行分组
(4). 计算 max() 聚集函数, 按 "工资" 求出工资中最大的一些数值
(5). 执行 HAVING 子句, 筛选工资大于 5000的人员.
(7). 执行 ORDER BY 子句, 把最后的结果按 "Max 工资" 进行排序.
(8). 最后执行 LIMIT 子句, . 进行分页查询
执行顺序: FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY ->limit