在上一篇博客中介绍了该项目的的需求分析以及先期的准备,今天就记录一下在树莓派上的开发过程,我从接触树莓派到完成项目也只是过了俩周的时间,肯定是没有把树莓派完全玩透的,遇到问题最好的方法还是去谷歌,如果中文不能解决就用英文描述一下一般就绝对能找到解答了,树莓派作为一个开源这么久的项目,已经有好多的开发者,所以说你遇到的大部分问题都能找到解答。
树莓派上的开发我分为个部分:Raspbian系统环境的搭建、OpenCV开发环境的搭建、树莓派摄像头的使用、人脸追踪、人脸识别、帧数的提高、与stm32的通信。
第一部分 Raspbian系统环境的搭建
这个我就不细讲了,网上资源多得很,制作启动sd卡然后开机安装就行了,这个不会遇到什么问题的。至于Raspbian,它是基于Debian的,而Debian又是Ubuntu的爹,所以说如果你会使用Ubuntu的话上手还是很简单的,如果没接触过Linux的话,最好去学习一些基本的命令和操作。
第二部分 OpenCV开发环境的搭建
OpenCV开发环境的搭建我真的觉得是这个项目中最费事的环节了,由于树莓派性能实在是不够强,所以说编译代码动辄就是七个小时以上,而我还失败了俩次,唉,说多了都是泪。
注意:应当首先把软件源修改一下,我一开始是中科大的源,按照如下步骤安装完成后是不能用的,但是换用清华大学的源以后安装完成后就正常了,也不知道是不是这个的原因,还是推荐大家使用清华大学的源,如何修改请自行百度。
步骤如下:
打开终端,进行更新和升级:
// 软件源更新
sudo apt-get update
// 升级本地所有安装包,最新系统可以不升级,版本过高反而需要降级才能安装
sudo apt-get upgrade
// 升级树莓派固件,固件比较新或者是Ubuntu则不用执行
sudo rpi-update
然后安装构建OpenCV的相关工具:
// 安装build-essential、cmake、git和pkg-config
sudo apt-get install build-essential cmake git pkg-config
安装常用图像工具包:
// 安装jpeg格式图像工具包
sudo apt-get install libjpeg8-dev
// 安装tif格式图像工具包
sudo apt-get install libtiff5-dev
// 安装JPEG-2000图像工具包
sudo apt-get install libjasper-dev
// 安装png图像工具包
sudo apt-get install libpng12-dev
安装视频IO包:
sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev
安装gtk2.0:
sudo apt-get install libgtk2.0-dev
优化函数包:
sudo apt-get install libatlas-base-dev gfortran
执行到这里就把OpenCV的依赖包全部安装好了,之后要开始编译OpenCV源代码了,请大家用wget工具下载到用户目录下(源码要放在有执行权限的位置,不是安装位置),命令如下:
/ 使用wget下载OpenCV源码,觉得慢的话可以到https://github.com/opencv/opencv/releases下载OpenCV的源代码
// tar.gz格式,需要解压好,放到用户目录下
// 但是OpenCV_contrib请大家使用wget,亲测直接到Github下载zip文件的话,会有编译问题
// 下载OpenCV
wget -O opencv-3.4.1.zip https://github.com/Itseez/opencv/archive/3.4.1.zip
// 解压OpenCV
unzip opencv-3.4.1.zip
// 下载OpenCV_contrib库:
wget -O opencv_contrib-3.4.1.zip https://github.com/Itseez/opencv_contrib/archive/3.4.1.zip
// 解压OpenCV_contrib库:
unzip opencv_contrib-3.4.1.zip
找到你下载的源码文件夹并打开,tar.gz解压后文件夹名应该是opencv-3.4.1(版本号可能会变化),git方式下载的文件夹名应该是opencv
// 打开源码文件夹,这里以我修改文章时最新的3.4.1为例
cd opencv-3.4.1
之后我们新建一个名为release的文件夹用来存放cmake编译时产生的临时文件:
// 新建release文件夹
mkdir release
// 进入release文件夹
cd release
设置cmake编译参数,安装目录默认为/usr/local ,注意参数名、等号和参数值之间不能有空格,但每行末尾“\”之前有空格,参数值最后是两个英文的点:
/** CMAKE_BUILD_TYPE是编译方式
* CMAKE_INSTALL_PREFIX是安装目录
* OPENCV_EXTRA_MODULES_PATH是加载额外模块
* INSTALL_PYTHON_EXAMPLES是安装官方python例程
* BUILD_EXAMPLES是编译例程(这两个可以不加,不加编译稍微快一点点,想要C语言的例程的话,在最后一行前加参数INSTALL_C_EXAMPLES=ON \)
**/
sudo cmake -D CMAKE_BUILD_TYPE=RELEASE \
-D CMAKE_INSTALL_PREFIX=/usr/local \
-D OPENCV_EXTRA_MODULES_PATH=~/opencv_contrib-3.4.1/modules \
-D INSTALL_PYTHON_EXAMPLES=ON \
-D BUILD_EXAMPLES=ON ..
之后开始正式编译过程(如果之前一步因为网络问题导致cmake下载缺失文件失败的话,可以尝试使用手机热点,并将release文件夹删除掉,重新创建release文件夹并cmake),编译的过程及其缓慢,耐心等待:
// 编译,以管理员身份,否则容易出错
sudo make
// 安装
sudo make install
// 更新动态链接库
sudo ldconfig
到这里,OpenCV的安装就完成了,借用别的博主的脚本来测试一下。
# -*- coding:utf-8 -*-
import cv2
import numpy as np
cv2.namedWindow("gray")
img = np.zeros((512,512),np.uint8)#生成一张空的灰度图像
cv2.line(img,(0,0),(511,511),255,5)#绘制一条白色直线
cv2.imshow("gray",img)#显示图像
#循环等待,按q键退出
while True:
key=cv2.waitKey(1)
if key==ord("q"):
break
cv2.destoryWindow("gray")
运行之后,显示的图片如下:

当你完成以上的步骤后,树莓派的OpenCV开发环境就配置完成了,切记不要着急失去耐心,慢慢来,遇到问题仔细排查去百度解决方案,如果正确操作应该不会出错,如果失败了就多试几次。
第三部分 树莓派摄像头的使用
树莓派的摄像头有俩种:USB接口和CSI接口,我这次使用的是CSI接口的摄像头,这种摄像头不用安装驱动,只要在BIOS里使能一下就可以。
配置过程:
打开终端,进入树莓派的BIOS(其实应该是配置界面,但是界面太像BIOS了):
sudo raspi-config
打开后如下图: 
选择第五项:Interfacing Options(接口选项)
打开后如下图:
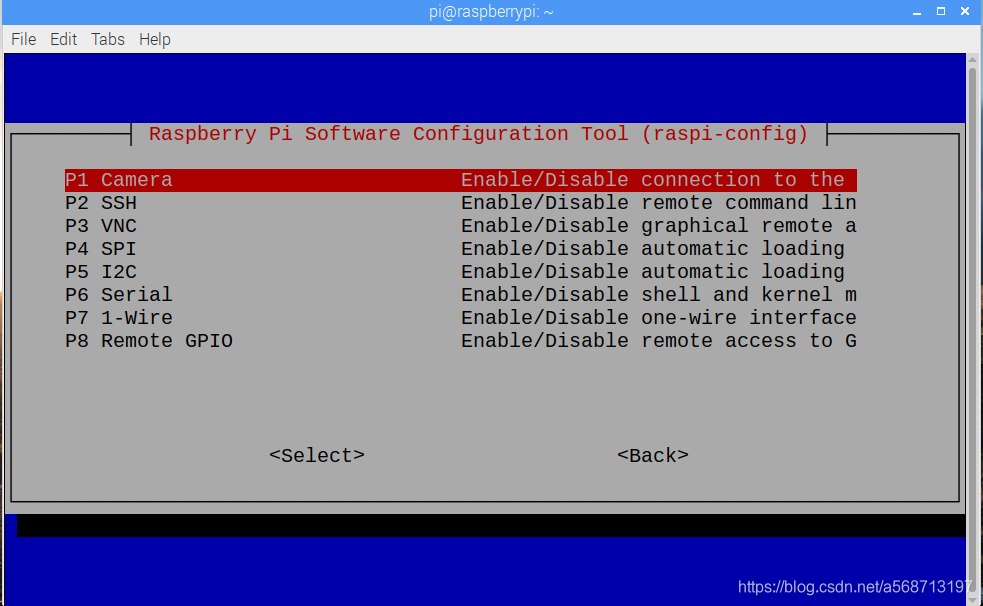
然后选择camera,使能,然后它会提醒你重启一下,重启以后就OK了。
注意:一定在断电的情况下接摄像头,要不及其容易被烧掉。
安装摄像头并重启以后就可以写一个脚本来测试摄像头了:
import picamera #摄像头库
import picamera.array
with picamera.PiCamera() as camera:
camera.resolution=(640,480) #设置图像尺寸
camera.framerate=30 #设置帧率
camera.rotation=180 #设置旋转角度,我这里翻转了180度
print('Start preview direct from GPU ')
camera.start_preview() #开始预览
while(1):
a=1
运行上面的脚本以后你就可以实时预览摄像头拍到的画面。
接下来我们测试一下在OpenCV中打开摄像头然后读图像、处理和显示。
编写以下的脚本:
# -*- coding: utf-8 -*-
import io
from time import sleep
import picamera
import numpy as np
import cv2
with picamera.PiCamera() as camera:
camera.resolution = (320, 240) #设置大小
camera.rotation=180 #旋转180度
cv2.namedWindow('frame') #新建窗口
cv2.namedWindow('gray')
sleep(1)
stream = io.BytesIO() #视频流输入
for foo in camera.capture_continuous(stream, format='jpeg', use_video_port=True):
data = np.fromstring(stream.getvalue(), dtype=np.uint8)
image = cv2.imdecode(data, cv2.IMREAD_COLOR) #获取RGB图像
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY) #RGB转GRAY灰度图
cv2.imshow("frame", image) #显示图像
cv2.imshow("gray",gray)
cv2.waitKey(1) #等待按下键盘
stream.truncate() #中断视频流
stream.seek(0)
运行后的效果如下图:
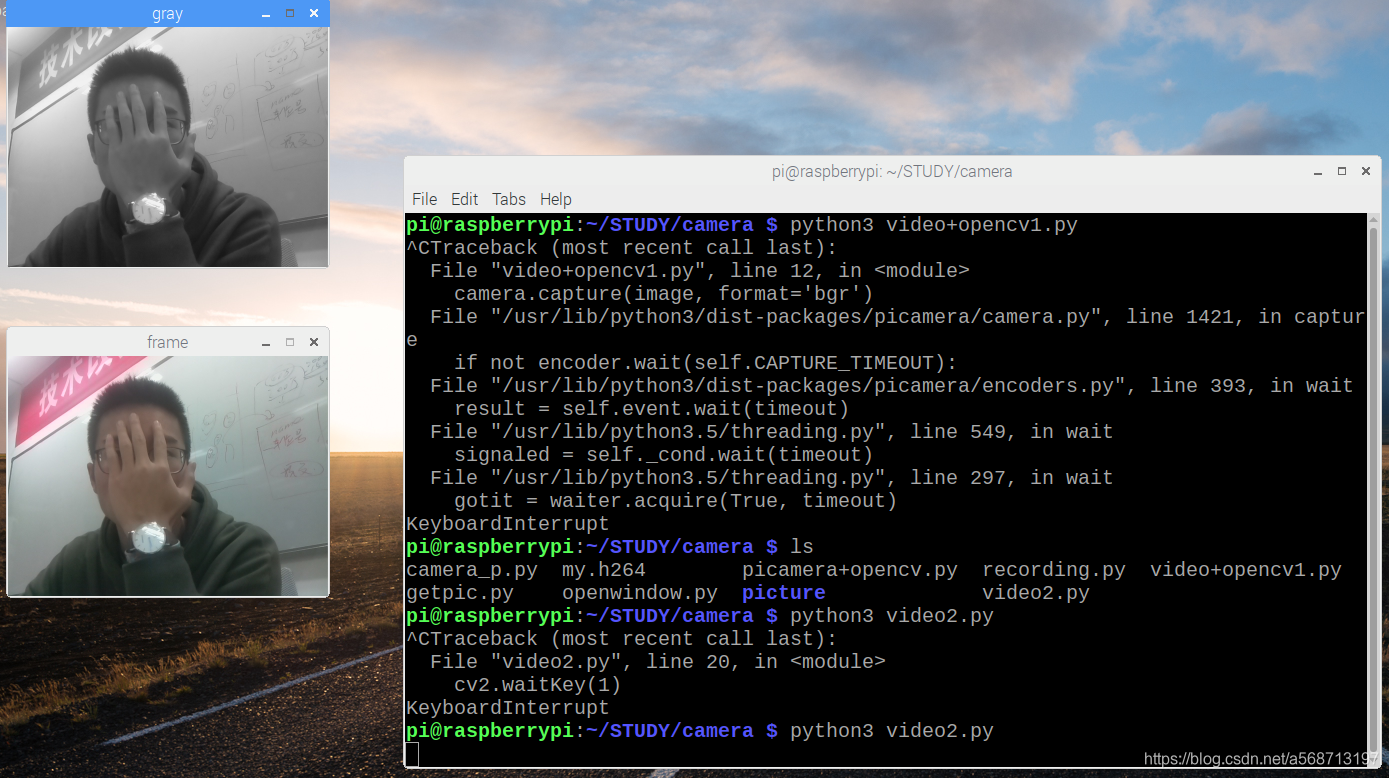
到这里我们就完成了树莓派摄像头的配置,并且也能把视频和图像给到OpenCV进行处理和显示。
第四部分 人脸追踪
关于OpenCV上的人脸追踪和人脸识别算法,我了解的并不是十分透彻,只能给大家说说这些算法是怎么使用的,具体的底层的原理我也不能完整表述。
人脸识别的最基础任务是人脸检测。你必须首先捕捉人脸才能在未来与捕捉到的新人脸对比时识别它。
最常见的人脸检测方式是使用Haar 级联分类器。使用基于 Haar 特征的级联分类器的目标检测是 Paul Viola 和 Michael Jones 2001 年在论文《Rapid Object Detection using a Boosted Cascade of Simple Features》中提出的一种高效目标检测方法。这种机器学习方法基于大量正面、负面图像训练级联函数,然后用于检测其他图像中的对象。这里,我们将用它进行人脸识别。最初,该算法需要大量正类图像(人脸图像)和负类图像(不带人脸的图像)来训练分类器。然后我们需要从中提取特征。好消息是 OpenCV 具备训练器和检测器。如果你想要训练自己的对象分类器,如汽车、飞机等,你可以使用 OpenCV 创建一个。
当然OpenCV给我们提供了常用的一些对象分类器,进入到/opencv-3.4.1/data/haarcascades文件夹下面你就能看到已有的一些对象分类器,如下图所示:

其中一些什么全身、脸、左右眼、笑脸、上半身等等的分类器都有,你可以复制一个到你的代码文件夹,然后开始编写识别脚本。下面的代码是人脸检测的脚本,如果要检测别的可以自行修改:
import numpy as np
import cv2
#Cascades存放分类器的文件夹
#引入分类器
faceCascade = cv2.CascadeClassifier('Cascades/haarcascade_frontalface_default.xml')
#捕获图像
cap = cv2.VideoCapture(0)
cap.set(3,640) # set Width
cap.set(4,480) # set Height
while True:
ret, img = cap.read()
img = cv2.flip(img, -1)#翻转图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)#转换到灰度图(人脸识别和检测都是在灰度图下进行的)
faces = faceCascade.detectMultiScale(
gray, #图像
scaleFactor=1.2, #图片缩小的比例
minNeighbors=5, #每次检测时,对检测点(Scale)周边多少有效点同时检测,类似于卷积算子吧
minSize=(20, 20) #人脸的最小范围,如果比20*20像素小忽略
)
#x,y,w,,h为得到的人脸的数据
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)#框脸
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
cv2.imshow('video',img) #显示
k = cv2.waitKey(30) & 0xff
if k == 27: # press 'ESC' to quit
break
cap.release()
cv2.destroyAllWindows()
运行后的图像如下图:

太阳是给自己打的码啦~
现在我们就完成了人脸的检测。
第五部分 人脸识别
人脸的识别分为三个步骤,收集人脸数据、训练、识别。所以说我们需要三个脚本来完成这些任务。
1、收集人脸数据,我们运行一个脚本连续拍照50张,然后将图片存到一个文件夹中,脚本如下:
import cv2
import os
cam = cv2.VideoCapture(0)
cam.set(3, 640) # set video width
cam.set(4, 480) # set video height
face_detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# For each person, enter one numeric face id
face_id = input('\n enter user id end press <return> ==> ')
print("\n [INFO] Initializing face capture. Look the camera and wait ...")
# Initialize individual sampling face count
count = 0
while(True):
ret, img = cam.read()
img = cv2.flip(img, -1) # flip video image vertically
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_detector.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
cv2.rectangle(img, (x,y), (x+w,y+h), (255,0,0), 2)
count += 1
# Save the captured image into the datasets folder
cv2.imwrite("dataset/User." + str(face_id) + '.' + str(count) + ".jpg", gray[y:y+h,x:x+w])
cv2.imshow('image', img)
k = cv2.waitKey(100) & 0xff # Press 'ESC' for exiting video
if k == 27:
break
elif count >= 50: # Take 50 face sample and stop video
break
# Do a bit of cleanup
print("\n [INFO] Exiting Program and cleanup stuff")
cam.release()
cv2.destroyAllWindows()
运行脚本后会让你输入ID,然后会花费大约一分半钟的时间来收集,这样,拍到的人脸照片在文件夹中的组织结构如下:
这里我ID为0的拍了100章,ID为2的拍了50张。然后接下来就可以运行训练脚本了,训练脚本如下:
import cv2
import numpy as np
from PIL import Image
import os
# Path for face image database
path = 'dataset'
recognizer = cv2.face.LBPHFaceRecognizer_create()
detector = cv2.CascadeClassifier("haarcascade_frontalface_default.xml");
# function to get the images and label data
def getImagesAndLabels(path):
imagePaths = [os.path.join(path,f) for f in os.listdir(path)]
faceSamples=[]
ids = []
for imagePath in imagePaths:
PIL_img = Image.open(imagePath).convert('L') # convert it to grayscale
img_numpy = np.array(PIL_img,'uint8')
id = int(os.path.split(imagePath)[-1].split(".")[1])
faces = detector.detectMultiScale(img_numpy)
for (x,y,w,h) in faces:
faceSamples.append(img_numpy[y:y+h,x:x+w])
ids.append(id)
return faceSamples,ids
print ("\n [INFO] Training faces. It will take a few seconds. Wait ...")
faces,ids = getImagesAndLabels(path)
recognizer.train(faces, np.array(ids))
# Save the model into trainer/trainer.yml
recognizer.write('trainer/trainer.yml') # recognizer.save() worked on Mac, but not on Pi
# Print the numer of faces trained and end program
print("\n [INFO] {0} faces trained. Exiting Program".format(len(np.unique(ids))))
训练大概需要一分钟左右,完成后会生成一个叫做haarcascade_frontalface_default.xml的文件,这样,人脸识别器的训练就完成了,我们接下来就可以进行人脸识别了,人脸识别的脚本如下:
import cv2
import numpy as np
import os
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.read('trainer/trainer.yml')
cascadePath = "haarcascade_frontalface_default.xml"
faceCascade = cv2.CascadeClassifier(cascadePath);
font = cv2.FONT_HERSHEY_SIMPLEX
#iniciate id counter
id = 0
# names related to ids: example ==> Marcelo: id=1, etc
names = ['GYY', 'MJX']
# Initialize and start realtime video capture
cam = cv2.VideoCapture(0)
cam.set(3, 640) # set video widht
cam.set(4, 480) # set video height
# Define min window size to be recognized as a face
minW = 0.1*cam.get(3)
minH = 0.1*cam.get(4)
while True:
ret, img =cam.read()
img = cv2.flip(img, -1) # Flip vertically
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(
gray,
scaleFactor = 1.2,
minNeighbors = 5,
minSize = (int(minW), int(minH)),
)
for(x,y,w,h) in faces:
cv2.rectangle(img, (x,y), (x+w,y+h), (0,255,0), 2)
id, confidence = recognizer.predict(gray[y:y+h,x:x+w])
# Check if confidence is less them 100 ==> "0" is perfect match
if (confidence < 100):
id = names[id]
confidence = " {0}%".format(round(100 - confidence))
else:
id = "unknown"
confidence = " {0}%".format(round(100 - confidence))
cv2.putText(img, str(id), (x+5,y-5), font, 1, (255,255,255), 2)
cv2.putText(img, str(confidence), (x+5,y+h-5), font, 1, (255,255,0), 1)
cv2.imshow('camera',img)
k = cv2.waitKey(10) & 0xff # Press 'ESC' for exiting video
if k == 27:
break
# Do a bit of cleanup
print("\n [INFO] Exiting Program and cleanup stuff")
cam.release()
cv2.destroyAllWindows()
运行后的状态如下图:
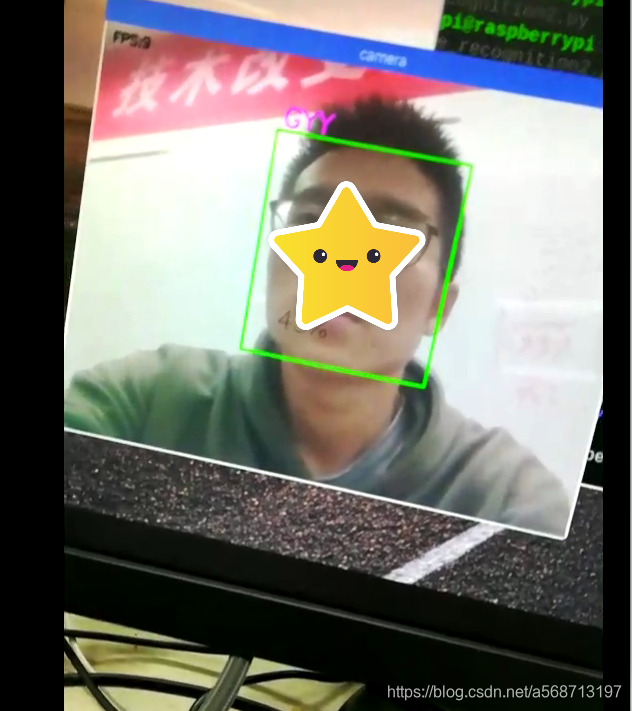
这样人脸识别我们就搞定了。
第六部分 帧数的提高
因为树莓派性能确实不够强,而且算法未经优化,帧数实在感人,如果直接运行上面的脚本应该只有2-3帧左右,但是帧数还是有提高的空间的,有俩种方法来提高帧数:跳帧计算和多线程运行。我上面那张图就是使用了跳帧计算,就是不对每张图都进行识别,而是每四张图片算一张,这样我提高到了9-11帧的样子,还有一个办法是写多线程程序,因为我还没有学习linux的多线程编程,所以并没有尝试,但是有网友试过了,并且如果使用跳帧计算+多线程运行的话可以做到20帧以上,还是相当可观的。
当然,算法的优化从来都是没有穷尽的,永远都有最好的做法,只要达到自己的需求就可以了,就我这个项目来说,不需要对视频流进行人脸检测,帧数不需要特别高,9-11帧完全可以满足我的需求。
第七部分 与stm32的通信
因为整个系统的控制中心是STM32所以树莓派必须把数据发送给STM32,我使用的是串口的方式来进行发送的,树莓派默认情况下串口1是调试串口可以进入bash,而我们要把它改为串口,配置方式如下:
1、查看当前串口配置

2、修改配置文件
打开/boot/config.txt文件
sudo nano /boot/config.txt
找到如下配置串口,如果没有,可添加在文件最后面
enable_uart=1
修改文件/boot/cmdline.txt:
sudo nano /boot/cmdline.txt
删除红色的部分
dwc_otg.lpm_enable=0 console=ttyAMA0,115200 kgdboc=ttyAMA0,115200 console=tty1 root=/dev/mmcblk0p2 rootfstype=ext4 elevator=deadline rootwait
3、关闭串口进入控制台
进入树莓派“BIOS”关闭即可
进入第六个关闭即可
4、测试串口
先安装pysersial
sudo apt-get install python-serial
然后编写一个脚本来测试串口
import serial
import os
import time
t = serial.Serial("/dev/ttyAMA0", 9600)
print (t.portstr)
str='Hello World\r\n'
while True:
print(str.encode())
t.write(str.encode())
time.sleep(1)
这个脚本是来测试串口发送功能的
*注意如果是python3必须将字符串转换成01代码才能发送(使用encode方法)
下面这个脚本是来测试串口的接收的
# -*- coding: utf-8 -*
import serial
import time
# 打开串口
ser = serial.Serial("/dev/ttyAMA0", 9600)
def main():
while True:
# 获得接收缓冲区字符
count = ser.inWaiting()
if count != 0:
# 读取内容并回显
recv = ser.read(count)
ser.write(recv)
print(str(recv))
#清空接收缓冲区
ser.flushInput()
#必要的软件延时
time.sleep(0.1)
if __name__ == '__main__':
try:
main()
except KeyboardInterrupt:
if ser != None:
ser.close()
接收到数据后就会打印在控制台。
这样,串口就配置完成了,至于数据的发送方法,直接发送字符串肯定是不那么好的,很容易会接收到的数据不完整,我这里还是使用的将数据打包成二进制代码然后一下发送的方法,就是struct的pack方法,这个我在openmv与stm32通信中有讲,不懂的同学可以去看看。
总结
到这里树莓派上的所有内容我就都讲完了,具体的代码我就不放了,因为自己写的很乱,也还没整理,同时因为同步问题我将pid的计算也放在了树莓派上,树莓派回传的其实是舵机的控制角度,代码不一定能给大家说清楚,所以就不放出来了,完成上面的所有内容我借鉴了很多别人的帖子,我会在下面列出来。
下一篇博客我会讲解STM32上的内容。
参考文章: