LZ78算法的压缩过程非常简单。在压缩时维护一个动态词典Dictionary,其包括了历史字符串的index与内容;压缩情况分为三种:
- 若当前字符c未出现在词典中,则编码为
(0, c); - 若当前字符c出现在词典中,则与词典做最长匹配,然后编码为
(prefixIndex,lastChar),其中,prefixIndex为最长匹配的前缀字符串,lastChar为最长匹配后的第一个字符; - 为对最后一个字符的特殊处理,编码为
(prefixIndex,)。
如果对于上述压缩的过程稍感费解,下面给出三个例子。例子一,对于字符串“ABBCBCABABCAABCAAB”压缩编码过程如下:
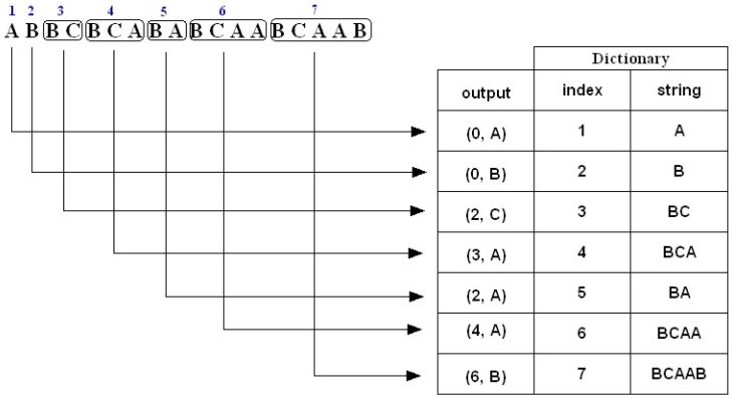
1. A is not in the Dictionary; insert it
2. B is not in the Dictionary; insert it
3. B is in the Dictionary. BC is not in the Dictionary; insert it.
4. B is in the Dictionary. BC is in the Dictionary. BCA is not in the Dictionary; insert it.
5. B is in the Dictionary. BA is not in the Dictionary; insert it.
6. B is in the Dictionary. BC is in the Dictionary. BCA is in the Dictionary. BCAA is not in the Dictionary; insert it.
7. B is in the Dictionary. BC is in the Dictionary. BCA is in the Dictionary. BCAA is in the Dictionary. BCAAB is not in the Dictionary; insert it.
例子二,对于字符串“BABAABRRRA”压缩编码过程如下:
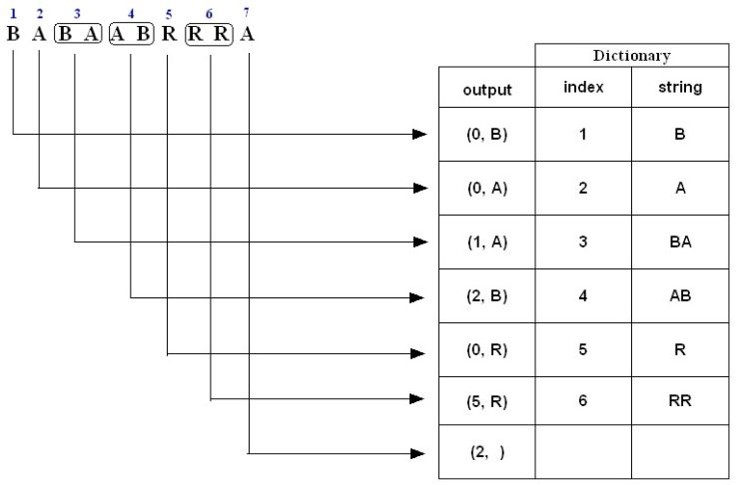
1. B is not in the Dictionary; insert it
2. A is not in the Dictionary; insert it
3. B is in the Dictionary. BA is not in the Dictionary; insert it.
4. A is in the Dictionary. AB is not in the Dictionary; insert it.
5. R is not in the Dictionary; insert it.
6. R is in the Dictionary. RR is not in the Dictionary; insert it.
7. A is in the Dictionary and it is the last input character; output a pair containing its index: (2, )
如何进行解压:
解压缩能更根据压缩编码恢复出(压缩时的)动态词典,然后根据index拼接成解码后的字符串。为了便于理解,我们拿上述例子一中的压缩编码序列(0, A) (0, B) (2, C) (3, A) (2, A) (4, A) (6, B)来分解解压缩步骤,如下图所示:

前后拼接后,解压缩出来的字符串为“ABBCBCABABCAABCAAB”。