基于Huffman算法和LZ77算法的文件压缩(五)
基于Huffman算法和LZ77算法的文件压缩(四)已经讲解LZ77算法到基本原理和压缩过程。
本文详细讲解文件压缩过程当中的问题
一、文件压缩的流程
上述在压缩中用到的理论知识介绍完成之后,就可以开始LZ77的压缩了,LZ77的压缩过程具体如下:
- 打开带压缩的文件(注意:必须按照二进制格式打开,因为用户进行压缩的文件不确定)
- 获取文件大小,如果文件大小小于3个字节,则不进行压缩
- 读取一个窗口的数据,即64K,
- 用前两个字符计算第一个字符与其后两个字符构成字符串哈希地址的一部分,因为哈希地址是通过三个字节算出来的,先用前两个字节算出一部分,在压缩时,再结合第三个字节算出第一个字符串完整的哈希地址。
- 循环开始压缩
a.计算哈希地址,将该字符串首字符在窗口中的位置插入到哈希桶中,并返回该桶的状态matchHead
b.根据matchHead检测是否找到匹配
- 如果matchHead等于0,未找到匹配,表示该三个字符在前文中没有出现过,将该当前字符 作为源字符写到压缩文件中
- 如果matchHead不等于0,表示找到匹配,matchHead代表匹配链的首地址,从哈希桶matchHead位置开始找最长匹配,找到后用该(距离,长度对)替换该字符串写到压缩文件中,然后将该替换串三个字符一组添加到哈希表中。
6 . 如果窗口中的数据小于MIN_LOOKAHEAD时,将右窗口中数据搬移到左窗口,从文件中新读取一个窗口的数据放置到右窗,更新哈希表,继续压缩,直到压缩结束。
二、 压缩格式数据保存
压缩格式分三个文件保存:
- 文件1保存比特标记为信息,用8个字节表示标记为长度,后面紧跟标记位
- 文件2保存原字符和长度
- 文件3保存所有的距离
上面的信息之前已经讲解过,接下来就对每个步骤讲解。
三、问题详细解释
- (长度,距离)对中的匹配字符长度为什么用1个字节???
- 1个字节的存储范围是[0,255],255理论上来说已经比较长(正常文件的字符匹配长度可能还达不到255),如果超过255就需要用2个字节存储,且真正字符匹配长度超过255的很少,所以用2个字节存储字符匹配长度对压缩率有一定的影响,即用一个字节存储即可。
- (长度,距离)对中的匹配字符的距离为什么用2个字节???
- 要知道匹配字符的距离有多大就需要缓冲区的大小(即滑动窗口的大小),
缓冲区越大,那么查找缓冲区和先行缓冲区就会越大,匹配字符的距离就会越长,前面说过,缓冲区不会无限大,那么缓冲区具体应该有多大呢??----- 64K大小
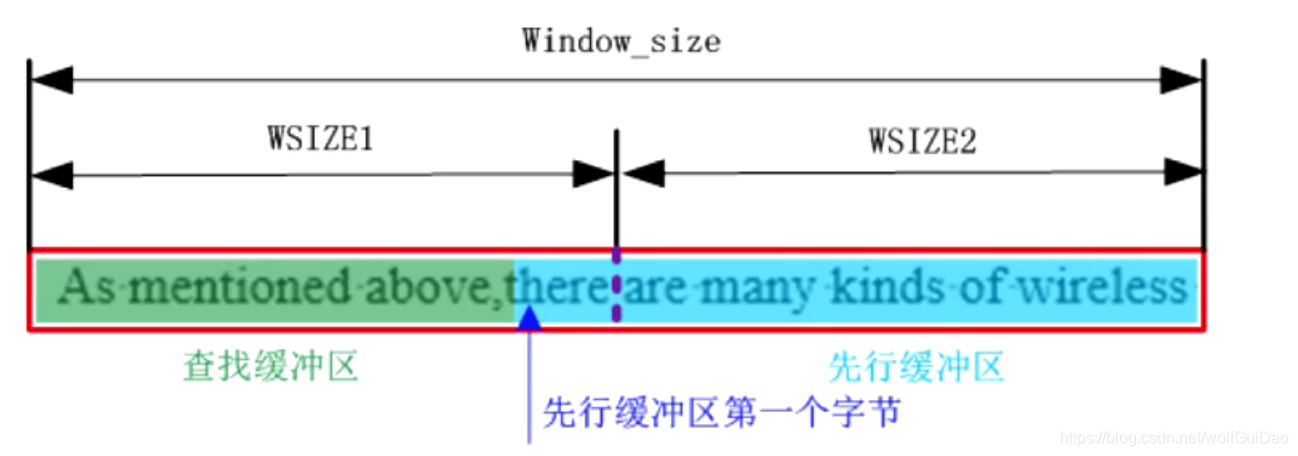
- 理论上只要是缓冲功能区当中压缩过的数据都因该是查找缓冲区,如下面这种情况:

- 那么这种情况的缓冲区的大小肯定是大于32K的,找到重复的概率会变大。但是我们不可能让匹配距离太远,且重复一般都有局部性(重复一般不会距离太远),如为了匹配3个字节而遍历55K的查找缓冲区是无意义的,反而影响文件的压缩效率。真正的匹配范围是不会超过WSIZE的,
即32K。
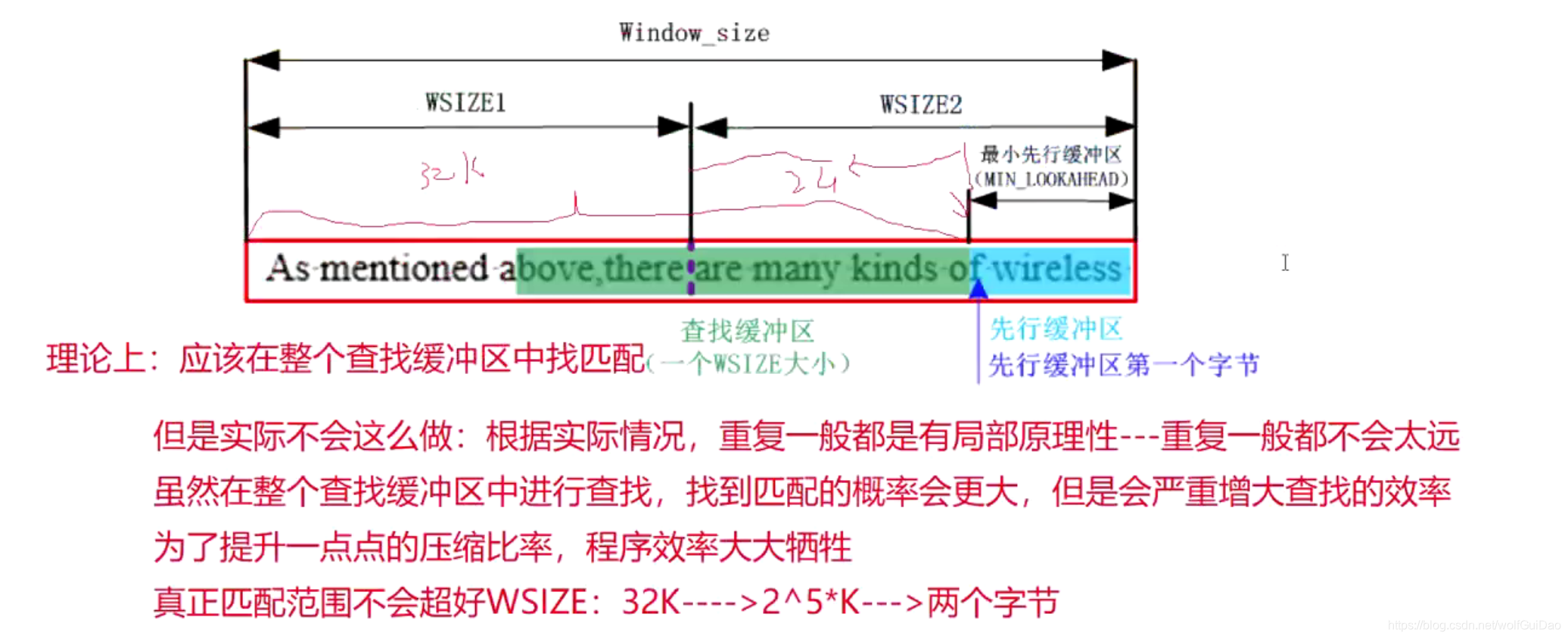
- 所以用2个字节来保存字符匹配的距离
- 当重复字符串的长度为多少个字节才去匹配呢?

- 经过前面的分析,长度距离对共占用1 + 2 = 3个字节,所以重复字符串的长度至少为3个字符才开始匹配,小于3个就去匹配就会使压缩文件变大,那么你在搞什么东东???
- 定义几个变量来进行标识:
MIN_MATCH_LEN = 3;//最小匹配长度
MAX_MATCH_LEN = 258;//最大匹配长度

- 我们压缩的方法就是从先行缓冲区当中取3个字节在查找缓冲区当中找匹配,那么如何
快速高效的进行呢???
答案就是哈希。
5.哈希表要给多大???
- 哈希表的大小取决于哈希函数计算出来的哈希地址,因为哈希表至少能够包含到所有的哈希地址。
- 哈希函数如下,其原理是用3个字符的每个字符的比特位进行操作,
那么哈希地址的范围就是3个字符的比特位共有多少种组合,即256 * 256 * 256 = 2^24种组合, - 而哈希表当中
每个位置保存的是首字符在缓冲区当中的下标(缓冲区的大小是64K == 65535)(其实只用到[0,32767],因为只在查找缓冲区中进行),所以还需要2个字节。 - 所以最后哈希表的大小是: 2 ^ 24 * 2 = 2 ^ 25 == 32M空间,

- 32M空间是非常大的,每次进行压缩都要维护32M空间是非常耗时的,所以人为规定哈希表当中
位置的个数为:2^15 == 32K,整个哈希表的大小为2 ^ 15 * 2 = 2 ^ 16,但是注意后面会改造哈希表,哈希表的大小就会变,就不是2 ^ 16 大小了。 - 那么这样给哈希表的大小带来的问题是:哈希地址多于哈希表的位置数,那么就
一定会发生哈希冲突,发生哈希冲突怎么解决呢?你不能不管不顾吧,那就改造哈希表格。
6.哈希表的结构
- prev指针专门用来解决哈希冲突的
- head的作用是用来保存记录匹配链的头。因为数据在哈希表当中的保存相当于一个链,发生哈希冲突的元素都在这个链上。
- prev和head的大小都为WSIZE的原因是为了和后面统一。

- 发生哈希冲突的解决过程:
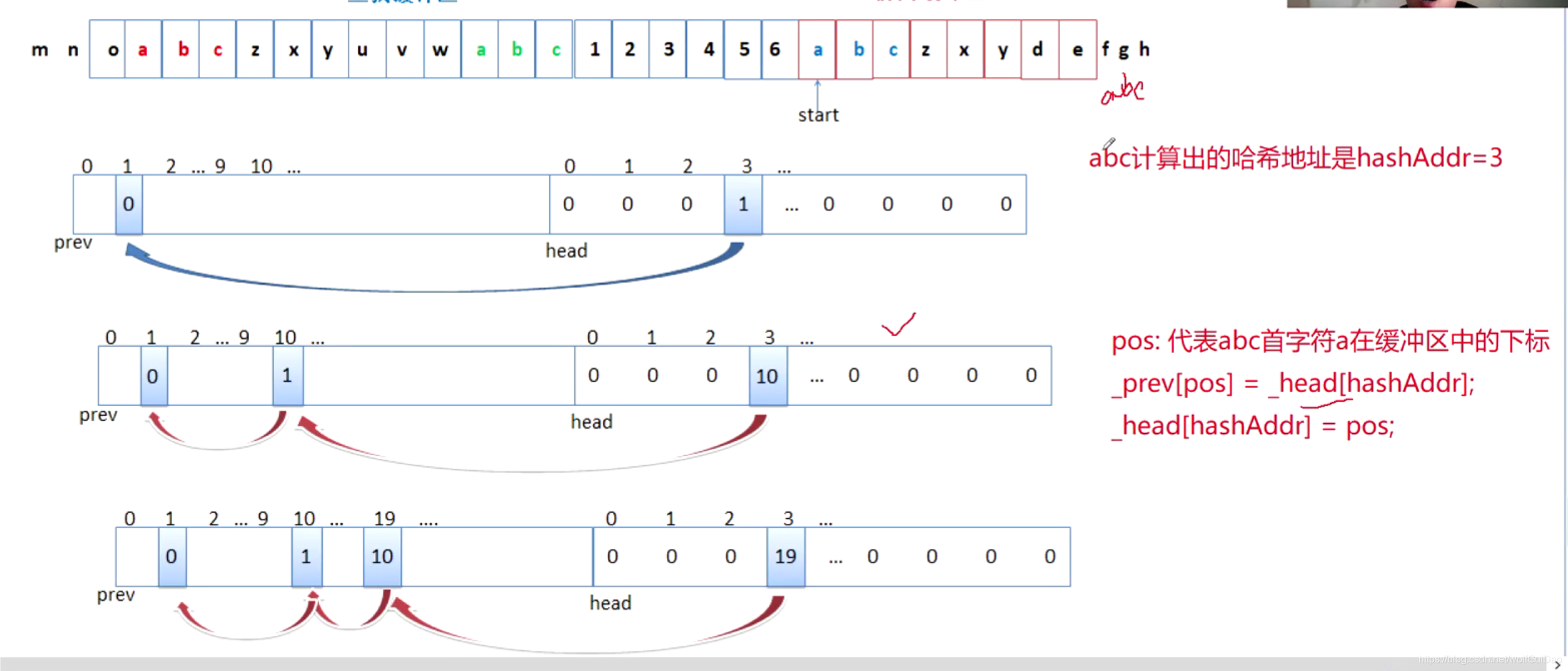
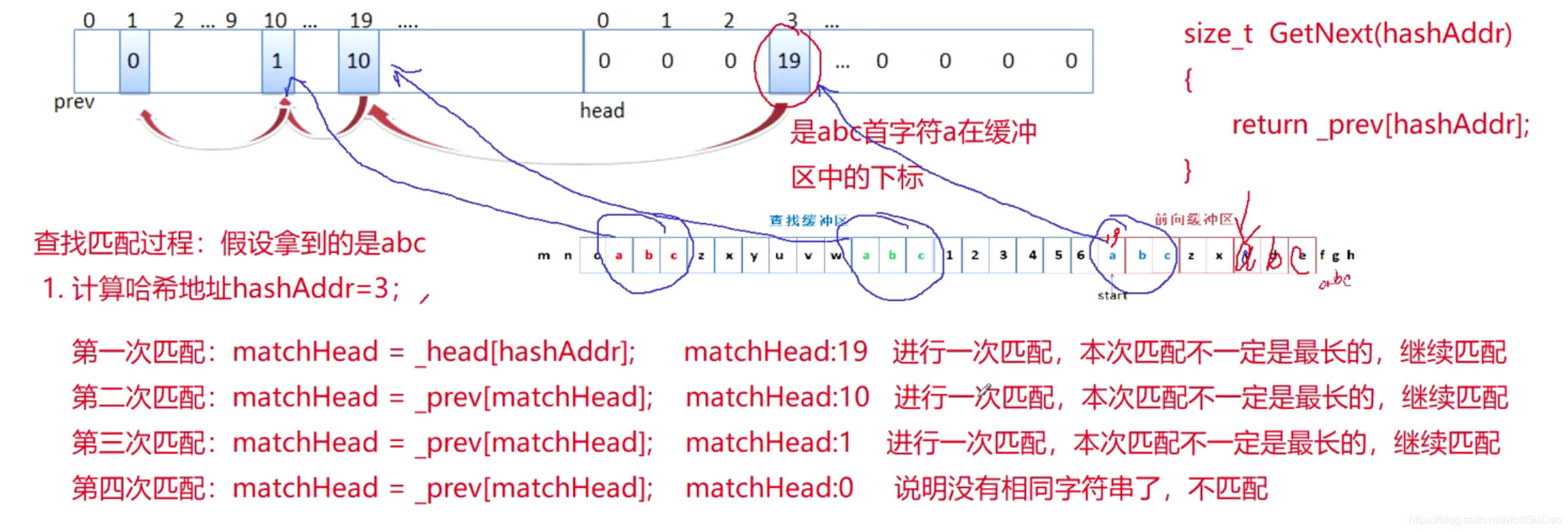
- 一定要理解哈希冲突的解决过程,每个位置的意义
7.哈希表的越界问题
- 随着压缩的进行,
可定会进行到大于WSIZE处,即图中的start处,那么在进行往哈希表当中插入元素时执行_prev[pos] = _head[hashAddr]就会越界,既然越界就需要解决。
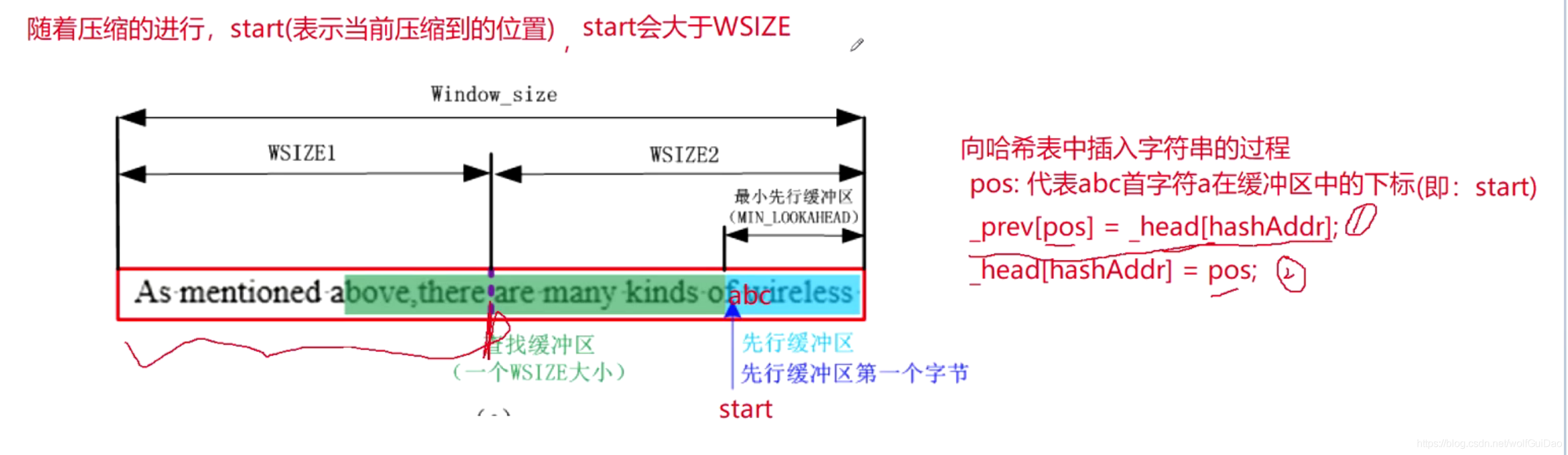

- 越界的解决方式:
pos & WMASK,保证结果在WSIZE的范围内 - 这种解决越界问题带来的后果是什么?
可能会出现死循环
8.用&WMASK来防止越界可能带来的结果
- 可能会出现
死循环的情况 - 如下图,&完的结果可能为10,那么执行_prev[10] = _head[hashAddr]后就会在_prev内部形成一个环。
- 假设还有一个相同字符串的匹配到来,就会执行
machHead = _head[hashAddr];machHead = _prev[machHead]...那么根据下图,他就会一直在_prev内部转圈,形成死循环。

- 这种死循环的解决方式:人为规定最多找匹配次数为255。原因有两种:
- 1.如果为了找匹配进行了超过255次的查找过程,那么就会影响压缩文件的效率,不划算。
- 2.粗暴的解决这种死循环问题,让他直接break。
9.哈希表的构造
- 哈希表的构造过程是和在哈希表当中找匹配是同步进行的。
- 哈希表中
保存的内容是先行缓冲区当中取出来匹配到3个字符的首字符在整个缓冲区的下标
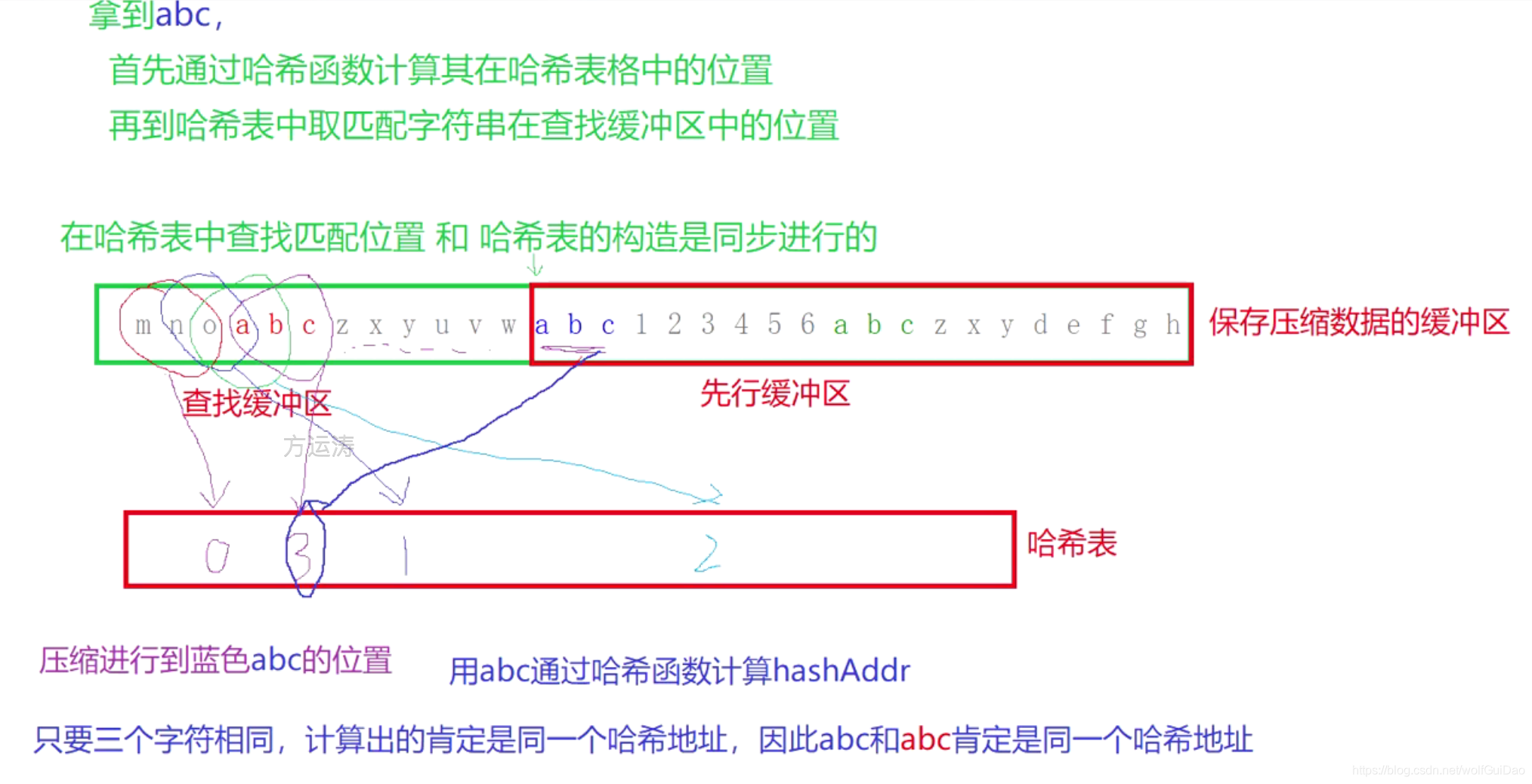
10.先行缓冲区当中剩余字符的最小个数是多少?
- 如下图,如果先行缓冲区当中剩余的字符太少还去进行匹配,那么就无法达到最优的匹配结果,所以需要设置一个变量来进行标记。
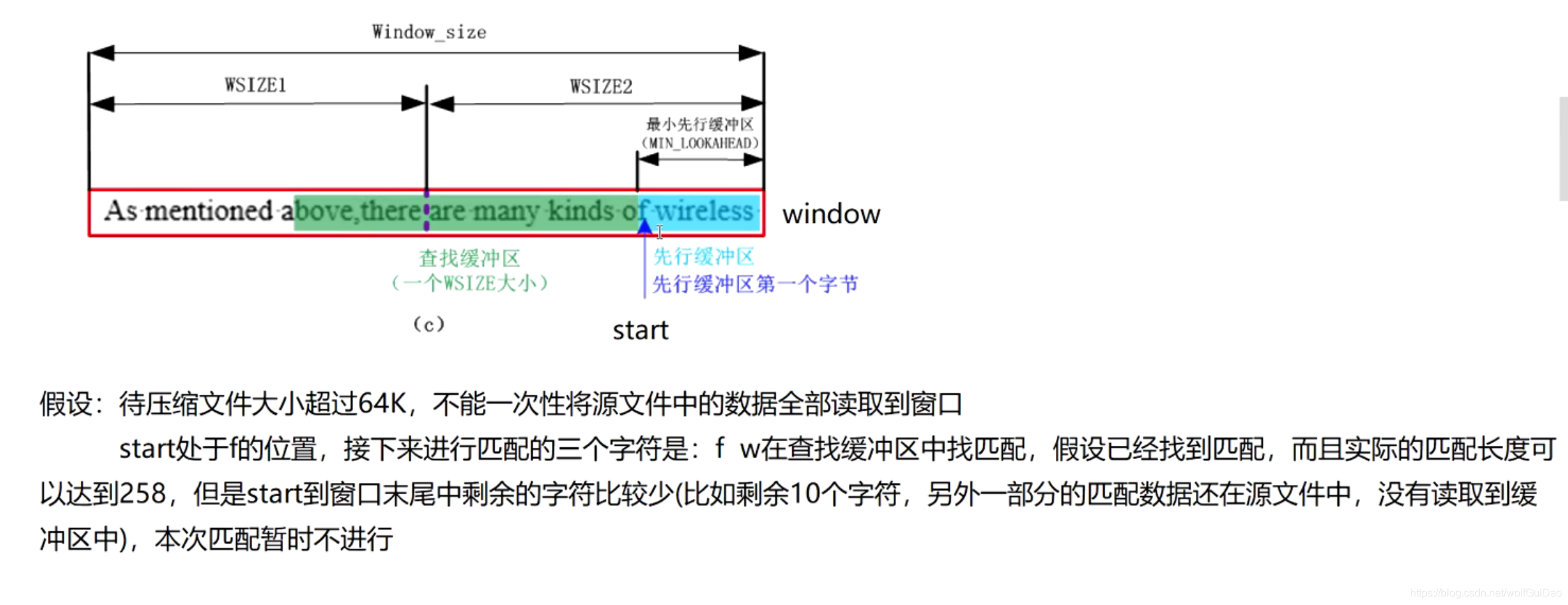
- 定义
MIN_LOOKAHEAD = MAX_MACTH + MIN_MACTH + 1; - MIN_LOOKAHEAD代表先行缓冲区当中剩余字符的最小个数
- MAX_MACTH代表字符串的最大匹配长度,此处的目的是为了满足当前字符串能够得到最优的匹配结果
- MIN_MACTH 代表字符串的最小的匹配长度,MIN_MACTH + 1此处的目的是是保证还可以进行下一次匹配
- 当先行缓冲区当中的数据小于MIN_LOOKAHEAD则不进行匹配
- 定义
MAX_DIST = WSIZE - MIN_LOOKAHEAD= 32K - 258 - 3 - 1 ;MAX_DIST 代表最大的字符串匹配距离,这个就很容易理解,因为在下面11问中的窗口数据的挪移过程中,查找缓冲区当中只剩下WSIZE - MIN_LOOKAHEAD这么多了!!!
11.怎么保证先行缓冲区当中的数据大于等于MIN_LOOKAHEAD?
给个图,解释每个步骤:
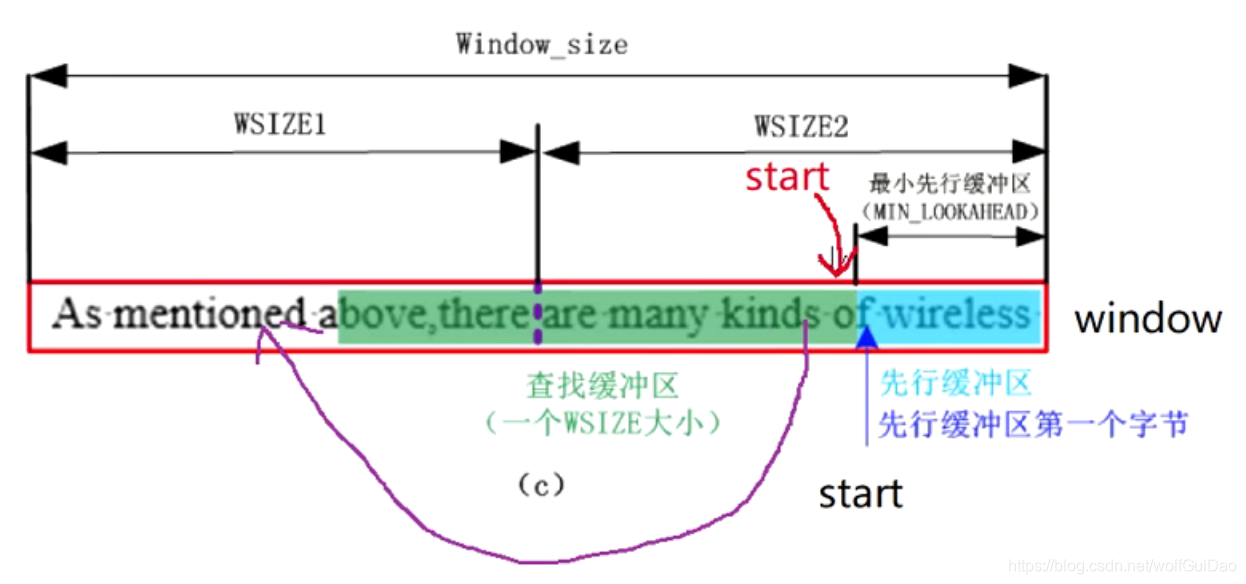
- 将右窗WSIZE2当中的数据导入到左窗WSIZE1当中
- 从待压缩文件当中再读取一个WSIZE个字符到右窗WSIZE2,更新当前压缩指针的位置(假设当前压缩到start处,把start -= WSIZE;)
- 必须要更新哈希表,因为整个数据的位置已经挪动,
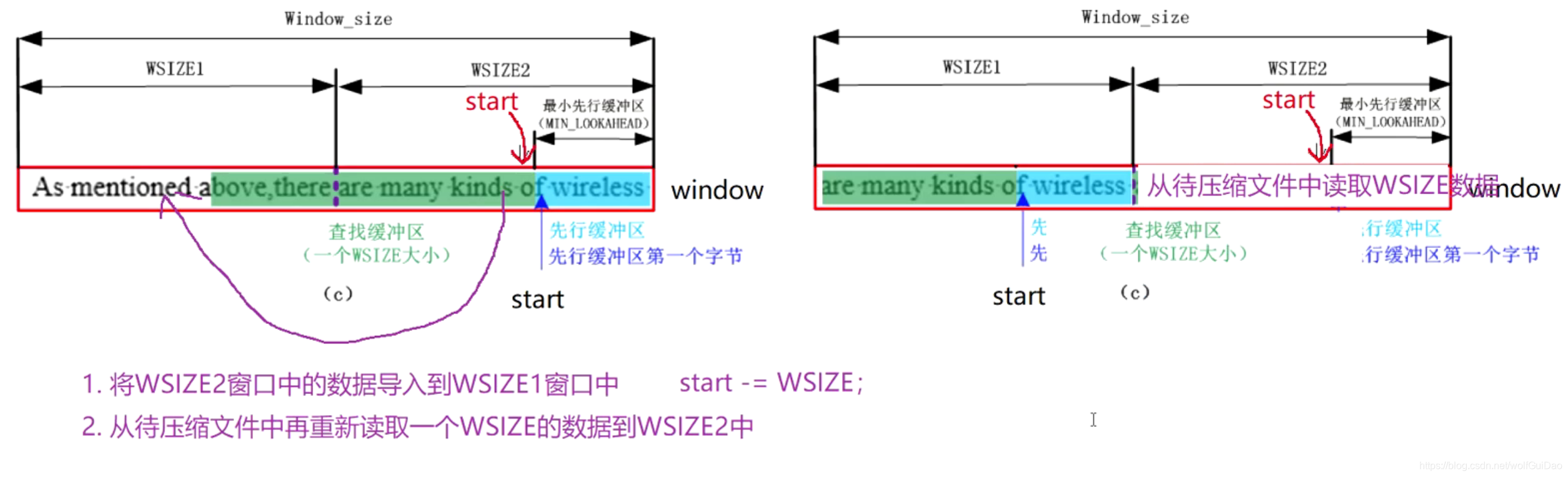
注意注意注意,如果待压缩文件本来的大小就小于WSIZE的情况。此时再去文件当中读取WSIZE个数据到右窗WSIZE2当中就会报错,使用的时候需要另行判断。
12.怎么更新哈希表?
- 把prev和head当中大于WSIZE的数据都减掉WSIZE,小于WSIZE的数据直接置为0即可。
到这里整个过程的细节都已经解释完毕,终于可以撸代码了!!!
请看下节~~~
