基于Huffman算法和LZ77算法的文件压缩(七)
基于Huffman算法和LZ77算法的文件压缩(六)已经讲解完文件压缩的过程,本文讲解文件解压缩的过程和大文件处理方式
一、解压缩的流程
LZ77的解压缩非常简单:
- 从文件1中读取标记,并对该标记进行分析
- 如果当前标记是0,表示原字符,从文件2中读取一个字节,直接写到解压缩之后的文件中
- 如果当前标记是1,表示遇到(距离,长度对),从文件3中读取一个两个字节表示距离,从文件1中读取一个字节表示长度,构建(距离,长度)对,然后从解压缩过的结果中找出匹配长度
- 获取下一个标记,直到所有的标记解析完。
二、合并标记信息文件和压缩数据文件
- 开始解压缩前我们需要合并压缩数据文件和标记信息文件,那么合并到一起怎么区分压缩数据和标记信息呢?
- 我们还要在合并后的压缩文件当中
写入标记信息的总字节数和原数据文件的大小。

- 注意合并完成后
文件大小和标记信息大小的 获取方式:
//获取源文件大小
ULL fileSize = 0;
fseek(fInF, 0 - sizeof(fileSize), SEEK_END);
fread(&fileSize, sizeof(fileSize), 1, fInF);
//获取标记信息的大小
size_t flagSize = 0;
fseek(fInF, 0 - sizeof(fileSize) - sizeof(flagSize), SEEK_END);
fread(&flagSize, sizeof(flagSize), 1, fInF);
合并文件
//合并文件
void LZ77::MergeFile(FILE* fOut, ULL fileSize)
{
//将压缩数据文件和标记信息文件合并
//1.读取标记信息文件中内容,然后将结果写入到压缩文件中
FILE* fInf = fopen("3.txt", "rb");
size_t flagSize = 0;
UCH* pReadbuff = new UCH[1024];
while (true)
{
size_t rdSize = fread(pReadbuff, 1, 1024, fInf);
if (rdSize == 0)
break;
//把标记信息写到压缩数据文件中
fwrite(pReadbuff, 1, rdSize, fOut);
//更新数据
flagSize += rdSize;
}
//向压缩数据文件中写标记信息大小,方便解压缩
fwrite(&flagSize, sizeof(flagSize), 1, fOut);
//向压缩数据文件中写文件数据大小,方便解压缩
fwrite(&fileSize, sizeof(fileSize), 1, fOut);
delete[] pReadbuff;
fclose(fInf);
}
- 注意
读取标记信息文件指针的起始位置
//将读取标记信息的文件指针移动到保存标记数据的起始位置
fseek(fInF, 0 - sizeof(flagSize) - sizeof(fileSize) - flagSize, SEEK_END);
-
合并完后,解压缩的流程:


三、开始解压缩 -
同样还是先在标记文件当中读取一个字节chFlag(其8个比特位的01就代表是原字符还是长度距离对),
& 0x80来判断高位01情况 -
注意如果标记信息是1,就代表是长度距离对,把
长度读取出来需要 + 3。 -
如果是长度距离信息,需要再来一个文件指针,从
解压缩文件末尾往前偏移距离个位置(即定位到匹配字符的开始),然后往后写长度个字符到解压缩文件 -
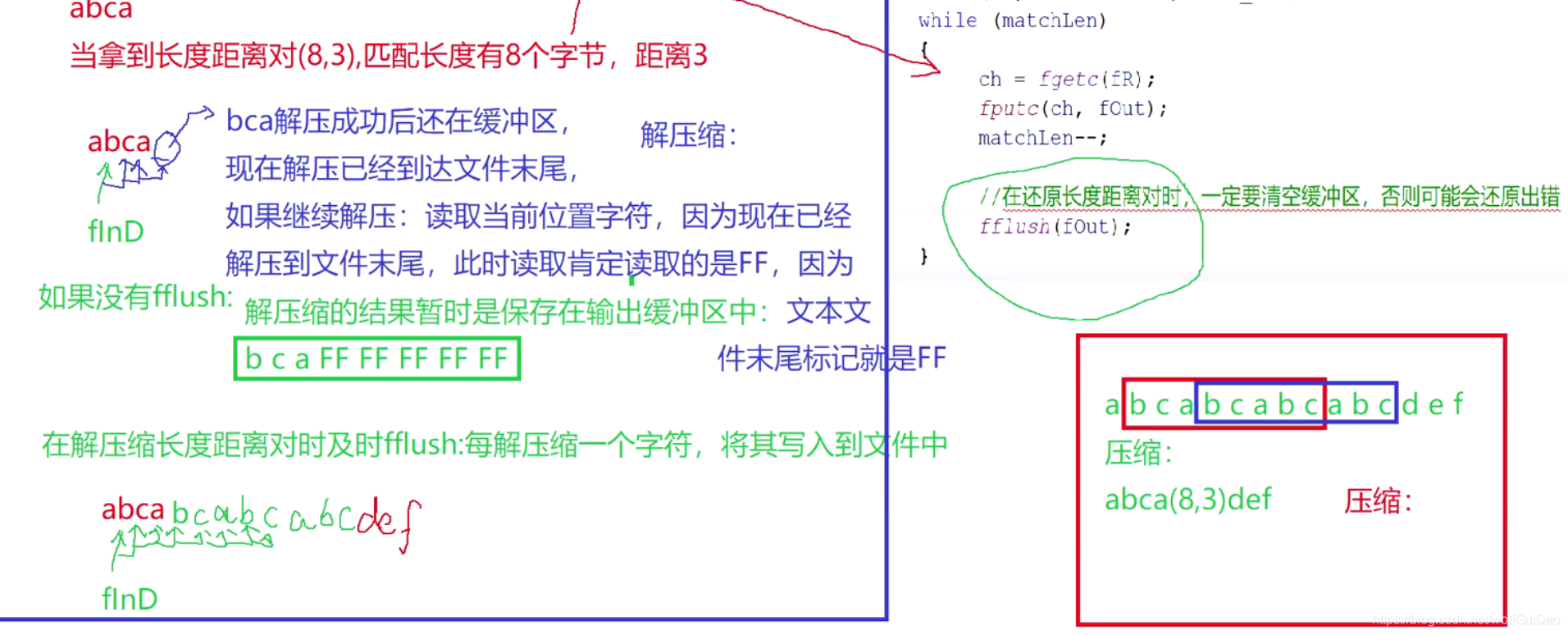
注意注意在,操作系统为了提高读取写入的效率,是
提供缓冲区的机制,如果你向文件当中写入数据,其实是写到缓冲区当中,缓冲区满就才会往文件当中写,而前面我们说过,解压缩的文件是有两个指针打开的(一个是写压缩数据,一个是定位匹配字符的开始位置),现在如果写压缩数据的文件指针把数据写入到缓冲区并没有写入到文件,此时定位匹配字符开始位置的指针需要读取长度个字符写入到解压缩文件,这样就会报错,因为压缩文件当中的数据还在缓冲区,代表压缩文件当中没有数据,你去读取,就只能读取一个255,就达不到解压缩的目的。怎么解决呢??? 刷新缓冲区
解压缩完整代码:
//解压缩
void LZ77::UNCompressFile(const std::string& strFilePath)
{
//打开压缩文件和标记文件
FILE* fInD = fopen(strFilePath.c_str(), "rb");
if (nullptr == fInD)
{
std::cout << "压缩文件打开失败" << std::endl;
return;
}
//操作标记数据的文件指针
FILE* fInF = fopen(strFilePath.c_str(), "rb");
if (nullptr == fInF)
{
std::cout << "压缩文件打开失败" << std::endl;
return;
}
//获取源文件大小
ULL fileSize = 0;
fseek(fInF, 0 - sizeof(fileSize), SEEK_END);
fread(&fileSize, sizeof(fileSize), 1, fInF);
//获取标记信息的大小
size_t flagSize = 0;
fseek(fInF, 0 - sizeof(fileSize) - sizeof(flagSize), SEEK_END);
fread(&flagSize, sizeof(flagSize), 1, fInF);
//将读取标记信息的文件指针移动到保存标记数据的起始位置
fseek(fInF, 0 - sizeof(flagSize) - sizeof(fileSize) - flagSize, SEEK_END);
//开始解压缩
//写解压缩数据
//FILE* ffOut = fopen("5.txt","rb");
//std::string filestr ;
//std::cout<<filestr<<std::endl;
//fread(&filestr,sizeof(filestr),1,ffOut);
//std::string str = "4.";
//str += filestr;
//fclose(ffOut);
FILE* fOut = fopen("4.txt", "wb");
assert(fOut);
FILE* fR = fopen("4.txt", "rb");
assert(fR);
UCH bitCount = 0;
UCH chFlag = 0;
ULL encodeCount = 0;//标记已经解压缩的数据大小,方便判断解压缩的结束
while (encodeCount < fileSize)
{
//读取标记
if (0 == bitCount)
{
//读取一个字节
chFlag=fgetc(fInF);
bitCount = 8;
}
if (chFlag & 0x80)//当前字节的高位为1
{
//距离长度对
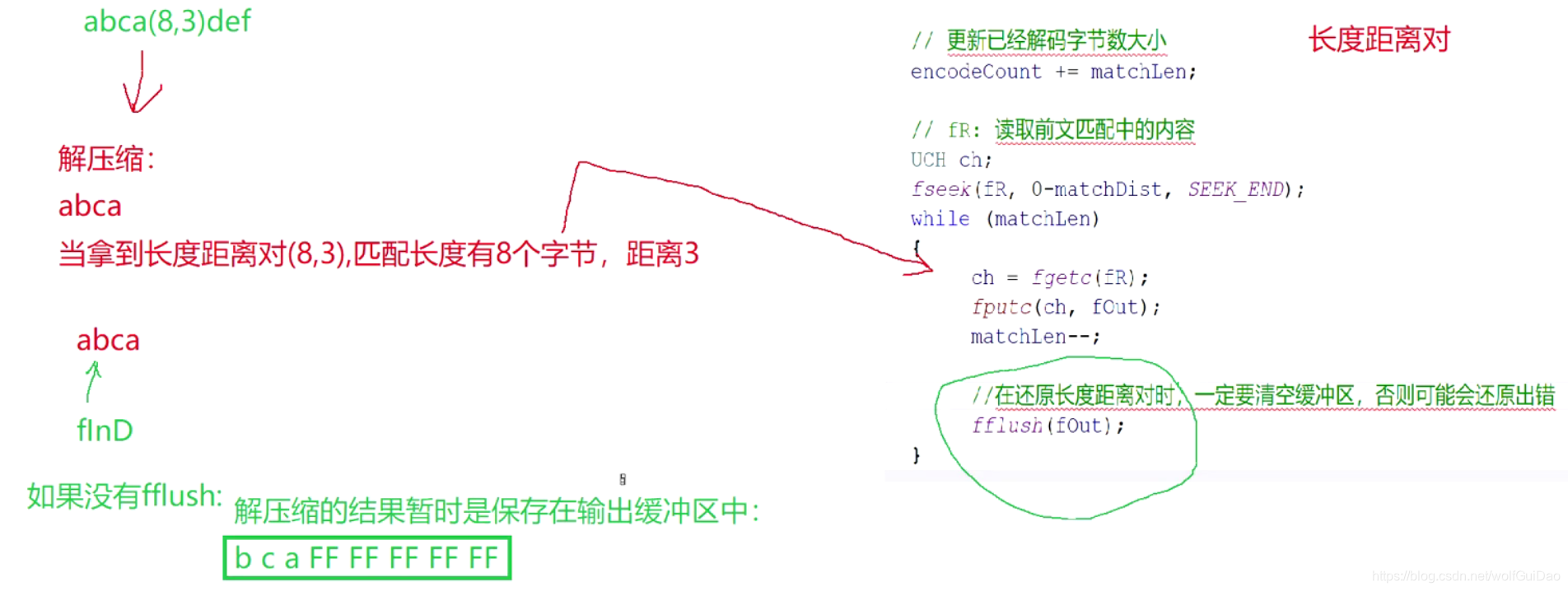
USH matchLen = fgetc(fInD) + 3;//长度
USH matchDist = 0;//距离
fread(&matchDist, sizeof(matchDist), 1, fInD);
//清空缓冲区,非常重要
fflush(fOut);
//更新已经解码的字节数大小
encodeCount += matchLen;
//fR:读取前文匹配串中的内容
UCH ch;
fseek(fR, 0 - matchDist, SEEK_END);
while (matchLen)
{
ch = fgetc(fR);
fputc(ch, fOut);
--matchLen;
//在还原长度距离对时,一定要清空缓冲区,否则可能会还原出错
fflush(fOut);
}
}
else
{
//原字符
UCH ch = fgetc(fInD);
fputc(ch, fOut);
encodeCount += 1;
}
chFlag <<= 1;
bitCount--;
}
fclose(fInD);
fclose(fInF);
fclose(fOut);
fclose(fR);
}
到这里,简单的文件解压缩已经OK,接下来就针对大文件的压缩和解压缩进行补充
四、大文件处理
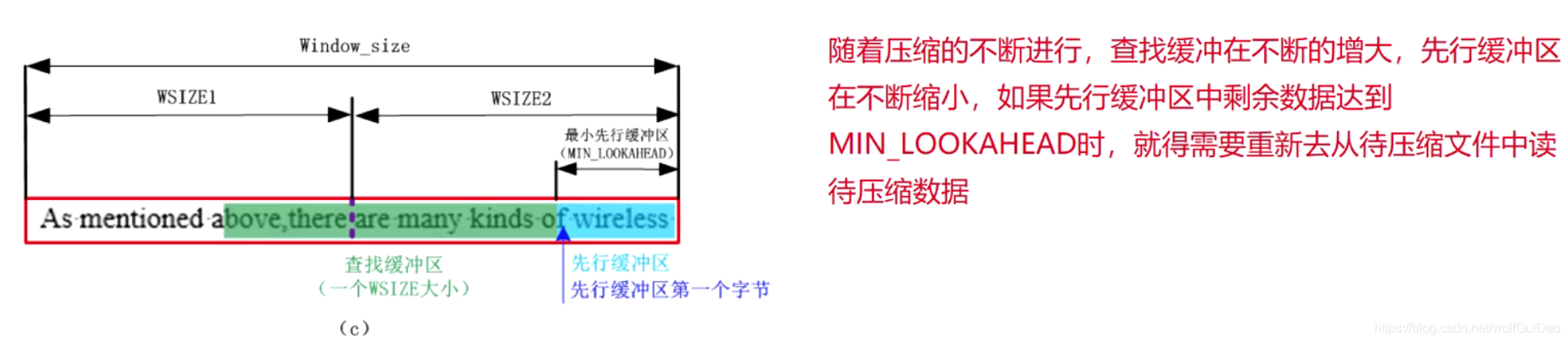
- 更新哈希表:当把右窗当中的数据搬移到左窗后,左窗当中的数据已经被覆盖掉,右窗当中的数据已经在start - WSIZE 处,所以需要更新哈希表

//更新哈希表
void HashTable::Update()
{
for (USH i = 0; i < WSIZE; ++i)
{
//先更新head,把大于等于WSIXE的下标 减去 WSIZE 放到哈希表的左窗内
//把head中小于WSIZE 的下标直接置为0,因为小于WSIZE的下标
//在查找缓冲区中距离先行缓冲区的距离太远了,进行匹配不划算
if (head_[i] >= WSIZE)
head_[i] -= WSIZE;
else
head_[i] = 0;
//更新prev,和head同理
if (prev_[i] >= WSIZE)
prev_[i] -= WSIZE;
else
prev_[i] = 0;
}
}
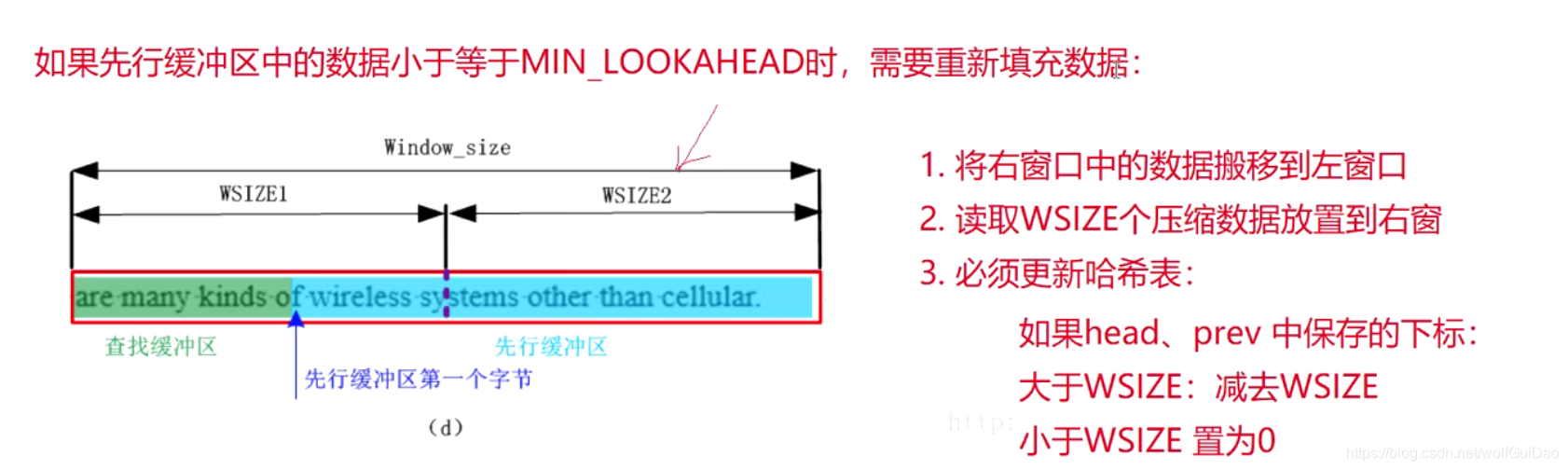
2.填充窗口
- 注意源文件就是小文件的情况,那么在压缩一部分后,源文件已经没有数据,文件指针已经走到文件的末尾,如果再去向右窗填充数据,就会报错,需要判断

//向缓冲区中填充数据
void LZ77::FillWindow(FILE* fIn, size_t& lookAhead, USH& start)
{
//start压缩已经进行到右窗,先行缓冲区剩余数据不够MIN_LOOKAHEAD
if (start >= WSIZE) //如果不进行if判断,在进行小文件压缩时还会继续
//从文件中读取数据,但是文件已经走到末尾
{
//1.将右窗中的数据搬移到左窗
memcpy(pWin_, pWin_ + WSIZE, WSIZE);
//将右窗中的内容清0,防止影响后续数据
memset(pWin_ + WSIZE, 0, WSIZE);
//更新start,start本来是大于WSIZE,经过1步骤后,start应该在左窗,
start -= WSIZEc;
//2.更新哈希表
ht_.Update();
//3.向右窗中补充WSIZE个的待压缩数据
if (!feof(fIn))//判断文件是否走到末尾
lookAhead += fread(pWin_ + WSIZE, 1, WSIZE, fIn);
}
}
3.注意查找范围和压缩范围重叠的情况
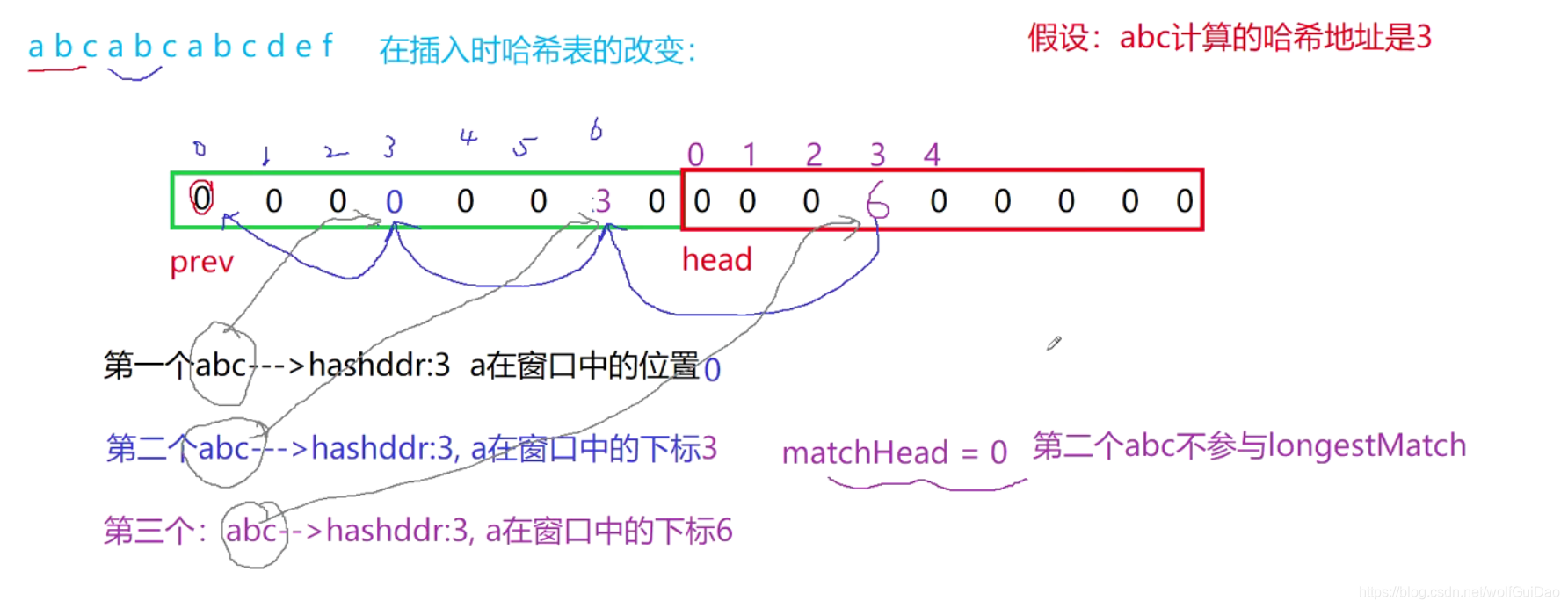
- 下图这种情况当指针走到BD的时候,匹配字符串的长度距离是多少?
(5,3)

为什么指针在E4的时候不进行匹配呢?按理说是可以进行一次匹配的。答案就是哈希表的结构引起的,我们在初始化的时候把哈希表当中的每个位置都设为0,代表匹配结束即到达匹配链的末尾,在这里,E4 BD A0经过哈希函数计算出哈希地址后,在相应哈希地址的位置放E4这个字符在缓冲区当中的下标,而这个下标刚好又为0,在第二个E4到来之后,拿到的匹配头为0,所以是不进行匹配的
- 这种情况下,还原长度距离对还需要刷新缓冲区,到这里解压缩就需要2次刷新缓冲区




到这里基于LZ77算法的文件压缩已经完成
五、总结
我们的项目是基于GZIP的思想进行压缩的。
1.总结GZIP压缩的思想

2.项目的缺陷
- 当前已完成基于Huffman和LZ77算法的文件压缩与解压缩。
改进的方向就是把Huffman和LZ77算法的文件压缩与解压缩结合起来,模拟GZIP- 但是不能直接把LZ77的压缩结果用Huffman进行压缩,原因是压缩率不理想


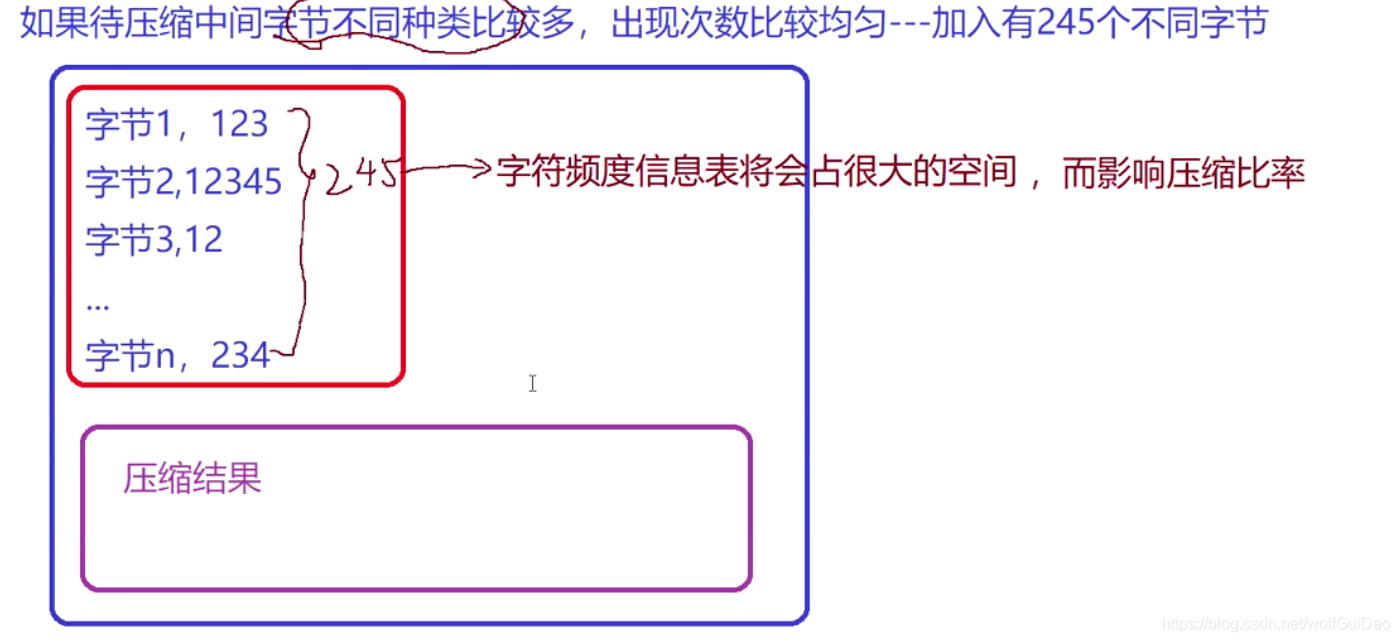
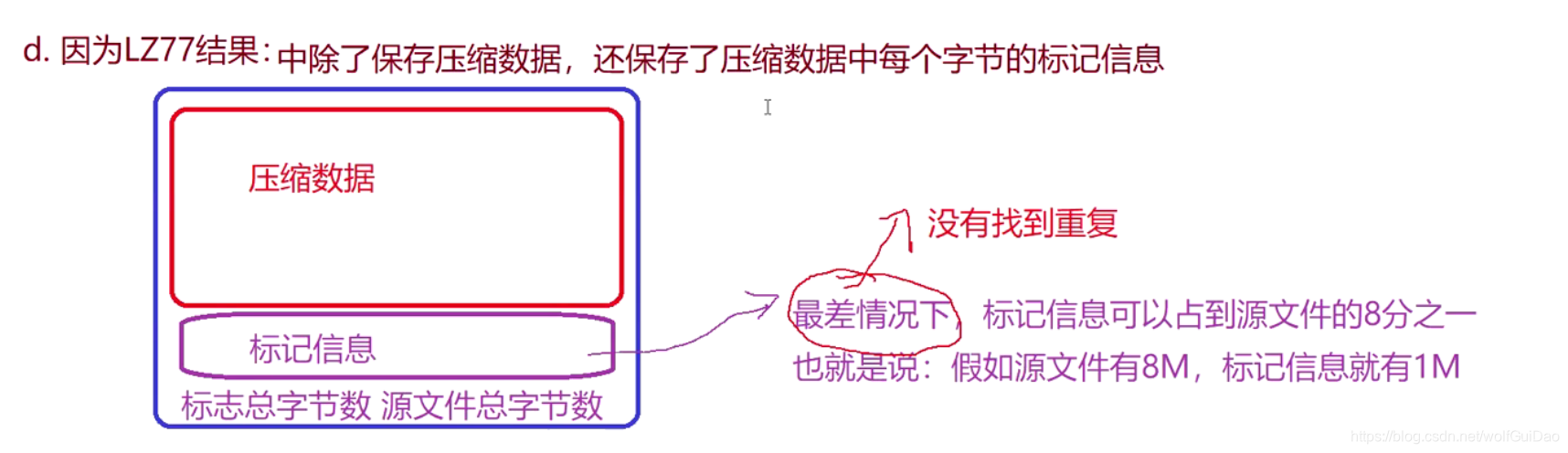

3.项目的改进方向
- 不要直接对LZ77的压缩结果采用Huffman树的方法进行压缩-----Huffman树的变形:
范式Huffman树
4.范式Huffman树
请看下节
