目录
MySQL
一、存储引擎
1.简介
MySQL中的数据用各种不同的技术存储在文件(或者内存)中。这些技术中的每一种技术都使用不同的存储机制、索引技巧、锁定水平并且最终提供广泛的不同的功能和能力。通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能。
例如,如果你在研究大量的临时数据,你也许需要使用内存MySQL存储引擎。内存存储引擎能够在内存中存储所有的表格数据。又或者,你也许需要一个支持事务处理的数据库(以确保事务处理不成功时数据的回退能力)。
这些不同的技术以及配套的相关功能在 MySQL中被称作存储引擎(也称作表类型)。
2.分类
MySQL两种存储引擎:
- MyISAM
MySQL的默认数据库引擎(5.5版之前),由早期的ISAM(Indexed Sequential Access Method:有索引的顺序访问方法)所改良。虽然性能极佳,但却有一个缺点:不支持事务处理(transaction)。不过,在这几年的发展下,MySQL也导入了InnoDB(另一种数据库引擎),以强化参考完整性与并发违规处理机制,后来就逐渐取代MyISAM。- InnoDB
InnoDB,是MySQL的数据库引擎之一,为MySQL AB发布binary的标准之一。InnoDB由Innobase Oy公司所开发,2006年五月时由甲骨文公司并购。
与传统的ISAM与MyISAM相比,InnoDB的最大特色就是支持了ACID兼容的事务(Transaction)功能,类似于PostgreSQL。目前InnoDB采用双轨制授权,一是GPL授权,另一是专有软件授权。# 使用MySQL客户端命令,显示当前MySQL系统所支持的数据库引擎。
show engines;
# 看你的mysql当前默认的存储引擎:
mysql> show variables like '%storage_engine%';
# 你要看某个表用了什么引擎(在显示结果里参数engine后面的就表示该表当前用的存储引擎):
mysql> show create table 表名;3.MyISAM
MyISAM不支持事务,不支持外键,支持全文索引,处理速度快。主要面向OLAP数据库应用。
MyISAM存储引擎的表存储成3个文件,文件名与表名相同,扩展名分别为:frm,MYD,MYI。
- frm文件:存储表的结构。
- myd文件:存储数据。
- myi文件:存储存储索引。
4.InnoDB
InnoDB是一个健壮的事务型存储引擎,这种存储引擎已经被很多互联网公司使用,为用户操作非常大的数据存储提供了一个强大的解决方案。InnoDB还引入了行级锁定和外键约束,在以下场合下,使用InnoDB是最理想的选择:
- 更新密集的表。InnoDB存储引擎特别适合处理多重并发的更新请求。
- 事务。InnoDB存储引擎是支持事务的标准MySQL存储引擎。
- 自动灾难恢复。与其它存储引擎不同,InnoDB表能够自动从灾难中恢复。
- 外键约束。MySQL支持外键的存储引擎只有InnoDB。
- 支持自动增加列AUTO_INCREMENT属性。
InnoDB存储引擎的表存储成2个文件
- frm文件:存储表的结构。
- ibd文件:存储表的数据行和索引
二、事务
1.简介
MySQL 事务主要用于处理操作量大,复杂度高的数据。比如说,在人员管理系统中,你删除一个人员,你即需要删除人员的基本资料,也要删除和该人员相关的信息,如信箱,文章等等,这样,这些数据库操作语句就构成一个事务!
- 在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务。
- 事务处理可以用来维护数据库的完整性,保证成批的 SQL 语句要么全部执行,要么全部不执行。
- 事务用来管理 insert,update,delete 语句
一般来说,事务是必须满足4个条件(ACID)::原子性(Atomicity,或称不可分割性)、一致性(Consistency)、隔离性(Isolation,又称独立性)、持久性(Durability)。
- 原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
- 一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
- 隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。
- 持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
2.事务的并发问题
1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
3、幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
3.MySQL事务隔离级别
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
注: mysql默认的事务隔离级别为repeatable-read
4.使用
# 开始一个事务
BEGIN
# 增删改操作
。。。。
。。。。
# 事务回滚
ROLLBACK
# 事务确认,一旦提交,才会应用到数据库,没提交之前的数据变化都是虚假的
COMMIT
# 隐式提交,也就是自动提交
# 查看autocommit,on/off
show variables like 'auto%'
# autocommitm默认为1,每次执行sql语句都会自动提交
# 如果需要事务操作的话
# 临时禁止自动提交
SET AUTOCOMMIT=0
# 永久的话,去配置文件my.cnf ,加上一句话
autocommit=0;
# 举例
# 1.BEGIN之后没有提交或回滚,又开始BEGIN,会导致上面的的自动提交
BEGIN
。。。。
。。。。
BEGIN
。。。。
# 2.create drop alter grant 也会触发数据提交
BEGIN
。。。。
。。。。
create drop alter grant 三、日志
1. 错误日志
错误日志是一个文本文件。
错误日志记录了MySQL Server每次启动和关闭的详细信息以及运行过程中所有较为严重的警告和错误信息。
可以用--log-error[=file_name]选项来开启mysql错误日志,该选项指定mysqld保存错误日志文件的位置。
# my.cnf配置文件
log_error=/var/log/mysql.log
#查看当前的错误日志配置,缺省情况下位于数据目录
mysql> show variables like 'log_error';2.事务日志(十六进制的变化)
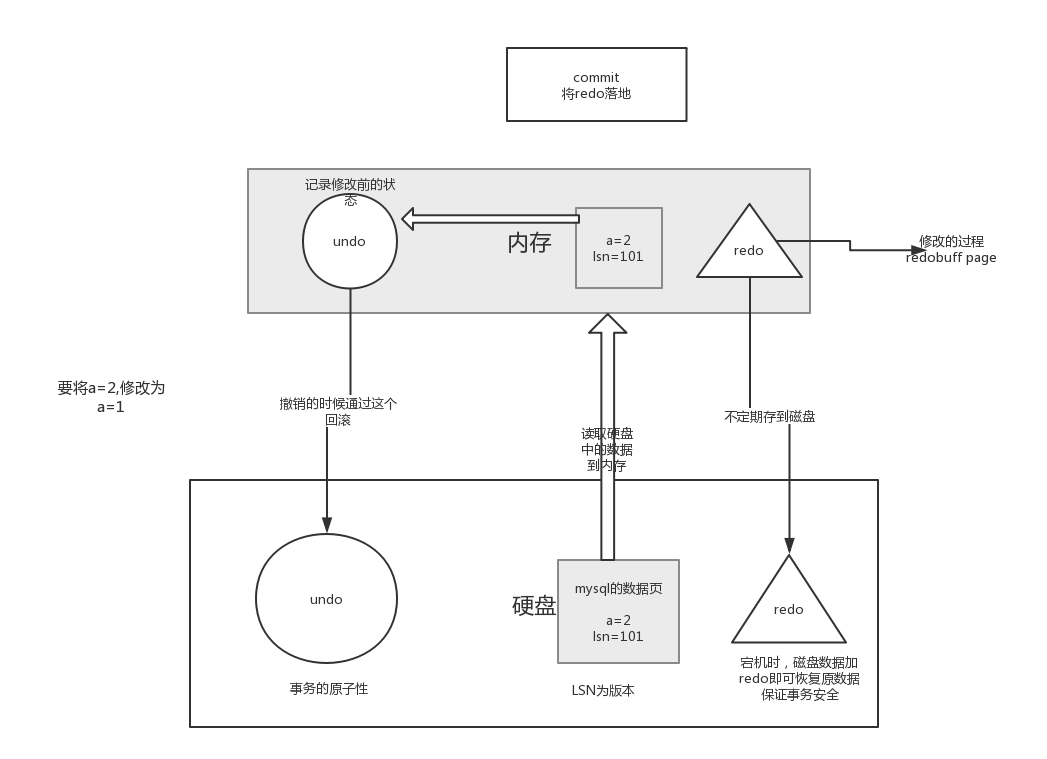
innodb事务日志包括redo.log和undo.log。
- redo.log是重做日志,提供前滚操作。
- undo.log是回滚日志,提供回滚操作。
undo.log不是redo.log的逆向过程,其实它们都算是用来恢复的日志:
- redo log通常是物理日志,记录的是数据页的物理修改,而不是某一行或某几行修改成怎样怎样,它用来恢复提交后的物理数据页(恢复数据页,且只能恢复到最后一次提交的位置)。
- undo用来回滚行记录到某个版本。undo log一般是逻辑日志,根据每行记录进行记录。
2.二进制日志 (binlog,逻辑型日志)
作用
记录所有变更类的语句
DDL,DCL :以语句方式(statement)记录
DML(已提交的事务语句):默认是以行模式记录(row模式,数据行的变化)
可以做数据恢复和操作的审计
操作
# 二进制日志默认不开启
# 需要配置到my.cnf配置文件
log_bin=/opt/mysql/data/mysql-bin
binlog_format=row # 日志格式 row格式可以避免MYSQL复制中出现主从不一致的问题,官方推荐这种格式。
server_id=6
sync_binlog=1
# 查看日志信息
mysql> show binary logs;
mysql> show master status;
# 查看日志内容
# 按事件查看日志内容
mysql> show binlog events in 'mysql-bin.000012';
# 直接查看日志内容
mysql> mysqlbinlog --base64-output=decode-rows -vvv /opt/mysql/data/mysql-bin.000012 |more
# 截取二进制日志
# --start-position=219 起始位置
# --stop-position=186613 结束位置
# /opt/mysql/data/mysql-bin.000012 截取的日志
# >/tmp/binlog.sql 存放到sql文件
mysqlbinlog --start-position=219 --stop-position=186613 /opt/mysql/data/mysql-bin.000012 >/tmp/binlog.sql3.慢日志
MySQL的慢查询日志是MySQL提供的一种日志记录,它用来记录在MySQL中响应时间超过阀值的语句,通过慢查询日志,我们可以知道是那些语句的效率慢,可以去语句调优
# 配置my.cnf
slow_query_log=1 # 开启慢日志
slow_query_log_file=/opt/mysql/data/standby-slow.log # 存储位置
long_query_time=1 # 超过1秒会存入慢日志,默认是10秒
log_queries_not_using_indexes=1 # 不走索引的也认为是慢语句,默认关闭
# 使用Box Anemometer基于pt-query-digest将MySQL慢查询可视化四、备份
1.分类
- 逻辑备份:SQL语句的备份
- 物理备份:数据页备份
2.逻辑备份工具
# MySQL和redis之间如何顺滑的迁移数据
# 先把数据存到redis认识的文件,redis再从该文件读取
select xxxx from 表名 into outfile '/tmp/redis.txt'# 备份命令mysqldump格式
mysqldump -h主机名 -P端口 -u用户名 -p密码 –database 数据库名 > 文件名.sql
# -h本地可以省略
# -P默认3306也可以省略
# –database 指定数据库。如果有库名,–database可以省略;如果备份当前所在库,库名也可以省略
# -A 全库备份
mysqldump -uroot -p123 -A >/backup/full.sql
# -B 备份一个或多个指定库,会备份建库语句
# 不加-B也可以备份单库,但是却没有建库语句的
mysqldump -uroot -p123 -B world bbs >/backup/wb.sql
# 备份单库中的表
# world库中的city表、country表
mysqldump -uroot -p123 world city country >/backup/ccc.sql
# 其他参数,必写
--master-data=2 # 备份时记录二进制日志的状态
--single-transaction # 开启innodb热备功能
-R
--triggers
# 完整的备份语句
mysqldump -uroot -p123 -A --master-data=2 --single-transaction -R --triggers >/backup/full.sql
# 还原MySQL数据库的命令
mysql -h主机名 -P端口 -u用户名 -p密码 –database 数据库名 < 文件名.sql 五、主从复制
1.简介
Mysql作为目前世界上使用最广泛的免费数据库,相信所有从事系统运维的工程师都一定接触过。但在实际的生产环境中,由单台Mysql作为独立的数据库是完全不能满足实际需求的,比如数据库损坏,可以使用备份来恢复,但是效率不高,相比之下主从复制效率高、安全性更高
因此,一般来说都是通过 主从复制(Master-Slave)的方式来同步数据,再通过读写分离(MySQL-Proxy)来提升数据库的并发负载能力 这样的方案来进行部署与实施的。
2.原理
MySQL的主从复制是一个异步的复制过程,数据库从一个Master复制到Slave数据库,在Master与Slave之间实现整个主从复制的过程是由三个线程参与完成的,其中有两个线程(SQL线程和IO线程)在Slave端,另一个线程(IO线程)在Master端。
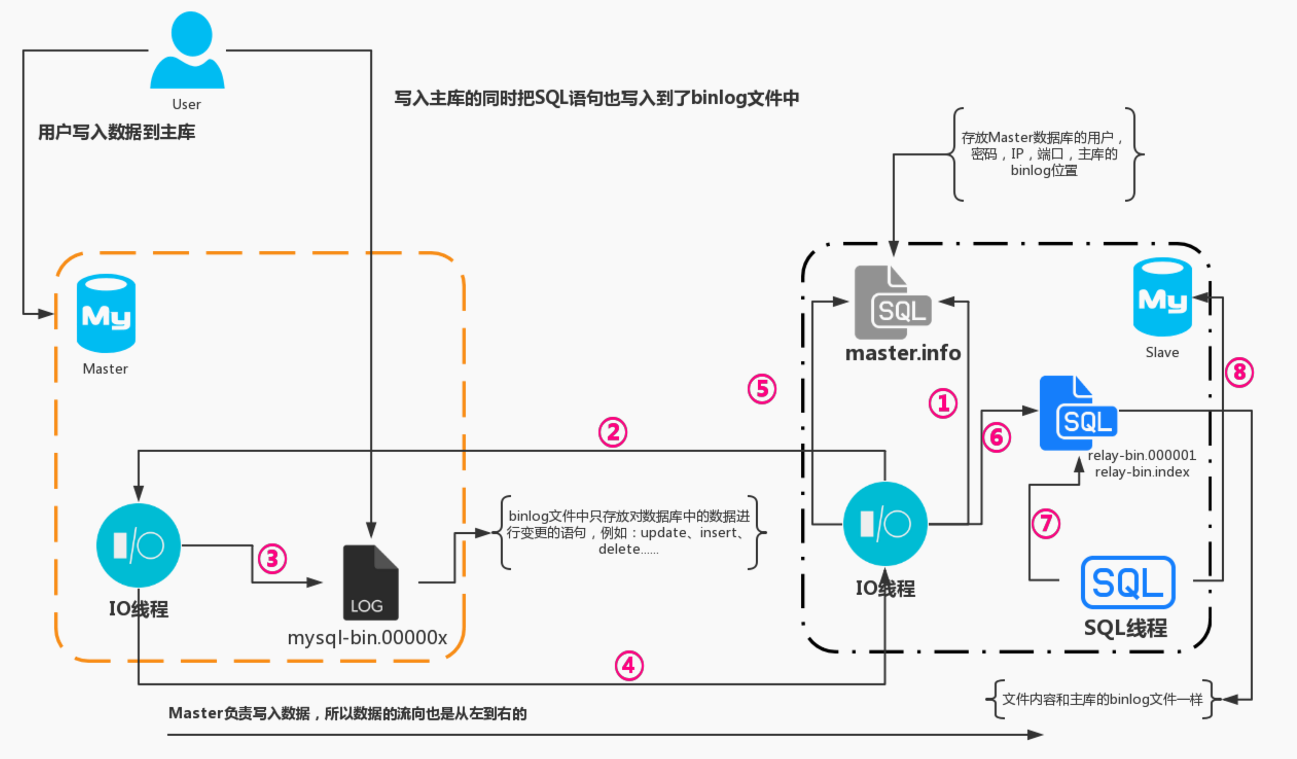
流程说明:
MySQL主从复制之前我们需要先启动Master数据库然后再启动Salve数据库,然后在Salve数据库中执行start slave;,执行完成之后,流程就如下了:
- Salve的IO线程会读取mastr.info文件中配置好的主库信息,比如说存放的有:Master数据库的用户名、密码、端口、还有Master的binlog索引位置;
- 拿到信息之后就带着信息去链接Master的主库IO线程
- 当主库的IO线程先检查SLave传过来的配置信息是否正确,如果正确,就拿着Slave传过来的binlog索引位置和Master库的binlog文件中最后一个索引位置进行对比,如果一致就陷入等待状态,等待Master的binlog索引位置更新;
- 如果不一致就把Slave传过来的binlog索引位置往后的所有SQL语句包括最后一条SQL语句的索引位置发送个给Slave的IO线程;
- Slave的IO线程拿到信息之后,先把Master传过来的binlog索引在Slave的master.info文件中进行更新;
- 然后再把Master传过来的SQL语句写入到relay文件中,然后继续循环执行第二个步骤;
- Slave的SQL线程会一直持续的观察relay日志文件中是否有改动,如果没有就继续监听;
- 如果发现relay中有变动,那么就获取变动的内容转换为SQL语句,并且把SQL语句在Salve的数据库中进行执行
3.实现主从复制
master机配置
Master slave
3307---->3308
# 1.由于,主从复制基于二进制日志,所以主库要开启二进制日志,修改配置并重启服务
vim /data/3307/my.cnf
log_bin=/data/3307/mysql-bin
systemctl restart mysqld3307
# 2.Master中创建复制用户
grant replication slave on *.* to repl@'10.0.0.%' identified by '123';
# 3.测试是否创建成功
show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 154 | | | |
+------------------+----------+--------------+------------------+-------------------+
slave机配置
# 1.再salve机配置对应master机的信息
mysql> CHANGE MASTER TO
MASTER_HOST='10.0.0.200', # master机IP
MASTER_USER='repl', # master机MySQL用户名
MASTER_PASSWORD='123', # mysql密码
MASTER_PORT=3307, # master机端口
MASTER_LOG_FILE='mysql-bin.000001',# 二进制日志的起始文件
MASTER_LOG_POS=154; # 二进制日志的起始位置
# 2.启动salve机服务
start slave;
# 3.测试salve机是否启动
show slave status\G
# 启动成功应当现实配置
。。。。。。
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
。。。。。。