Problem:
SegNet (TPAMI 2017) 官方release的代码是在Caffe框架下实现。但是需要对原Caffe代码进行改造,见 caffe-segnet-cudnn5 。而这份改造的Caffe本人在使用的时候遇到一个不太好用的地方:
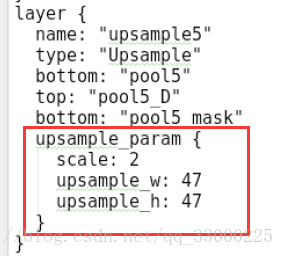
- 需要在.prototxt里指定上采样后的
upsample_w和upsample_h,如下图。这个做法是为了避免这种情况:在encoder,上一层的大小为奇数(比如107),经过pooling后下一层变成54;但在decoder,做2x的upsample,变成108,就与上一层的dims不一致。所以需要指定upsample_w/upsample_h为107。这样导致一个结果是,一旦都指定了upsample_w和upsample_h,就要求所有数据的input size都一致,这对于一些data size不完全一样的数据集(比如MS COCO)就比较麻烦了。
Solutions:
基于这个问题,我希望对于每一个mini-batch,网络能自动地做resize。而由于Upsample 层是原作者在Caffe里面新加的一个层,所有我们需要修改Caffe的c++源码。步骤如下:
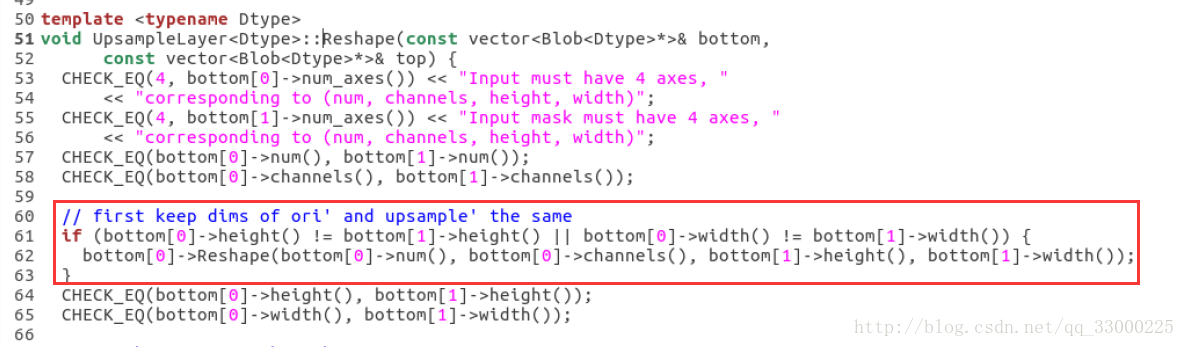
1、 定位到原作者新加的Upsample 层:include/caffe/layers/upsample_layer.hpp 与 src/caffe/layers/upsample_layer.cpp 。主要是.cpp里面的UpsampleLayer<Dtype>::Reshape 函数;
2、 研究这段代码发现,你只知道这一层的size,比如54,无法知道上一层是107。所以在这种情况下,只能先做2x的upsampling,变成108。这个size进入上一层,即size=107的层时,开头第5、6句CHECK_EQ 就会检测height和width是否一致,如果不一致就会报错,比如检测到bottom[0]->height()=108, bottom[1]->height()=107 ,所以在CHECK_EQ 之前,就对108 resize为107:
3、这之后,会遇到一个问题:这段代码是先resize使得dims一致,再upsampling,这样如果原图大小为427x640,那下一层是214x320。214x320的层upsampling成428x640后,就不会再进入这段代码,也就是不会resize到427x640。报错一般会像这样:
softmax_loss_layer.cpp:56] Check failed: outer_num_ *inner_num_ == bottom[1]->count() (273920 vs. 273280) Number of labels must match number of predictions; e.g., if softmax axis == 1 and prediction shape is (N, C, H, W), label count (number of labels) must be N*H*W, with integer values in {0, 1, …, C-1}.

这里提出一种解决方法:upsampling后,当发现size大于原图像大小,比如428>427,这明显就需要resize到427了。那如何判断是否大于原图像大小呢?只需把原图传入,在每个Upsample 层判断一下即可(因为除了最后的Upsample 层,其余的层肯定不会在upsampling后大于原图像大小)。原图传入只需在.prototxt里面作为Upsample 层的一个bottom 即可:

注意这里的5个Upsample 层都要添加bottom: "label" ,label 即是原大小的label_map。然后:

里面的bottom[2] 即是传入的 label ,代码的意思就是upsampling size为428时,发现大于427,那就把428设置为427。
另外,需要注意外层的if 判断跟之前的不一样,之前的 if (upsample_h_ <= 0 || upsample_w_ <= 0) 会导致upsample_h_ 和 upsample_w_ 在第一次改变之后,就不会根据不同的data size改变了。
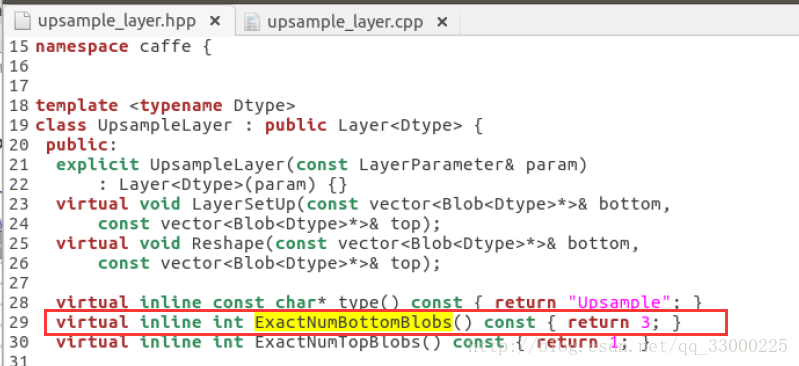
4、 这之后,还会遇到一个问题:
layer.hpp:374] Check failed: ExactNumBottomBlobs() == bottom.size() (2 vs. 3) Upsample Layer takes 2 bottom blob(s) as input.

定位到的问题是:由于我们在.prototxt里面加了一个bottom ,但是include/caffe/layers/upsample_layer.hpp 里面设置了:virtual inline int ExactNumBottomBlobs() const { return 2; } ,即定义bottom 数为2,所以改为3即可:
这样应该就可以了。
Summary
一共改3个地方:
include/caffe/layers/upsample_layer.hpp,一处改动,见上方- train/test .prototxt, 几处改动,见上方
src/caffe/layers/upsample_layer.cpp,主要是UpsampleLayer<Dtype>::Reshape函数,改动较多,下面放出此函数的全部代码:
template <typename Dtype>
void UpsampleLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
CHECK_EQ(4, bottom[0]->num_axes()) << "Input must have 4 axes, "
<< "corresponding to (num, channels, height, width)";
CHECK_EQ(4, bottom[1]->num_axes()) << "Input mask must have 4 axes, "
<< "corresponding to (num, channels, height, width)";
CHECK_EQ(bottom[0]->num(), bottom[1]->num());
CHECK_EQ(bottom[0]->channels(), bottom[1]->channels());
// first keep dims of ori' and upsample' the same
if (bottom[0]->height() != bottom[1]->height() || bottom[0]->width() != bottom[1]->width()) {
bottom[0]->Reshape(bottom[0]->num(), bottom[0]->channels(), bottom[1]->height(), bottom[1]->width());
}
CHECK_EQ(bottom[0]->height(), bottom[1]->height());
CHECK_EQ(bottom[0]->width(), bottom[1]->width());
// not has_upsample_h && has_upsample_w
if (!(this->layer_param_.upsample_param().has_upsample_h()
&& this->layer_param_.upsample_param().has_upsample_w())) {
upsample_h_ = bottom[0]->height() * scale_h_ - int(pad_out_h_);
upsample_w_ = bottom[0]->width() * scale_w_ - int(pad_out_w_);
if (upsample_h_ > bottom[2]->height() || upsample_w_ > bottom[2]->width()) {
upsample_h_ = bottom[2]->height();
upsample_w_ = bottom[2]->width();
}
}
//LOG(INFO) << "## upsample_h_ " << upsample_h_;
//LOG(INFO) << "## upsample_w_ " << upsample_w_;
//LOG(INFO) << "## bottom[2]->height() " << bottom[2]->height();
//LOG(INFO) << "## bottom[2]->width() " << bottom[2]->width();
// upsampling
top[0]->Reshape(bottom[0]->num(), bottom[0]->channels(), upsample_h_,
upsample_w_);
//LOG(INFO) << "## top[0]->height() " << top[0]->height();
//LOG(INFO) << "## top[0]->width() " << top[0]->width();
channels_ = bottom[0]->channels();
height_ = bottom[0]->height();
width_ = bottom[0]->width();
}References:
[1] Badrinarayanan, V., Kendall, A., Cipolla, R.: Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 39(12) (2017) 2481–2495
[2] SegNet官方代码:https://github.com/alexgkendall/SegNet-Tutorial
[3] caffe-segnet-cudnn5:https://github.com/TimoSaemann/caffe-segnet-cudnn5