版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/lantuxin/article/details/83339848
参考网站1:https://blog.csdn.net/jyl1999xxxx/article/details/58161181
参考网站2:https://blog.csdn.net/jiongnima/article/details/69736844
卷积层的原理直接一张图表示:
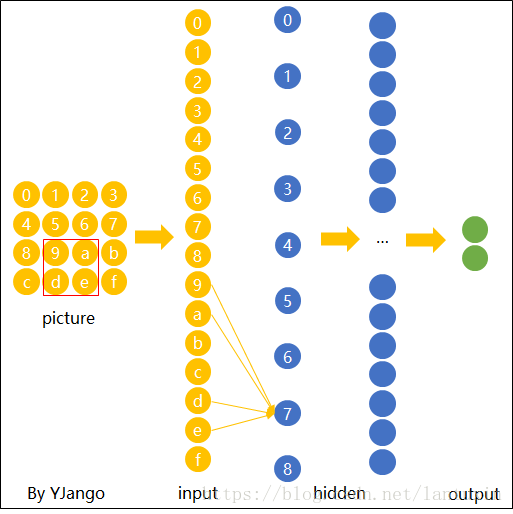
参考网站3:https://www.zhihu.com/question/28385679
caffe在实现过程中,将卷积转化为矩阵乘法实现,这张图说明:
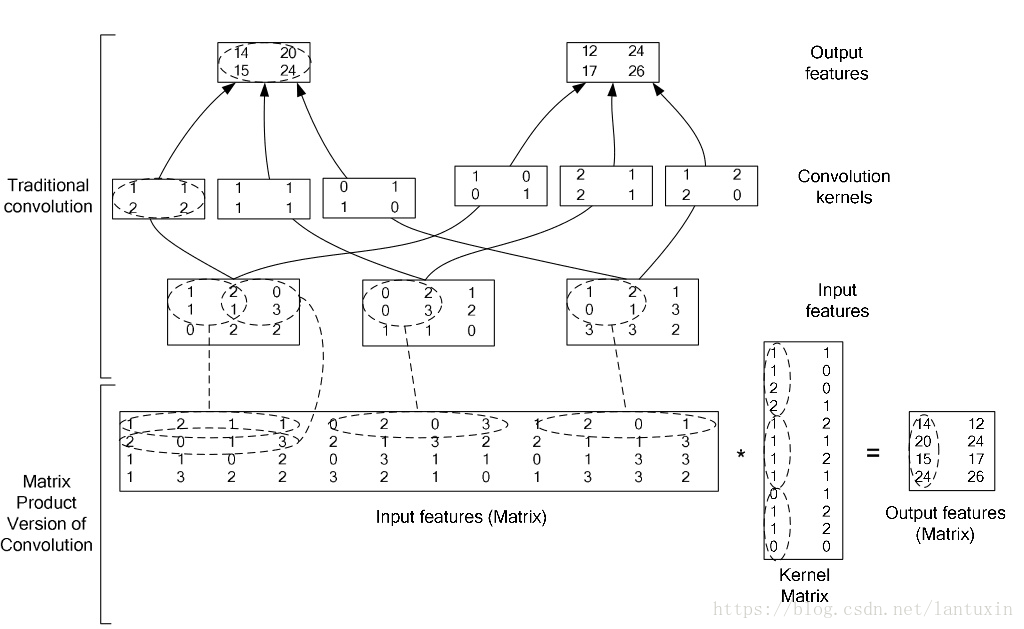
将图像像素值按照卷积核的H*W大小排成一列,卷积核自然也会被排成一列,这样计算卷积时,直接求内积就行了。(一句话:排成矩阵,求内积)
我关心的是如何将以上的思路转换成代码形式:
1)Forward_cpu前向传播
template <typename Dtype>
void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* weight = this->blobs_[0]->cpu_data();
//this->blobs_[0]自然表示的是这一层(卷积层)的权重,this->blobs_[1]表示这一层的偏置
for (int i = 0; i < bottom.size(); ++i) {
//bottom.size()是看一下有几个输入bottom,卷积层只有一个(所以bottom.size()=1),concat层就可以是多个
// LOG(INFO) <<"bottom's size:"<<bottom.size();
const Dtype* bottom_data = bottom[i]->cpu_data();
//bottom_data会指向bottom[i]的首地址,bottom[i]->cpu_data()表示不可以改变当前地址存放的输入数据的值,
//Forward_cpu中的bottom都不应该被改变
Dtype* top_data = top[i]->mutable_cpu_data();
//top_data自然指向的是top[i]的首地址,但top[i]->mutable_cpu_data()却表示可以改变当前地址处存放的数据,
// 很好理解,前向传播就是要修改输出top的值
for (int n = 0; n < this->num_; ++n) {
//this->num_表示batchsize,caffe处理数据是一次处理一个batch,每一个输入bottom下都会有各自的batch(如64张3通道的图)
// LOG(INFO) <<"image's num:"<<this->num_;
this->forward_cpu_gemm(bottom_data + n * this->bottom_dim_, weight,
top_data + n * this->top_dim_);
//this->bottom_dim_表示channel数×H×W
//程序卷积处理时,需要处理每一个batch下每一张图每一个channel的像素点
//所以处理每一个batch之后,存储点就需要向后移n * this->bottom_dim_的空间
if (this->bias_term_) {
const Dtype* bias = this->blobs_[1]->cpu_data();
this->forward_cpu_bias(top_data + n * this->top_dim_, bias);
}
}
}
}我觉得如果这个过程不看卷积原理,最重要的就是处理后的存储方式:一个一个batch进行处理,每次处理完一个batch,都需要把指针移动一个batch的长度,从bottom_data + n * this->bottom_dim_体现出来的。(这里使用batch的概念似乎有点不对,可能应该描述为对一个batch里面的一张图一张图进行处理)
2)Backward_cpu反向传播
template <typename Dtype>
void ConvolutionLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {
const Dtype* weight = this->blobs_[0]->cpu_data();
//this->blobs_[0]同样表示当前层(卷积层)的权重,指向当前层权重的首地址,但这里不可改变权重值
Dtype* weight_diff = this->blobs_[0]->mutable_cpu_diff();
//这里的weight_diff就可以用于改变当前卷积层的权重值了
for (int i = 0; i < top.size(); ++i) {
//top.size()当前卷积层的输出top个数,这里是1个,slice层就有多个
const Dtype* top_diff = top[i]->cpu_diff();
//top_diff指向下一层的传来的梯度首地址,不可更改
const Dtype* bottom_data = bottom[i]->cpu_data();
//bottom_data指向当前卷积层输入数据的首地址,不可更改
Dtype* bottom_diff = bottom[i]->mutable_cpu_diff();
//bottom_data指向当前卷积层输入数据的首地址,可更改
// Bias gradient, if necessary.
if (this->bias_term_ && this->param_propagate_down_[1]) {
//this->bias_term_判断是否有偏置项,
//this->param_propagate_down_[1]判断第1个blob参数(应该是偏置)是否需要计算梯度
Dtype* bias_diff = this->blobs_[1]->mutable_cpu_diff();
//bias_diff指向偏置梯度首地址,如果还没有计算,是否应该理解为分配用于存放偏置梯度的空间呢?
for (int n = 0; n < this->num_; ++n) {
// this->num_这里同样是batchsize
this->backward_cpu_bias(bias_diff, top_diff + n * this->top_dim_);
//this->top_dim_卷积层输出channel数×H×W,逐个batch进行计算
//这里top_diff + n * this->top_dim_是输入
// y=alpha*A*x+beta*y (y--bias_diff;A--top_diff + n * this->top_dim_)
}
}
if (this->param_propagate_down_[0] || propagate_down[i]) {
// 可以肯定了,this->param_propagate_down_[0]表示权重梯度是否需要计算
//propagate_down[i]表示这一层的第i个正向传播是否已经做完(Forward_cpu过程已经做完),
for (int n = 0; n < this->num_; ++n) {
// this->num_这里同样是batchsize
// gradient w.r.t. weight. Note that we will accumulate diffs.
if (this->param_propagate_down_[0]) {
// this->param_propagate_down_[0]再一次判断权重梯度是否需要计算
this->weight_cpu_gemm(bottom_data + n * this->bottom_dim_,
top_diff + n * this->top_dim_, weight_diff);
// C=alpha*A*B+beta*C
//(B--bottom_data + n * this->bottom_dim_)
//(A--top_diff + n * this->top_dim_)
//(C--weight_diff)
//对weight 计算导数(用来更新weight),这里相当于weight_diff=top_diff×bottom_data
//至于为什么?通过查看公式笔记得知,即https://blog.csdn.net/lantuxin/article/details/79725420中
//发现真的反向传播的偏导数就是这样算的。
}
// gradient w.r.t. bottom data, if necessary.
if (propagate_down[i]) {
this->backward_cpu_gemm(top_diff + n * this->top_dim_, weight,
bottom_diff + n * this->bottom_dim_);
// bottom_diff = top_diff * weight
}
}
}
}
}至于卷积的细节(包括怎么将图片按照矩阵方式存储,怎么卷积),参考网站1已经做了相当详细的代码注释!