背景
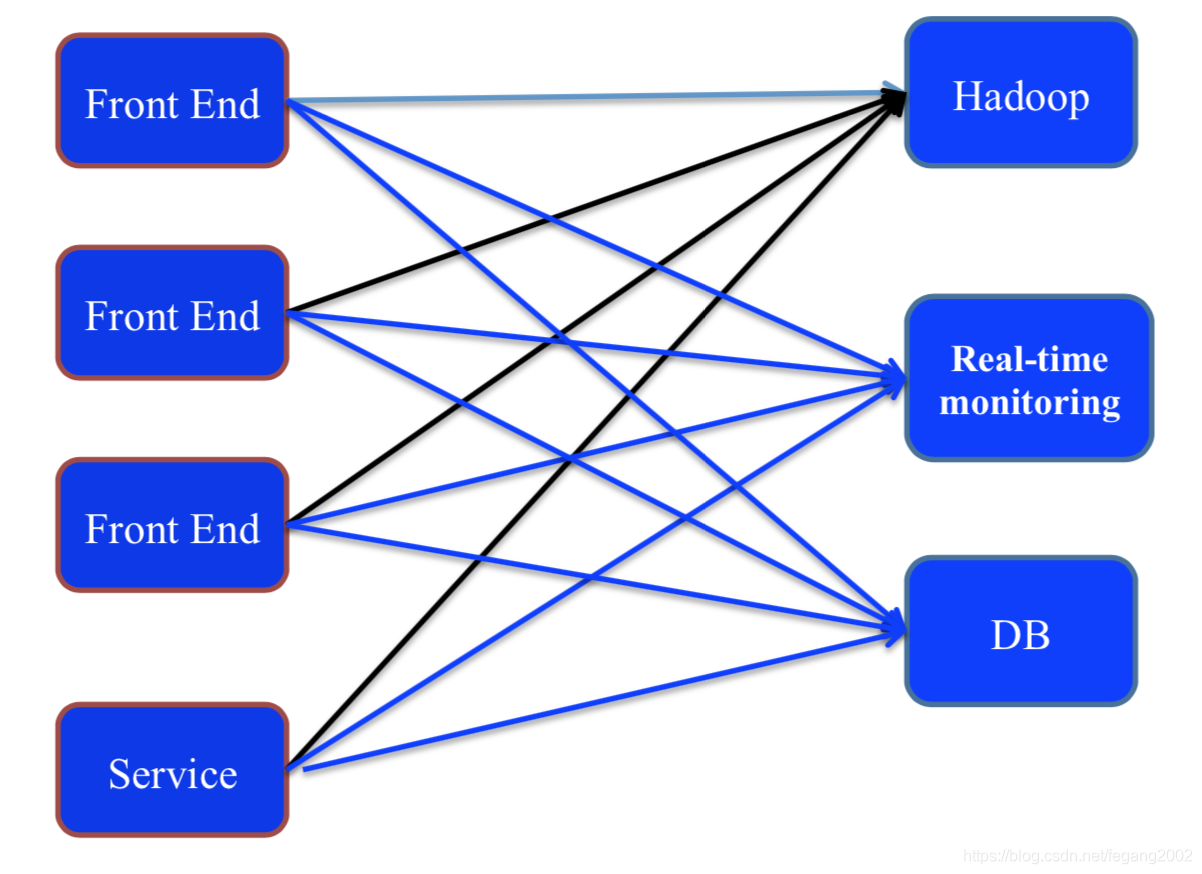 这种结构耦合性太高,后端一旦发生变化,前端就要改动。
这种结构耦合性太高,后端一旦发生变化,前端就要改动。
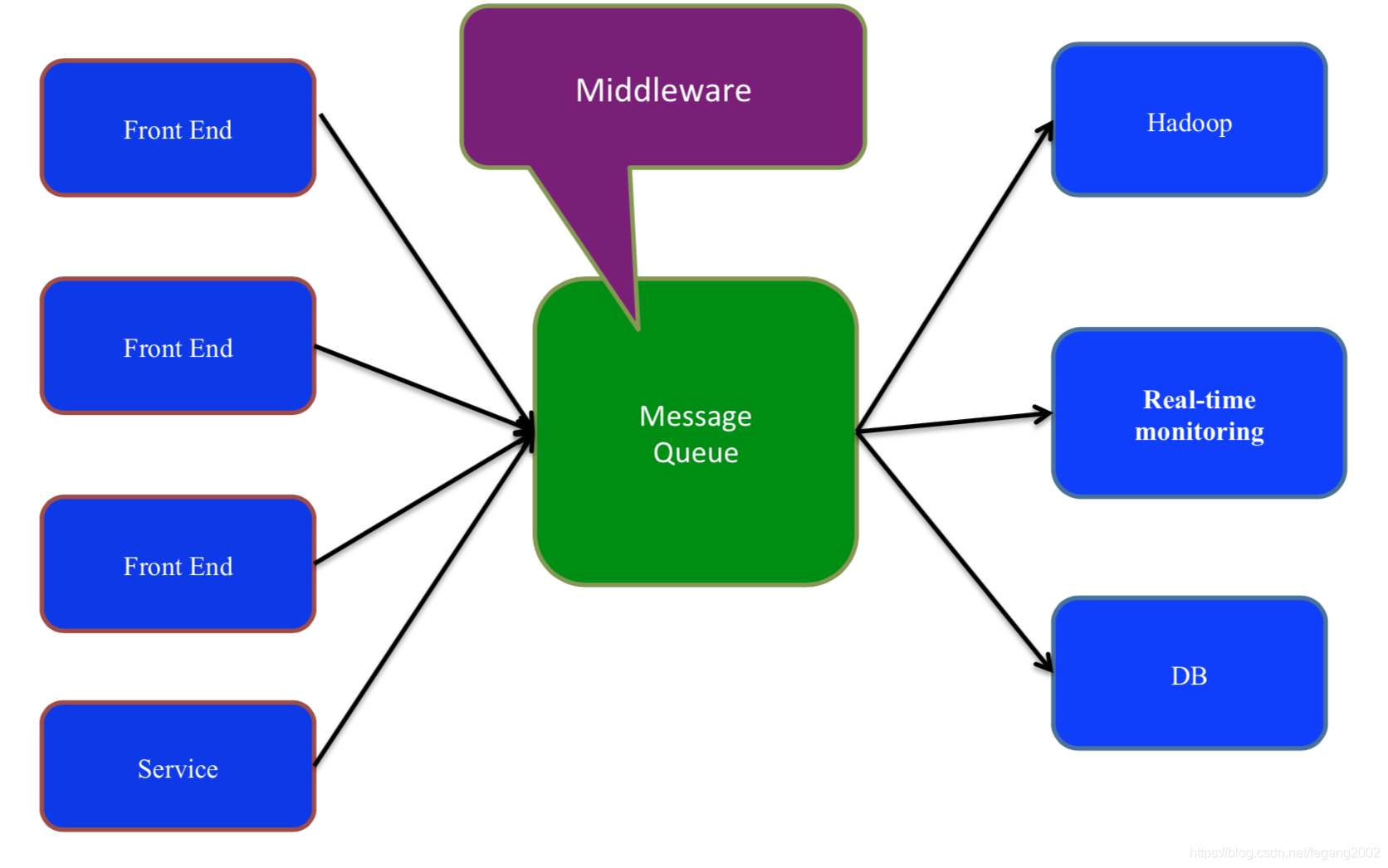 使用中间件进行解耦,提高扩展性,各种服务都把生成的数据或变化写到中间件,后端服务器根据需要获取数据或变化,同时当生产者生产的数据大于消费者消费的数据时提供了缓存机制。消息队列能够使关键组件顶住突发的访问压⼒力,而不会因为突发的超负荷的请求⽽而完全崩溃。
使用中间件进行解耦,提高扩展性,各种服务都把生成的数据或变化写到中间件,后端服务器根据需要获取数据或变化,同时当生产者生产的数据大于消费者消费的数据时提供了缓存机制。消息队列能够使关键组件顶住突发的访问压⼒力,而不会因为突发的超负荷的请求⽽而完全崩溃。
Kafka是LinkedIn开源的分布式发布-订阅消息系统,它是一种数据管道和消息队列,相当于数据分发中心。
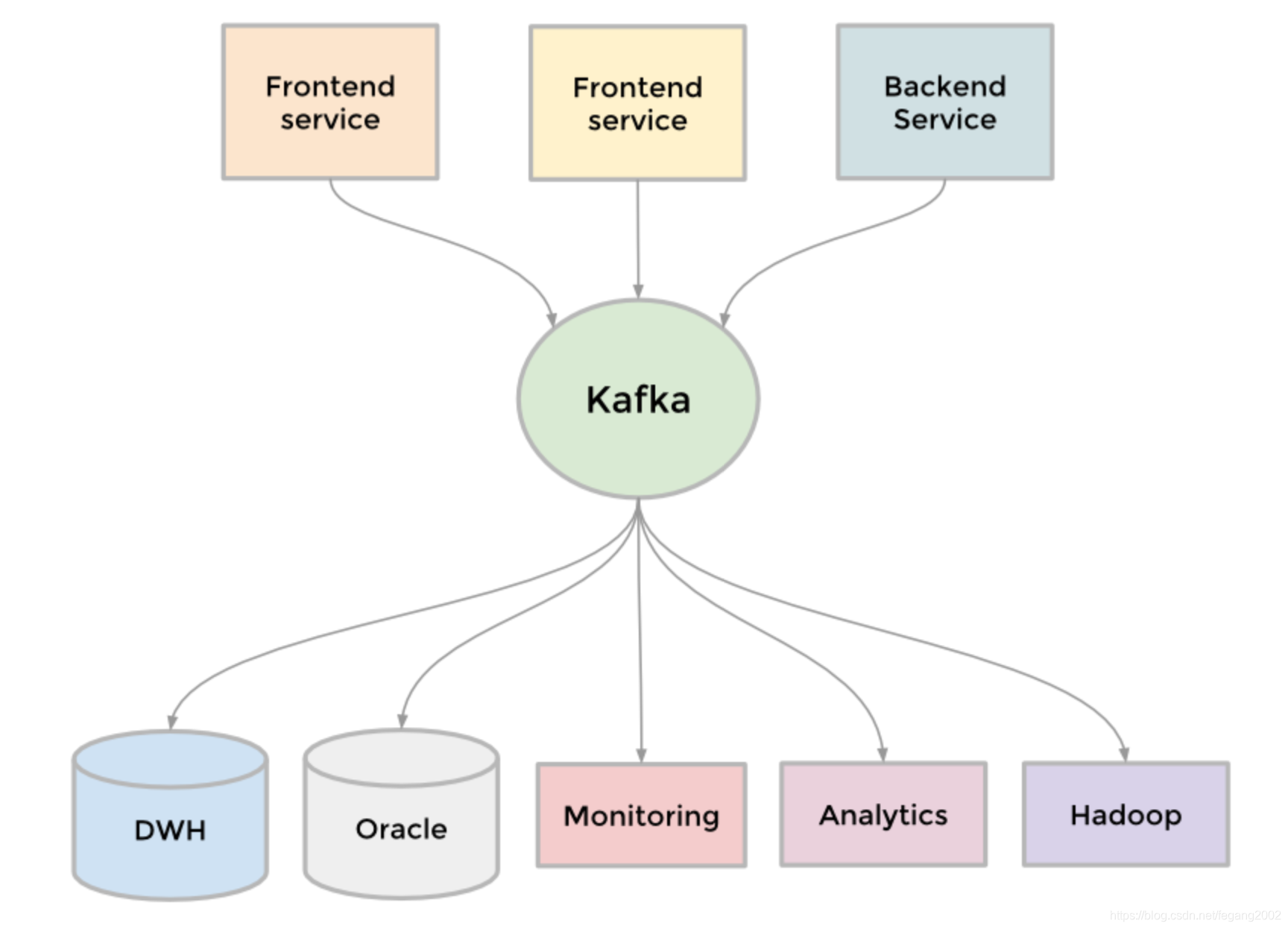 Kafka有如下特点:
Kafka有如下特点:
- ⾼高吞吐率、低延迟 :每秒处理几⼗万条消息,延迟最低⼏毫秒
- 可扩展性:支持动态扩展节点数据
- 持久性与可靠性:数据被持久化到磁盘上,支持数据多副本防⽌数据丢失
- 高容错 :允许节点失败
- 高并发:支持上千个客户端同时读写
Kafka原理
Kafka是一个生产者-消费者模型,Producer推数据,Consumer主动拉数据。
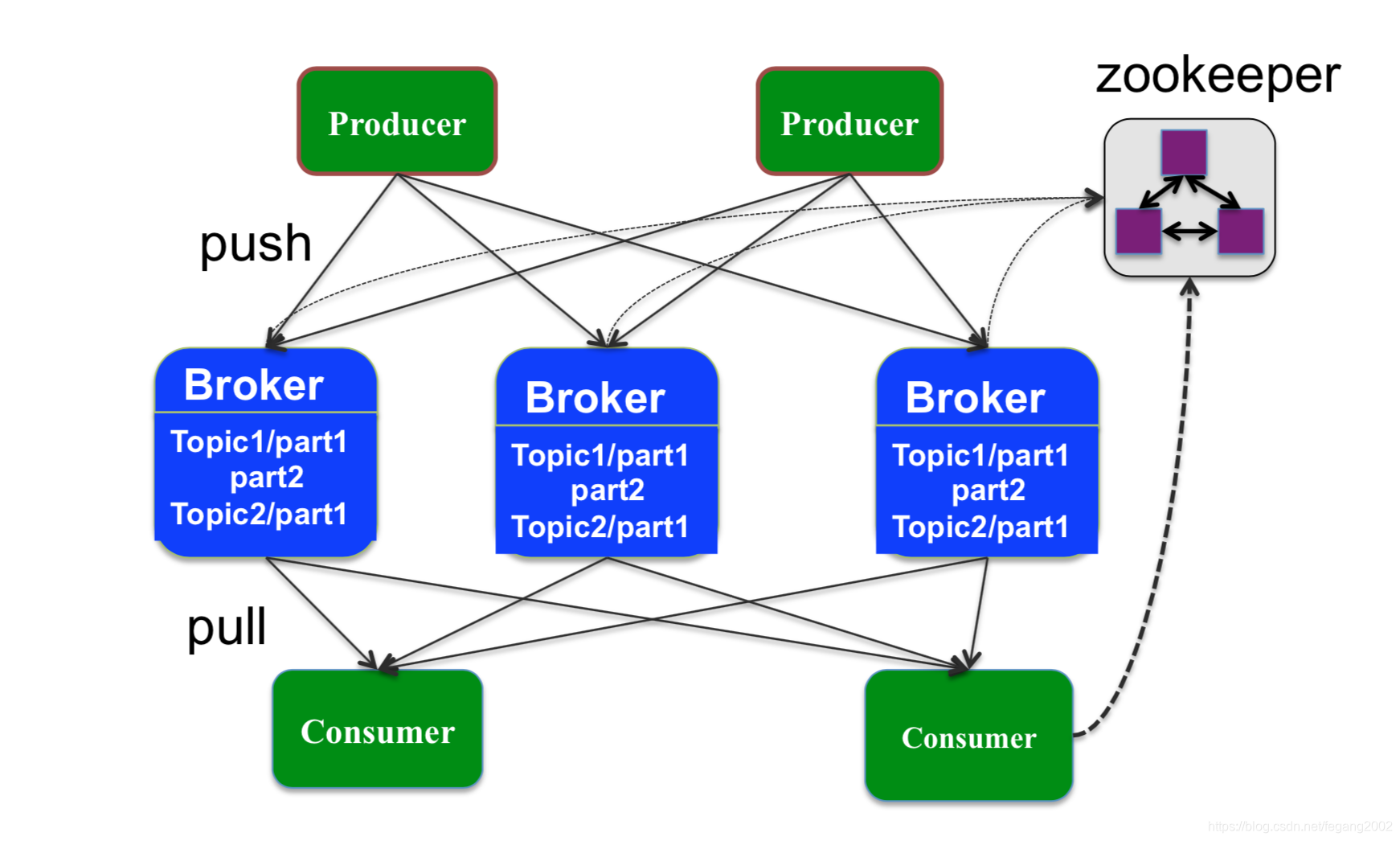
Producer是由用户编写的程序,有Kafka API支持。Kafka通过多个Broker实现,Broker里存储实际的数据,也是多副本,Broker不是Master和Slave架构,所以Broker需要通过Zookeeper做集群发现,所有的Broker都通过Zookeeper注册自己的信息,Broker都通过Zookeeper来获取其他Broker的地址信息。
- Producer
Producer向Broker发送消息,可通过任意⼀一个Broker发现其他Broker的位置信息。Producer只需要把信息发个任意一个Broker,Brokder就会把信息均匀的摊到其他的Broker上。
消息由Topic,Key,Value和Timestamp组成。
1)Topic:主题,数据的域或是组织方式,指消息属于哪一类,数据都是存在文件里,所以文件一般就是域或是命名空间,所以Topic一般是文件或是目录,标识数据存在哪些文件夹的文件里,一般主题和目录是等价的;
2)Key:可以重复,没有可以为空;
3)Value:键值;
4)Timestamp:时间戳,默认为写入的时间。 - Broker
Broker是Producer 和 Consumer之间的桥梁,从Producer端接收消息,并保存下来,将消息发送给订阅的Consumer。Broker可将消息可靠地缓存一段时间,每个消息保存成多副本(默认是3) ,保存时间可设置(默认一周)。
Broker由Partition和Topic组成,Topic是用户划分消息的逻辑概念,一个Topic可以分布到不同Broker上 。Partition是Kafka横向扩展和一切并行化的基础,每个Topic至少被切 分成1个Partition,消息在Partition中是有编号的,称为“Offset”。Kafka以Partition为单位对消息进行备份(replica),每 个Partition可以配置至少有1个replica。
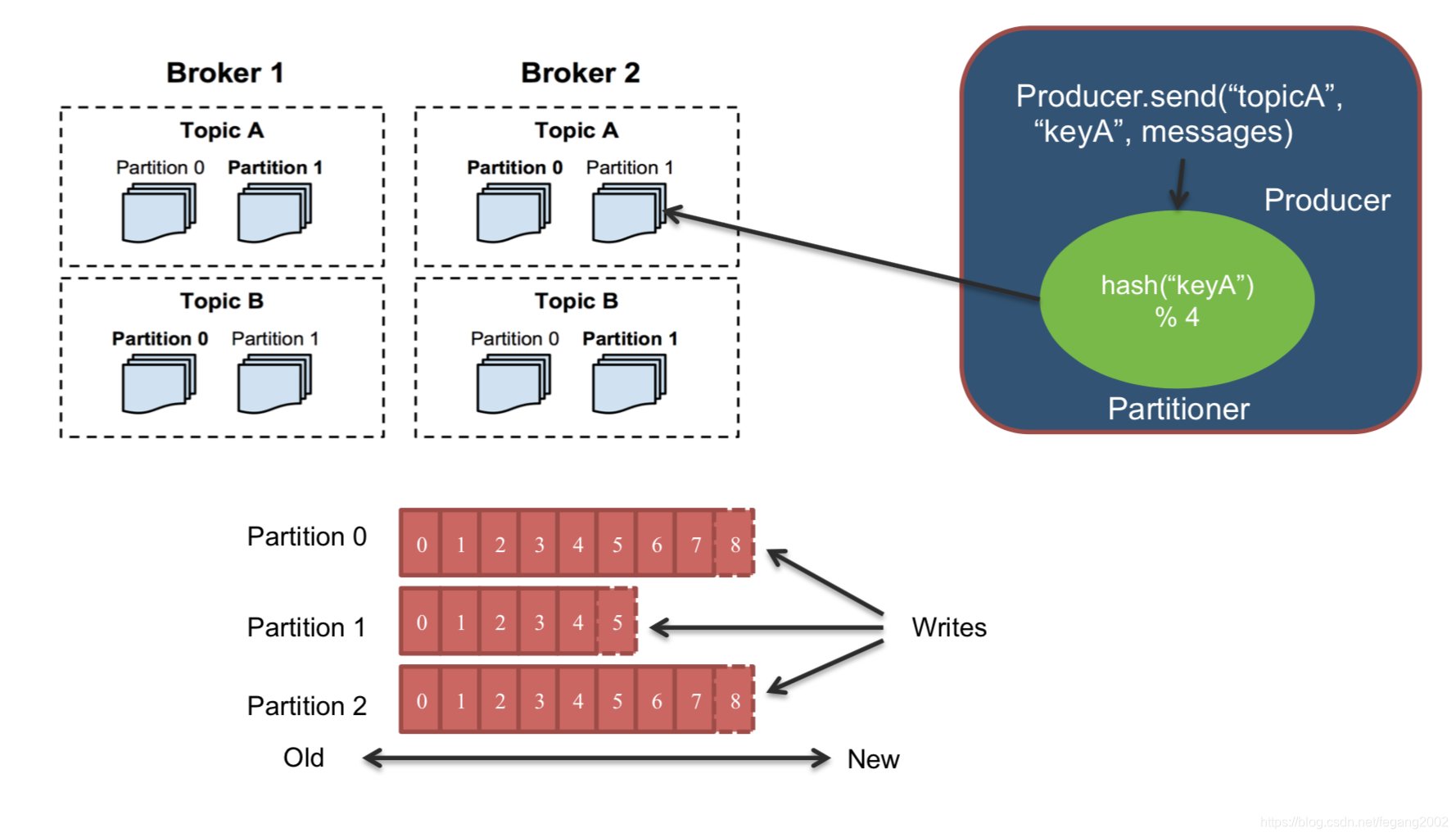
两个Brokder可能是在两台服务器上,每个Broker又分TopicA和TopicB,每个Topic又分不同的分区Partition,Partition相当于HDFS中的Blog,分区有助于并行处理,以及容错,当一个Partition挂了,只需要通过副本恢复这个Partition。所以,Kafka将数据切分成不同的Topic放到不同的节点上,副本数可以设置。
Producer发送数据:先对Key求hash,产生一个64位的数,然后模4(当有四个Partition的时候)后分别分配给四个Partition。按照Partition的时序在后面追加数据,不能保证Topic级别的时序,Counsumer读数据也是按照Partition的时序。因为是按照Key取模,所以Topic内是有序的,整体(Topic之间)是无序的。
如果要实现先写TopicA,再写TopicB,然后先读TopicA,再读TopicB,只需要Topic不分区就好,每个Topic只有一个Partition。所以Kafka只能保证同一个域内的数据有序,整体是无序的。 - Consumer
Consumer是用户编写的应用程序,负责从Kafka中读取数据,并进⾏处理,多个Consumer可形成⼀个Group,同时读取某个Topic,每个Consumer读取一个或多个Partition。每个Consumer自己维护读取的位置(offset),一旦挂掉后,重启可继续读取。一个Topic如果有四个分区,可以做四个Consumer并行的从这个Topic读数据,每个Consumer读一个Partition。Kafka是一个log-based的消息队列,数据有一定的时限性,超过了就删除,就没法读了。
Kafka服务保证
- 顺序保证
同一个Producer发送到某个Topic的同一Partition中的消息是顺序的,Consumer按照消息在日志中的写入顺序读取消息; - 容错性
如果消息的副本数是N,则N-1台机器宕掉后不会导致数据丢失。