转自:[https://studygolang.com/articles/7734]
本文针对的go版本是截止2016年6月29日最新的Go1.7。
一、Golang简介
1.1概述
Golang语言是Google公司开发的新一代编程语言,简称Go语言,Go 是有表达力、简洁、清晰和有效率的。它的并行机制使其很容易编写多核和网络应用,而新奇的类型系统允许构建有弹性的模块化程序。 Go 编译到机器码非常快速,同时具有便利的垃圾回收和强大的运行时反射。而他最广为人知的特性便是语言层面上对多核编程的支持,他有简单的关键字go来实现并行,就像下面这样:
Go的并行单元并不是传统意义上的线程,线程切换需要很大的上下文,这种切换消耗了大量CPU时间,而Go采用更轻量的协程(goroutine)来处理,大大提高了并行度,被称为“最并行的语言”。最近引起容器技术浪潮的Docker就是Go写的。由于GC穿插在goroutine之中,但是本篇文章并不讨论GC相关内容,故略过GC,主要讨论goroutine的调度问题。本文针对的go版本是截止2016年6月29日最新的Go1.7。
1.2与其他并发模型的对比
Python等解释性语言采用的是多进程并发模型,进程的上下文是最大的,所以切换耗费巨大,同时由于多进程通信只能用socket通讯,或者专门设置共享内存,给编程带来了极大的困扰与不便;
C++等语言通常会采用多线程并发模型,相比进程,线程的上下文要小很多,而且多个线程之间本来就是共享内存的,所以编程相比要轻松很多。但是线程的启动和销毁,切换依然要耗费大量CPU时间;
于是出现了线程池技术,将线程先储存起来,保持一定的数量,来避免频繁开启/关闭线程的时间消耗,但是这种初级的技术存在一些问题,比如有线程一直被IO阻塞,这样的话这个线程一直占据着坑位,导致后面的任务排不到队,拿不到线程来执行;
而Go的并发较为复杂,Go采用了更轻量的数据结构来代替线程,这种数据结构相比线程更轻量,他有自己的栈,切换起来更快。然而真正执行并发的还是线程,Go通过调度器将goroutine调度到线程中执行,并适时地释放和创建新的线程,并且当一个正在运行的goroutine进入阻塞(常见场景就是等待IO)时,将其脱离占用的线程,将其他准备好运行的goroutine放在该线程上执行。通过较为复杂的调度手段,使得整个系统获得极高的并行度同时又不耗费大量的CPU资源。
1.3 Goroutine的特点
Goroutine的引入是为了方便高并发程序的编写。一个Goroutine在进行阻塞操作(比如系统调用)时,会把当前线程中的其他Goroutine移交到其他线程中继续执行,从而避免了整个程序的阻塞。
由于Golang引入了垃圾回收(gc),在执行gc时就要求Goroutine是停止的。通过自己实现调度器,就可以方便的实现该功能。 通过多个Goroutine来实现并发程序,既有异步IO的优势,又具有多线程、多进程编写程序的便利性。
引入Goroutine,也意味着引入了极大的复杂性。一个Goroutine既要包含要执行的代码,又要包含用于执行该代码的栈和PC、SP指针。
既然每个Goroutine都有自己的栈,那么在创建Goroutine时,就要同时创建对应的栈。Goroutine在执行时,栈空间会不停增长。栈通常是连续增长的,由于每个进程中的各个线程共享虚拟内存空间,当有多个线程时,就需要为每个线程分配不同起始地址的栈。这就需要在分配栈之前先预估每个线程栈的大小。如果线程数量非常多,就很容易栈溢出。
为了解决这个问题,就有了Split Stacks 技术:创建栈时,只分配一块比较小的内存,如果进行某次函数调用导致栈空间不足时,就会在其他地方分配一块新的栈空间。新的空间不需要和老的栈空间连续。函数调用的参数会拷贝到新的栈空间中,接下来的函数执行都在新栈空间中进行。
Golang的栈管理方式与此类似,但是为了更高的效率,使用了连续栈( Golang连续栈) 实现方式也是先分配一块固定大小的栈,在栈空间不足时,分配一块更大的栈,并把旧的栈全部拷贝到新栈中。这样避免了Split Stacks方法可能导致的频繁内存分配和释放。
Goroutine的执行是可以被抢占的。如果一个Goroutine一直占用CPU,长时间没有被调度过,就会被runtime抢占掉,把CPU时间交给其他Goroutine。
二、 具体实现
2.1概念:
M:指go中的工作者线程,是真正执行代码的单元;
P:是一种调度goroutine的上下文,goroutine依赖于P进行调度,P是真正的并行单元;
G:即goroutine,是go语言中的一段代码(以一个函数的形式展现),最小的并行单元;
P必须绑定在M上才能运行,M必须绑定了P才能运行,而一般情况下,最多有MAXPROCS(通常等于CPU数量)个P,但是可能有很多个M,真正运行的只有绑定了M的P,所以P是真正的并行单元。

每个P有一个自己的runnableG队列,可以从里面拿出一个G来运行,同时也有一个全局的runnable G队列,G通过P依附在M上面执行。不单独使用全局的runnable G队列的原因是,分布式的队列有利于减小临界区大小,想一想多个线程同时请求可用的G的时候,如果只有全局的资源,那么这个全局的锁会导致多少线程一直在等待。
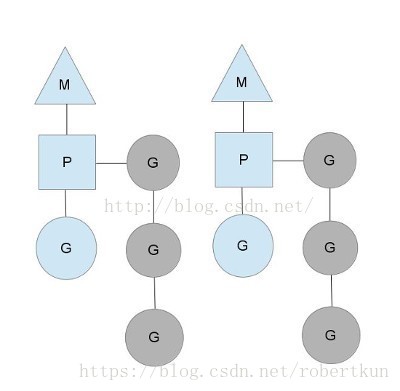
但是如果一个正在执行的G进入了阻塞,典型的例子就是等待IO,那么他和它所在的M会在那边等待,而上下文P会传递到其他可用的M上面,这样这个阻塞就不会影响程序的并行度。
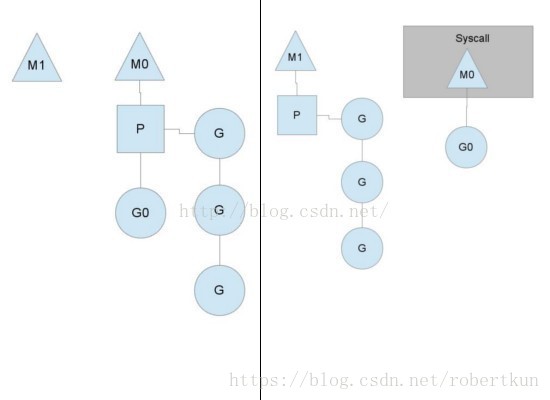
2.2 框架图
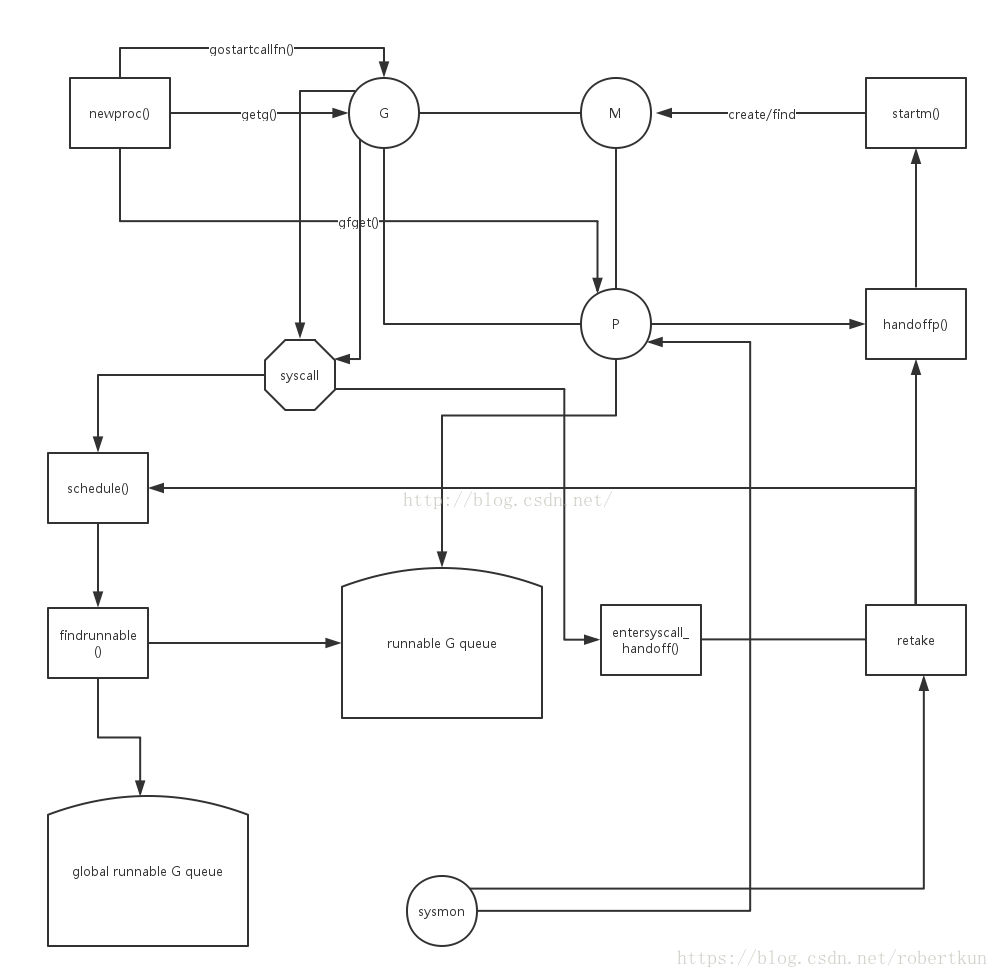
2.3具体函数
goroutine调度器的代码在/src/runtime/proc.go中,一些比较关键的函数分析如下。
1.schedule函数
schedule函数在runtime需要进行调度时执行,为当前的P寻找一个可以运行的G并执行它,寻找顺序如下:
1) 调用runqget函数来从P自己的runnable G队列中得到一个可以执行的G;
2) 如果1)失败,则调用findrunnable函数去寻找一个可以执行的G;
3) 如果2)也没有得到可以执行的G,那么结束调度,从上次的现场继续执行。
// One round of scheduler: find a runnable goroutine and execute it.
// Never returns.
func schedule() {
_g_ := getg()
if _g_.m.locks != 0 {
throw("schedule: holding locks")
}
if _g_.m.lockedg != nil {
stoplockedm()
execute(_g_.m.lockedg, false) // Never returns.
}
top:
if sched.gcwaiting != 0 {
gcstopm()
goto top
}
if _g_.m.p.ptr().runSafePointFn != 0 {
runSafePointFn()
}
var gp *g
var inheritTime bool
if trace.enabled || trace.shutdown {
gp = traceReader()
if gp != nil {
casgstatus(gp, _Gwaiting, _Grunnable)
traceGoUnpark(gp, 0)
}
}
if gp == nil && gcBlackenEnabled != 0 {
gp = gcController.findRunnableGCWorker(_g_.m.p.ptr())
}
if gp == nil {
// Check the global runnable queue once in a while to ensure fairness.
// Otherwise two goroutines can completely occupy the local runqueue
// by constantly respawning each other.
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
if gp != nil && _g_.m.spinning {
throw("schedule: spinning with local work")
}
}
if gp == nil {
gp, inheritTime = findrunnable() // blocks until work is available
}
// This thread is going to run a goroutine and is not spinning anymore,
// so if it was marked as spinning we need to reset it now and potentially
// start a new spinning M.
if _g_.m.spinning {
resetspinning()
}
if gp.lockedm != nil {
// Hands off own p to the locked m,
// then blocks waiting for a new p.
startlockedm(gp)
goto top
}
execute(gp, inheritTime)
}2.findrunnable函数
findrunnable函数负责给一个P寻找可以执行的G,它的寻找顺序如下:
1) 调用runqget函数来从P自己的runnable G队列中得到一个可以执行的G;
2) 如果1)失败,调用globrunqget函数从全局runnableG队列中得到一个可以执行的G;
3) 如果2)失败,调用netpoll(非阻塞)函数取一个异步回调的G;
4) 如果3)失败,尝试从其他P那里偷取一半数量的G过来;
5) 如果4)失败,再次调用globrunqget函数从全局runnableG队列中得到一个可以执行的G;
6) 如果5)失败,调用netpoll(阻塞)函数取一个异步回调的G;
7) 如果6)仍然没有取到G,那么调用stopm函数停止这个M。
// Finds a runnable goroutine to execute.
// Tries to steal from other P's, get g from global queue, poll network.
func findrunnable() (gp *g, inheritTime bool) {
_g_ := getg()
// The conditions here and in handoffp must agree: if
// findrunnable would return a G to run, handoffp must start
// an M.
top:
_p_ := _g_.m.p.ptr()
if sched.gcwaiting != 0 {
gcstopm()
goto top
}
if _p_.runSafePointFn != 0 {
runSafePointFn()
}
if fingwait && fingwake {
if gp := wakefing(); gp != nil {
ready(gp, 0, true)
}
}
if *cgo_yield != nil {
asmcgocall(*cgo_yield, nil)
}
// local runq
if gp, inheritTime := runqget(_p_); gp != nil {
return gp, inheritTime
}
// global runq
if sched.runqsize != 0 {
lock(&sched.lock)
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
if gp != nil {
return gp, false
}
}
// Poll network.
// This netpoll is only an optimization before we resort to stealing.
// We can safely skip it if there a thread blocked in netpoll already.
// If there is any kind of logical race with that blocked thread
// (e.g. it has already returned from netpoll, but does not set lastpoll yet),
// this thread will do blocking netpoll below anyway.
if netpollinited() && sched.lastpoll != 0 {
if gp := netpoll(false); gp != nil { // non-blocking
// netpoll returns list of goroutines linked by schedlink.
injectglist(gp.schedlink.ptr())
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
}
// Steal work from other P's.
procs := uint32(gomaxprocs)
if atomic.Load(&sched.npidle) == procs-1 {
// Either GOMAXPROCS=1 or everybody, except for us, is idle already.
// New work can appear from returning syscall/cgocall, network or timers.
// Neither of that submits to local run queues, so no point in stealing.
goto stop
}
// If number of spinning M's >= number of busy P's, block.
// This is necessary to prevent excessive CPU consumption
// when GOMAXPROCS>>1 but the program parallelism is low.
if !_g_.m.spinning && 2*atomic.Load(&sched.nmspinning) >= procs-atomic.Load(&sched.npidle) {
goto stop
}
if !_g_.m.spinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
for i := 0; i < 4; i++ {
for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() {
if sched.gcwaiting != 0 {
goto top
}
stealRunNextG := i > 2 // first look for ready queues with more than 1 g
if gp := runqsteal(_p_, allp[enum.position()], stealRunNextG); gp != nil {
return gp, false
}
}
}
stop:
// We have nothing to do. If we're in the GC mark phase, can
// safely scan and blacken objects, and have work to do, run
// idle-time marking rather than give up the P.
if gcBlackenEnabled != 0 && _p_.gcBgMarkWorker != 0 && gcMarkWorkAvailable(_p_) {
_p_.gcMarkWorkerMode = gcMarkWorkerIdleMode
gp := _p_.gcBgMarkWorker.ptr()
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
// return P and block
lock(&sched.lock)
if sched.gcwaiting != 0 || _p_.runSafePointFn != 0 {
unlock(&sched.lock)
goto top
}
if sched.runqsize != 0 {
gp := globrunqget(_p_, 0)
unlock(&sched.lock)
return gp, false
}
if releasep() != _p_ {
throw("findrunnable: wrong p")
}
pidleput(_p_)
unlock(&sched.lock)
// Delicate dance: thread transitions from spinning to non-spinning state,
// potentially concurrently with submission of new goroutines. We must
// drop nmspinning first and then check all per-P queues again (with
// #StoreLoad memory barrier in between). If we do it the other way around,
// another thread can submit a goroutine after we've checked all run queues
// but before we drop nmspinning; as the result nobody will unpark a thread
// to run the goroutine.
// If we discover new work below, we need to restore m.spinning as a signal
// for resetspinning to unpark a new worker thread (because there can be more
// than one starving goroutine). However, if after discovering new work
// we also observe no idle Ps, it is OK to just park the current thread:
// the system is fully loaded so no spinning threads are required.
// Also see "Worker thread parking/unparking" comment at the top of the file.
wasSpinning := _g_.m.spinning
if _g_.m.spinning {
_g_.m.spinning = false
if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 {
throw("findrunnable: negative nmspinning")
}
}
// check all runqueues once again
for i := 0; i < int(gomaxprocs); i++ {
_p_ := allp[i]
if _p_ != nil && !runqempty(_p_) {
lock(&sched.lock)
_p_ = pidleget()
unlock(&sched.lock)
if _p_ != nil {
acquirep(_p_)
if wasSpinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
goto top
}
break
}
}
// Check for idle-priority GC work again.
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(nil) {
lock(&sched.lock)
_p_ = pidleget()
if _p_ != nil && _p_.gcBgMarkWorker == 0 {
pidleput(_p_)
_p_ = nil
}
unlock(&sched.lock)
if _p_ != nil {
acquirep(_p_)
if wasSpinning {
_g_.m.spinning = true
atomic.Xadd(&sched.nmspinning, 1)
}
// Go back to idle GC check.
goto stop
}
}
// poll network
if netpollinited() && atomic.Load(&netpollWaiters) > 0 && atomic.Xchg64(&sched.lastpoll, 0) != 0 {
if _g_.m.p != 0 {
throw("findrunnable: netpoll with p")
}
if _g_.m.spinning {
throw("findrunnable: netpoll with spinning")
}
gp := netpoll(true) // block until new work is available
atomic.Store64(&sched.lastpoll, uint64(nanotime()))
if gp != nil {
lock(&sched.lock)
_p_ = pidleget()
unlock(&sched.lock)
if _p_ != nil {
acquirep(_p_)
injectglist(gp.schedlink.ptr())
casgstatus(gp, _Gwaiting, _Grunnable)
if trace.enabled {
traceGoUnpark(gp, 0)
}
return gp, false
}
injectglist(gp)
}
}
stopm()
goto top
}3.newproc函数
newproc函数负责创建一个可以运行的G并将其放在当前的P的runnable G队列中,它是类似”go func() { … }”语句真正被编译器翻译后的调用,核心代码在newproc1函数。这个函数执行顺序如下:
1) 获得当前的G所在的 P,然后从free G队列中取出一个G;
2) 如果1)取到则对这个G进行参数配置,否则新建一个G;
3) 将G加入P的runnable G队列。
// Create a new g running fn with siz bytes of arguments.
// Put it on the queue of g's waiting to run.
// The compiler turns a go statement into a call to this.
// Cannot split the stack because it assumes that the arguments
// are available sequentially after &fn; they would not be
// copied if a stack split occurred.
//go:nosplit
func newproc(siz int32, fn *funcval) {
argp := add(unsafe.Pointer(&fn), sys.PtrSize)
pc := getcallerpc(unsafe.Pointer(&siz))
systemstack(func() {
newproc1(fn, (*uint8)(argp), siz, 0, pc)
})
}4.goexit0函数
goexit函数是当G退出时调用的。这个函数对G进行一些设置后,将它放入free G列表中,供以后复用,之后调用schedule函数调度。
// goexit continuation on g0.
func goexit0(gp *g) {
_g_ := getg()
casgstatus(gp, _Grunning, _Gdead)
if isSystemGoroutine(gp) {
atomic.Xadd(&sched.ngsys, -1)
}
gp.m = nil
gp.lockedm = nil
_g_.m.lockedg = nil
gp.paniconfault = false
gp._defer = nil // should be true already but just in case.
gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data.
gp.writebuf = nil
gp.waitreason = ""
gp.param = nil
gp.labels = nil
gp.timer = nil
// Note that gp's stack scan is now "valid" because it has no
// stack.
gp.gcscanvalid = true
dropg()
if _g_.m.locked&^_LockExternal != 0 {
print("invalid m->locked = ", _g_.m.locked, "\n")
throw("internal lockOSThread error")
}
_g_.m.locked = 0
gfput(_g_.m.p.ptr(), gp)
schedule()
}5.handoffp函数
handoffp函数将P从系统调用或阻塞的M中传递出去,如果P还有runnable G队列,那么新开一个M,调用startm函数,新开的M不空旋。
// Hands off P from syscall or locked M.
// Always runs without a P, so write barriers are not allowed.
//go:nowritebarrierrec
func handoffp(_p_ *p) {
// handoffp must start an M in any situation where
// findrunnable would return a G to run on _p_.
// if it has local work, start it straight away
if !runqempty(_p_) || sched.runqsize != 0 {
startm(_p_, false)
return
}
// if it has GC work, start it straight away
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(_p_) {
startm(_p_, false)
return
}
// no local work, check that there are no spinning/idle M's,
// otherwise our help is not required
if atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) == 0 && atomic.Cas(&sched.nmspinning, 0, 1) { // TODO: fast atomic
startm(_p_, true)
return
}
lock(&sched.lock)
if sched.gcwaiting != 0 {
_p_.status = _Pgcstop
sched.stopwait--
if sched.stopwait == 0 {
notewakeup(&sched.stopnote)
}
unlock(&sched.lock)
return
}
if _p_.runSafePointFn != 0 && atomic.Cas(&_p_.runSafePointFn, 1, 0) {
sched.safePointFn(_p_)
sched.safePointWait--
if sched.safePointWait == 0 {
notewakeup(&sched.safePointNote)
}
}
if sched.runqsize != 0 {
unlock(&sched.lock)
startm(_p_, false)
return
}
// If this is the last running P and nobody is polling network,
// need to wakeup another M to poll network.
if sched.npidle == uint32(gomaxprocs-1) && atomic.Load64(&sched.lastpoll) != 0 {
unlock(&sched.lock)
startm(_p_, false)
return
}
pidleput(_p_)
unlock(&sched.lock)
}6.startm函数
startm函数调度一个M或者必要时创建一个M来运行指定的P。
// Schedules some M to run the p (creates an M if necessary).
// If p==nil, tries to get an idle P, if no idle P's does nothing.
// May run with m.p==nil, so write barriers are not allowed.
// If spinning is set, the caller has incremented nmspinning and startm will
// either decrement nmspinning or set m.spinning in the newly started M.
//go:nowritebarrierrec
func startm(_p_ *p, spinning bool) {
lock(&sched.lock)
if _p_ == nil {
_p_ = pidleget()
if _p_ == nil {
unlock(&sched.lock)
if spinning {
// The caller incremented nmspinning, but there are no idle Ps,
// so it's okay to just undo the increment and give up.
if int32(atomic.Xadd(&sched.nmspinning, -1)) < 0 {
throw("startm: negative nmspinning")
}
}
return
}
}
mp := mget()
unlock(&sched.lock)
if mp == nil {
var fn func()
if spinning {
// The caller incremented nmspinning, so set m.spinning in the new M.
fn = mspinning
}
newm(fn, _p_)
return
}
if mp.spinning {
throw("startm: m is spinning")
}
if mp.nextp != 0 {
throw("startm: m has p")
}
if spinning && !runqempty(_p_) {
throw("startm: p has runnable gs")
}
// The caller incremented nmspinning, so set m.spinning in the new M.
mp.spinning = spinning
mp.nextp.set(_p_)
notewakeup(&mp.park)
}7.entersyscall_handoff函数
entersyscall_handoff函数用来在goroutine进入系统调用(可能会阻塞)时将P传递出去。
func entersyscallblock_handoff() {
if trace.enabled {
traceGoSysCall()
traceGoSysBlock(getg().m.p.ptr())
}
handoffp(releasep())
}8.sysmon函数
sysmon函数是Go runtime启动时创建的,负责监控所有goroutine的状态,判断是否需要GC,进行netpoll等操作。sysmon函数中会调用retake函数进行抢占式调度。
// Always runs without a P, so write barriers are not allowed.
//
//go:nowritebarrierrec
func sysmon() {
// If a heap span goes unused for 5 minutes after a garbage collection,
// we hand it back to the operating system.
scavengelimit := int64(5 * 60 * 1e9)
if debug.scavenge > 0 {
// Scavenge-a-lot for testing.
forcegcperiod = 10 * 1e6
scavengelimit = 20 * 1e6
}
lastscavenge := nanotime()
nscavenge := 0
lasttrace := int64(0)
idle := 0 // how many cycles in succession we had not wokeup somebody
delay := uint32(0)
for {
if idle == 0 { // start with 20us sleep...
delay = 20
} else if idle > 50 { // start doubling the sleep after 1ms...
delay *= 2
}
if delay > 10*1000 { // up to 10ms
delay = 10 * 1000
}
usleep(delay)
if debug.schedtrace <= 0 && (sched.gcwaiting != 0 || atomic.Load(&sched.npidle) == uint32(gomaxprocs)) {
lock(&sched.lock)
if atomic.Load(&sched.gcwaiting) != 0 || atomic.Load(&sched.npidle) == uint32(gomaxprocs) {
atomic.Store(&sched.sysmonwait, 1)
unlock(&sched.lock)
// Make wake-up period small enough
// for the sampling to be correct.
maxsleep := forcegcperiod / 2
if scavengelimit < forcegcperiod {
maxsleep = scavengelimit / 2
}
shouldRelax := true
if osRelaxMinNS > 0 {
lock(&timers.lock)
if timers.sleeping {
now := nanotime()
next := timers.sleepUntil
if next-now < osRelaxMinNS {
shouldRelax = false
}
}
unlock(&timers.lock)
}
if shouldRelax {
osRelax(true)
}
notetsleep(&sched.sysmonnote, maxsleep)
if shouldRelax {
osRelax(false)
}
lock(&sched.lock)
atomic.Store(&sched.sysmonwait, 0)
noteclear(&sched.sysmonnote)
idle = 0
delay = 20
}
unlock(&sched.lock)
}
// trigger libc interceptors if needed
if *cgo_yield != nil {
asmcgocall(*cgo_yield, nil)
}
// poll network if not polled for more than 10ms
lastpoll := int64(atomic.Load64(&sched.lastpoll))
now := nanotime()
if lastpoll != 0 && lastpoll+10*1000*1000 < now {
atomic.Cas64(&sched.lastpoll, uint64(lastpoll), uint64(now))
gp := netpoll(false) // non-blocking - returns list of goroutines
if gp != nil {
// Need to decrement number of idle locked M's
// (pretending that one more is running) before injectglist.
// Otherwise it can lead to the following situation:
// injectglist grabs all P's but before it starts M's to run the P's,
// another M returns from syscall, finishes running its G,
// observes that there is no work to do and no other running M's
// and reports deadlock.
incidlelocked(-1)
injectglist(gp)
incidlelocked(1)
}
}
// retake P's blocked in syscalls
// and preempt long running G's
if retake(now) != 0 {
idle = 0
} else {
idle++
}
// check if we need to force a GC
if t := (gcTrigger{kind: gcTriggerTime, now: now}); t.test() && atomic.Load(&forcegc.idle) != 0 {
lock(&forcegc.lock)
forcegc.idle = 0
forcegc.g.schedlink = 0
injectglist(forcegc.g)
unlock(&forcegc.lock)
}
// scavenge heap once in a while
if lastscavenge+scavengelimit/2 < now {
mheap_.scavenge(int32(nscavenge), uint64(now), uint64(scavengelimit))
lastscavenge = now
nscavenge++
}
if debug.schedtrace > 0 && lasttrace+int64(debug.schedtrace)*1000000 <= now {
lasttrace = now
schedtrace(debug.scheddetail > 0)
}
}
}9.retake函数
retake函数是实现抢占式调度的关键,它的实现步骤如下:
1) 遍历所有P,如果该P处于系统调用中且阻塞,则调用handoffp将其移交其他M;
2) 如果该P处于运行状态,且上次调度的时间超过了一定的阈值,那么就调用preemptone函数这将导致该 P 中正在执行的 G 进行下一次函数调用时,导致栈空间检查失败。进而触发morestack()(汇编代码,位于asm_XXX.s中)然后进行一连串的函数调用,
主要的调用过程如下:morestack()(汇编代码)-> newstack() -> gopreempt_m() -> goschedImpl() ->schedule()在goschedImpl()函数中,会通过调用dropg()将 G 与 M 解除绑定;
再调用globrunqput()将 G 加入全局runnable队列中。最后调用schedule() 来为当前 P 设置新的可执行的 G 。
func retake(now int64) uint32 {
n := 0
for i := int32(0); i < gomaxprocs; i++ {
_p_ := allp[i]
if _p_ == nil {
continue
}
pd := &_p_.sysmontick
s := _p_.status
if s == _Psyscall {
// Retake P from syscall if it's there for more than 1 sysmon tick (at least 20us).
t := int64(_p_.syscalltick)
if int64(pd.syscalltick) != t {
pd.syscalltick = uint32(t)
pd.syscallwhen = now
continue
}
// On the one hand we don't want to retake Ps if there is no other work to do,
// but on the other hand we want to retake them eventually
// because they can prevent the sysmon thread from deep sleep.
if runqempty(_p_) && atomic.Load(&sched.nmspinning)+atomic.Load(&sched.npidle) > 0 && pd.syscallwhen+10*1000*1000 > now {
continue
}
// Need to decrement number of idle locked M's
// (pretending that one more is running) before the CAS.
// Otherwise the M from which we retake can exit the syscall,
// increment nmidle and report deadlock.
incidlelocked(-1)
if atomic.Cas(&_p_.status, s, _Pidle) {
if trace.enabled {
traceGoSysBlock(_p_)
traceProcStop(_p_)
}
n++
_p_.syscalltick++
handoffp(_p_)
}
incidlelocked(1)
} else if s == _Prunning {
// Preempt G if it's running for too long.
t := int64(_p_.schedtick)
if int64(pd.schedtick) != t {
pd.schedtick = uint32(t)
pd.schedwhen = now
continue
}
if pd.schedwhen+forcePreemptNS > now {
continue
}
preemptone(_p_)
}
}
return uint32(n)
}三、小结
Go语言由于存在自己的runtime,使得goroutine的实现相对简单,笔者曾尝试在C++11中实现类似功能,但是保护现场的抢占式调度和G被阻塞后传递给其他Thread的调用很难实现,毕竟Go的所有调用都经过了runtime,这么想来,C#、VB之类的语言实现起来应该容易一点。笔者在C++11中实现的goroutine不支持抢占式调度和阻塞后传递的功能,所以仅仅和直接使用std::thread进行多线程操作进行了对比,工作函数为计算密集的操作,下面是效果对比图(项目地址在https://github.com/InsZVA/cppgo):

四、参考资料
Golang代码仓库:https://github.com/golang/go
《ScalableGoSchedule》:https://docs.google.com/document/d/1TTj4T2JO42uD5ID9e89oa0sLKhJYD0Y_kqxDv3I3XMw/edit
《GoPreemptiveScheduler》:https://docs.google.com/document/d/1ETuA2IOmnaQ4j81AtTGT40Y4_Jr6_IDASEKg0t0dBR8/edit