转:https://blog.csdn.net/qq_20641565/article/details/76216417
Spark中cache和persist的作用以及存储级别
2017年07月27日 19:12:20 lijie_cq 阅读数:10186
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_20641565/article/details/76216417
在Spark中有时候我们很多地方都会用到同一个RDD, 按照常规的做法的话,那么每个地方遇到Action操作的时候都会对同一个算子计算多次,这样会造成效率低下的问题
例如:
val rdd1 = sc.textFile("xxx")
rdd1.xxxxx.xxxx.collect
rdd1.xxx.xxcollect- 1
- 2
- 3
上面就是两个代码都用到了rdd1这个RDD,如果程序执行的话,那么sc.textFile(“xxx”)就要被执行两次,我们可以把rdd1的结果进行cache到内存中,使用如下方法
val rdd1 = sc.textFile("xxx")
val rdd2 = rdd1.cache
rdd2.xxxxx.xxxx.collect
rdd2.xxx.xxcollect- 1
- 2
- 3
- 4
按照如上的方法改造后,后面两个业务代码执行的话rdd1就会在第一次执行的时候被持久化到内存中,后面的业务代码就可以复用,能有效提高效率
其中cache这个方法也是个Tranformation,当第一次遇到Action算子的时才会进行持久化
其中cache内部调用了persist方法,persist方法又调用了persist(StorageLevel.MEMORY_ONLY)方法,所以执行cache算子其实就是执行了persist算子且持久化级别为MEMORY_ONLY
def cache(): this.type = persist()
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)- 1
- 2
注意:
Spark有几种持久化级别如下(参考自博客):
1.MEMORY_ONLY
使用未序列化的Java对象格式,将数据保存在内存中。如果内存不够存放所有的数据,则数据可能就不会进行持久化。那么下次对这个RDD执行算子操作时,那些没有被持久化的数据,需要从源头处重新计算一遍。这是默认的持久化策略,使用cache()方法时,实际就是使用的这种持久化策略。
2.MEMORY_AND_DISK
使用未序列化的Java对象格式,优先尝试将数据保存在内存中。如果内存不够存放所有的数据,会将数据写入磁盘文件中,下次对这个RDD执行算子时,持久化在磁盘文件中的数据会被读取出来使用。
3.MEMORY_ONLY_SER
基本含义同MEMORY_ONLY。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。
4.MEMORY_AND_DISK_SER
基本含义同MEMORY_AND_DISK。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC。
5.DISK_ONLY
使用未序列化的Java对象格式,将数据全部写入磁盘文件中。
6.MEMORY_ONLY_2, MEMORY_AND_DISK_2, 等等
对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化机制主要用于进行容错。假如某个节点挂掉,节点的内存或磁盘中的持久化数据丢失了,那么后续对RDD计算时还可以使用该数据在其他节点上的副本。如果没有副本的话,就只能将这些数据从源头处重新计算一遍了。
- 建议:(参考自博客)
默认情况下,性能最高的当然是MEMORY_ONLY,但前提是你的内存必须足够足够大,可以绰绰有余地存放下整个RDD的所有数据。因为不进行序列化与反序列化操作,就避免了这部分的性能开销;对这个RDD的后续算子操作,都是基于纯内存中的数据的操作,不需要从磁盘文件中读取数据,性能也很高;而且不需要复制一份数据副本,并远程传送到其他节点上。但是这里必须要注意的是,在实际的生产环境中,恐怕能够直接用这种策略的场景还是有限的,如果RDD中数据比较多时(比如几十亿),直接用这种持久化级别,会导致JVM的OOM内存溢出异常。
如果使用MEMORY_ONLY级别时发生了内存溢出,那么建议尝试使用MEMORY_ONLY_SER级别。该级别会将RDD数据序列化后再保存在内存中,此时每个partition仅仅是一个字节数组而已,大大减少了对象数量,并降低了内存占用。这种级别比MEMORY_ONLY多出来的性能开销,主要就是序列化与反序列化的开销。但是后续算子可以基于纯内存进行操作,因此性能总体还是比较高的。此外,可能发生的问题同上,如果RDD中的数据量过多的话,还是可能会导致OOM内存溢出的异常。
如果纯内存的级别都无法使用,那么建议使用MEMORY_AND_DISK_SER策略,而不是MEMORY_AND_DISK策略。因为既然到了这一步,就说明RDD的数据量很大,内存无法完全放下。序列化后的数据比较少,可以节省内存和磁盘的空间开销。同时该策略会优先尽量尝试将数据缓存在内存中,内存缓存不下才会写入磁盘。
通常不建议使用DISK_ONLY和后缀为_2的级别:因为完全基于磁盘文件进行数据的读写,会导致性能急剧降低,有时还不如重新计算一次所有RDD。后缀为_2的级别,必须将所有数据都复制一份副本,并发送到其他节点上,数据复制以及网络传输会导致较大的性能开销,除非是要求作业的高可用性,否则不建议使用。
- 可以查询RDD的持久化策略:
scala> rdd1.getStorageLevel
res17: org.apache.spark.storage.StorageLevel = StorageLevel(false, false, false, false, 1)
scala> rdd1.getStorageLevel.description
res18: String = Serialized 1x Replicated
- 1
- 2
- 3
- 4
- 5
- 6
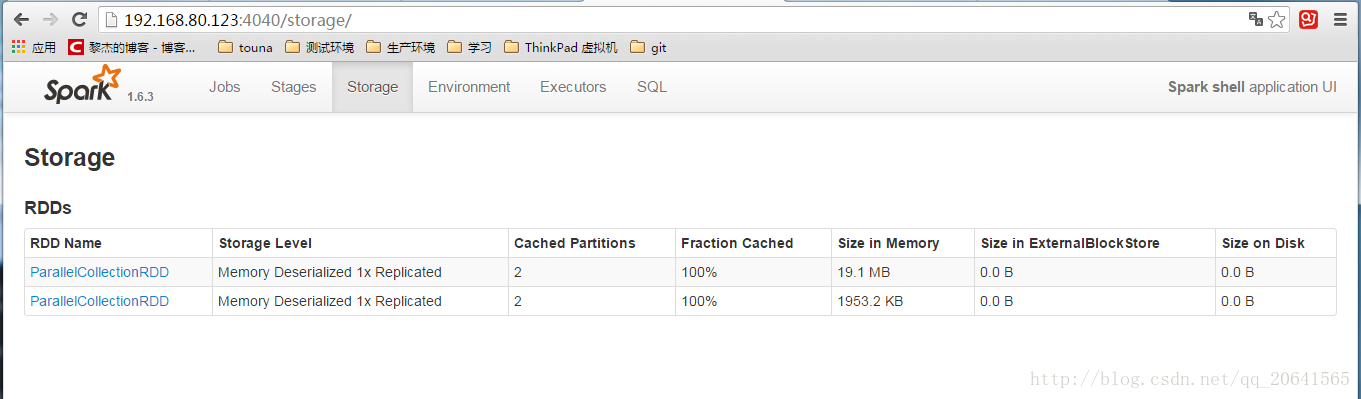
- UI界面上面查看持久化的数据:
当cache后查看持久化的数据:
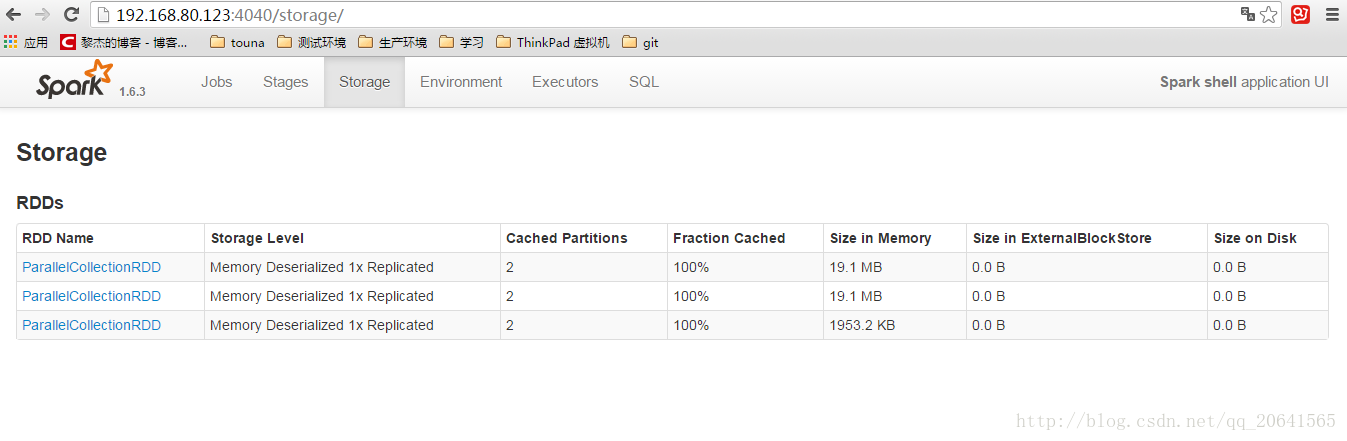
当执行rdd1.unpersist(true)后,持久化的数据就会被删除: