案例一:
需求:现有这么一批数据,现要求出:每个用户截止到每月为止的最大单月访问次数和累计到该月的总访问次数。
数据:
用户名,月份,访问次数
A,2015-01,5
A,2015-01,15
B,2015-01,5
A,2015-01,8
B,2015-01,25
A,2015-01,5
A,2015-02,4
A,2015-02,6
B,2015-02,10
B,2015-02,5
A,2015-03,16
A,2015-03,22
B,2015-03,23
B,2015-03,10
B,2015-03,11最终结果:
用户 月份 最大访问次数 总访问次数 当月访问次数
A 2015-01 33 33 33
A 2015-02 33 43 10
A 2015-03 38 81 38
B 2015-01 30 30 30
B 2015-02 30 45 15
B 2015-03 44 89 44解决:
#step01 统计每个用户每月的总访问次数
create view view_step01 as select name,month,sum(visitCount) total from t_user group by name,month;
#step02 (自连接,连接条件为name)
create view view_step02 as
select t1.name aname,t1.month amonth,t1.total atotal,t2.name bname,t2.month bmonth,t2.total btotal
from view_step01 t1 join view_step01 t2 on t1.name =t2.name
#step03 去除无用数据,每组找到小于等于自己月份的数据
select bname,bmonth,max(btotal),sum(btotal),btotal
from view_step02
where unix_timestamp(amonth,'yyyy-MM')>=unix_timestamp(bmoth,'yyyy-MM')
group by aname,amonth,atotal;案例二:
#建表语句:
CREATE TABLE `course` (
`id` int(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
`sid` int(11) DEFAULT NULL,
`course` varchar(255) DEFAULT NULL,
`score` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
#插入数据
INSERT INTO `course` VALUES (1, 1, 'yuwen', 43);
INSERT INTO `course` VALUES (2, 1, 'shuxue', 55);
INSERT INTO `course` VALUES (3, 2, 'yuwen', 77);
INSERT INTO `course` VALUES (4, 2, 'shuxue', 88);
INSERT INTO `course` VALUES (5, 3, 'yuwen', 98);
INSERT INTO `course` VALUES (6, 3, 'shuxue', 65);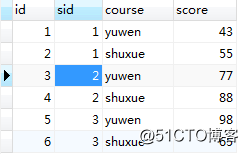
需求:所有数学课程成绩 大于 语文课程成绩的学生的学号
解决:(行列转换)
SELECT
t1.sid
FROM
(
SELECT
sid,
max( CASE `course` WHEN "yuwen" THEN score ELSE 0 END ) AS "yuwen",
max( CASE `course` WHEN "shuxue" THEN score ELSE 0 END ) AS "shuxue"
FROM
`course`
GROUP BY
sid
) t1
WHERE
t1.yuwen < t1.shuxue;案例三:
需求:比如:2010012325表示在2010年01月23日的气温为25度。现在要求使用hive,计算每一年出现过的最大气温的日期+温度。
数据:
年 温度
20140101 14
20140102 16
20140103 17
20140104 10
20140105 06
20120106 09
20120107 32
20120108 12
20120109 19
20120110 23
20010101 16
20010102 12
20010103 10
20010104 11
20010105 29
20130106 19
20130107 22
20130108 12
20130109 29
20130110 23
20080101 05
现在需要根据年月进行group by 但是最终的结果需要是20080101 05,也就是说,分组字段和最后保留的字段不相同,这时怎么办?
解决:
#Step1:
CREATE VIEW view_step1 AS SELECT
substr( tmp, 1, 4 ) AS YEAR,
max( substr( tmp, 9, 2 ) ) AS tmp
FROM
tmp
GROUP BY
substr( tmp, 1, 4 );
#Step2:
SELECT
b.tmp,
a.tmp
FROM
view_step1 a
JOIN tmp b ON a.YEAR = substr( b.tmp, 1, 4 )
AND a.tmp = substr( b.tmp, 9, 2 );案例四:
数据
#表示有id为1,2,3的学生选修了课程a,b,c,d,e,f中其中几门:
id course
1,a
1,b
1,c
1,e
2,a
2,c
2,d
2,f
3,a
3,b
3,c
3,e需求:编写Hive的HQL语句来实现以下结果:表中的1表示选修,表中的0表示未选修。
解决(方案1):
#行列转换
select id
max(case when course='a' then 1 else 0 and ) as a ,
max(case when course='b' then 1 else 0 and ) as b ,
max(case when course='c' then 1 else 0 and ) as c ,
max(case when course='d' then 1 else 0 and ) as d ,
max(case when course='e' then 1 else 0 and ) as e ,
max(case when course='f' then 1 else 0 and ) as f
from course group by id;解决(方案2):
#collect_set函数
#step01
create view id_courses as
select a.course acourse,b.course bcourse,b.id id
(select collect_set(course) as course from course) a
join
(selecet id ,colect_set(course) as course from course group by id) b
#step02
select id,
case when array_contains(bcourse,acourse[0]) then 1 else 0 end as a ,
case when array_contains(bcourse,acourse[1]) then 1 else 0 end as b ,
case when array_contains(bcourse,acourse[2]) then 1 else 0 end as c ,
case when array_contains(bcourse,acourse[3]) then 1 else 0 end as d ,
case when array_contains(bcourse,acourse[4]) then 1 else 0 end as e ,
case when array_contains(bcourse,acourse[5]) then 1 else 0 end as f
from id_courses;