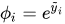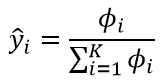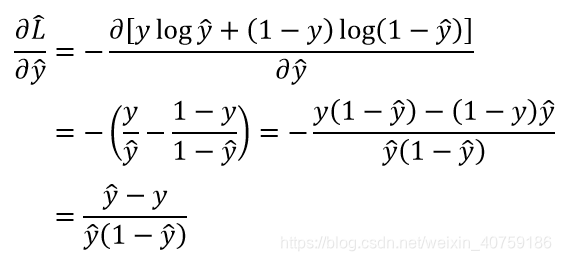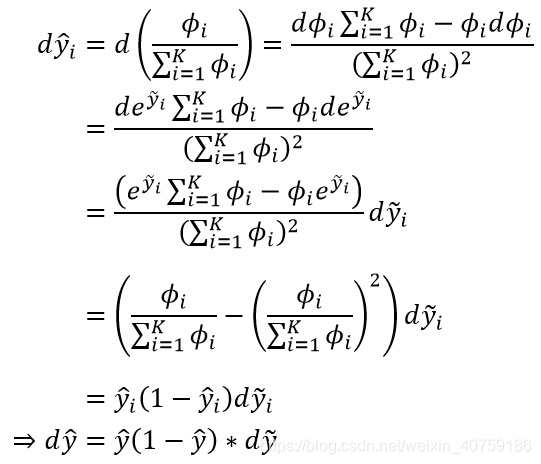softmax
softmax函数所表示的可以看成为对分类结果的概率分布。
softmax 的损失函数:交叉熵
他可以规避sigmoid函数梯度消失的问题。
交叉熵求偏导
可以看出和MSE是一模一样的
代码实现
class NN:
def __init__(self, ws=None):
self._ws = ws
@staticmethod
def relu(x):
return np.maximum(0,x)
@staticmethod
def softmax(x):
# exp_x ranges from 0 to 1,for OverflowError
exp_x = np.exp(x - np.max(x, axis=1, keepdims=True))
return exp_x / np.sum(exp_x, axis=1, keepdims=True)
@staticmethod
def corss_entropy(y_pred, y_true):
return -np.average(
y*np.log(np.maximum(y_pred, 1e-12)) +
(1-y) * np.log(np.maximum(1-y_pred, 1e-12))
)
# hidden_dim is the hidden units m
def fit(self, x, y, hidden_dim=4, lr=1e-3, epoch=1000):
input_dim, output_dim = x.shape[1], y.shape[1]
if self._ws is None:
self._ws = [
np.random.random([input_dim, hidden_dim]),
np.random.random([hidden_dim, output_dim])]
losses = []
for _ in range(epoch):
# forward pass
h = x.dot(self._ws[0])
h_relu = NN.relu(h)
y_pred = NN.softmax(h_relu.dot(self._ws[1]))
losses.append(NN.corss_entropy(y_pred, y))
# backford pass
# ∂L/∂y_ ,Y_ is h_relu.dot(self._ws[1]),the input of softmax
# this is the key, the different between softmax-cross-entropy
# and mse
d1 = y_pred-y
# ∂L/∂w2 = ∂y_pred/∂w2* ∂L/∂y_pred
# ∂y_pred/∂w2= h_relu.T
dw2 = h_relu.T.dot(d1)
# ∂L/∂w2 = ∂H/∂w2* ∂L/∂H
# ∂L/∂H = ∂L/∂y_pred * w2^T * relu'
dw1 = x.T.dot(d1.dot(self._ws[1].T)*(h_relu != 0))
# uodate w
self._ws[0] -= lr*dw1
self._ws[1] -= lr*dw2
return losses
def predict(self,x):
h = x.dot(self._ws[0])
h_relu = NN.relu(h)
# 由于 Softmax 不影响 argmax 的结果,所以这里直接 argmax h_relu.dot(self._ws[1])即可
y_pred = NN.softmax(h_relu.dot(self._ws[1]))
return np.argmax(y_pred, axis=1)
代码测试:
x, y = gen_five_clusters()
label = np.argmax(y, axis=1)
nn = NN()
losses = nn.fit(x, y, 32, 1e-4)
visualize2d(nn, x, label, draw_background=True)
print("准确率:{:8.6} %".format((nn.predict(x) == label).mean() * 100))
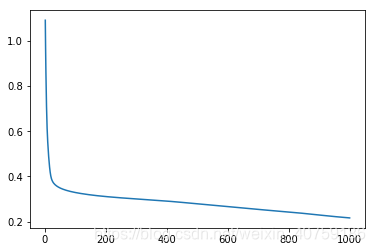
plt.figure()
plt.plot(np.arange(1, len(losses)+1), losses)
plt.show()
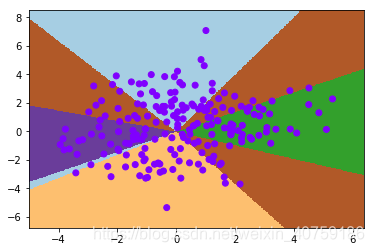 准确率: 74.5 %
准确率: 74.5 %
附录:交叉熵求偏导推导: