程序与虚拟内存和物理内存的关系:
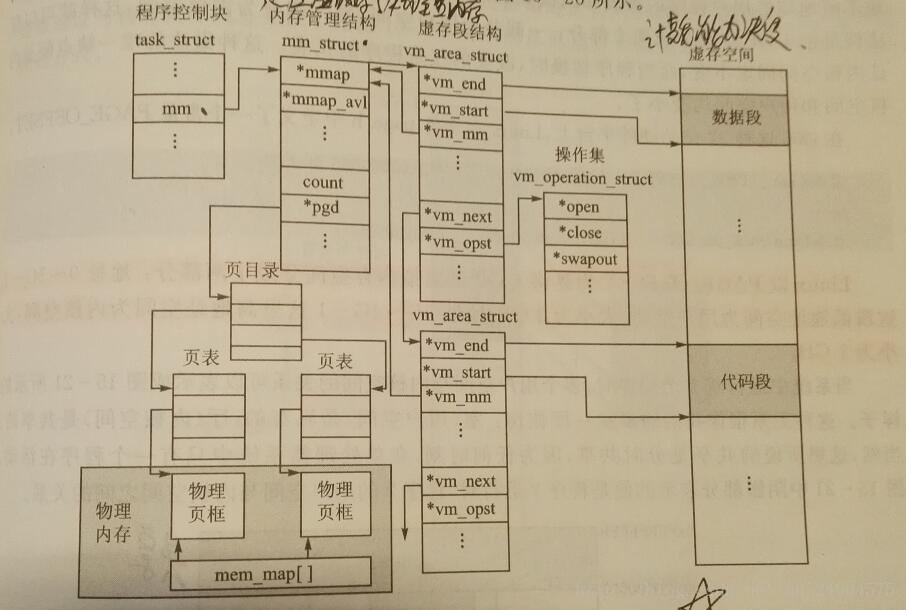
结构mm_struct可以看成属于一个程序的包括虚拟内存和物理内存的所有内存的控制块;vm_area_struct里有指向相关段虚拟地址的指针vm_end and vm_start和指向操作函数集中的函数指针vm_opst;mm_struct里有指向实际物理空间的指针pgd。
Linux的空间分配:

Linux以PAGE_OFFSET为界将4GB的虚拟内存空间分成了两部分:地址0~3G这段低地址空间为用户空间,大小为3GB;地址3G-4G这一段高地址空间为内核空间,大小为1GB。
内核空间是所有程序共享的,程序的虚拟用户空间是程序私有的。
Linux的进程状态:
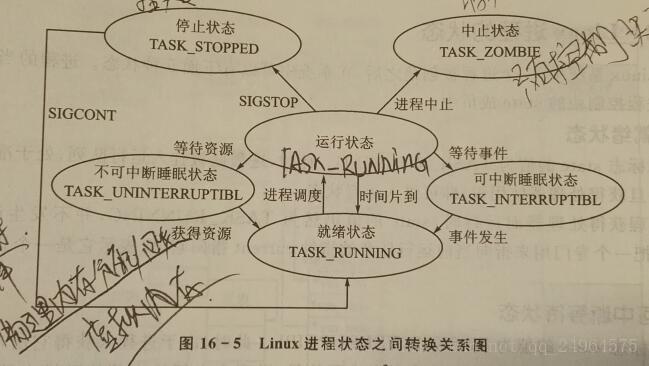
Linux有两类状态:一类是用户进程、一类是内核进程
①用户进程即可以在用户空间运行、也可以在内核空间运行
②内核进程只可以在内核空间运行
就绪状态:进程已被挂入运行队列,处于准备运行状态,一旦获得处理器使用权,即可进入运行状态;
可中断等待状态:进程未获得申请的资源而处于等待状态,一旦资源有效或者有唤醒信号就会进入就绪状态;
不可中断等待状态:进程未获得申请的资源而处于等待状态,一旦资源有效就会进入就绪状态,但是不能被唤醒信号所唤醒;
停止状态:收到SIGSTOP信号后,由运行状态进入停止状态;收到SINCONT信号时,进入就绪状态;
终止状态:进程由于某种原因而终止运行,系统对他不再理睬仅仅保留其进程控制块,这种状态也叫“僵死”状态;
Linux的经常控制块:
Linux可以管理512个进程,每个进程控制块task_struct的指针都存放在一个数组中;
task_struct中pid代表进程的pid,也就是当前进程的ID号

Linux进程的创建:
Linux中除了系统启动之后创建的第一个进程[根进程]不是由已存在的进程创建,其余的进程必须由已经存在的进程来创建,新创建的进程叫做子进程,而创建子进程的进程叫做父进程。
函数fork()
创建一个子进程的系统调用叫做fork(),调用函数fork()的进程就是父进程,以附件为控制块的进程就是子进程。子进程共享父进程的程序代码,有自己的数据区和栈区、系统堆栈区。
调用fork()后的代码会被执行两次,但是对自己的数据区、堆栈区中变量的修改互不影响;fork()函数的返回值有-1、0、正整数,“-1”代表创建失败,“0”代表当前进程为子进程,“正整数”代表当前进程为父进程同时其也是子进程的ID号。
getpid():获得当前进程的ID
getppid():获得当前父进程的ID
/*父进程a创建子进程b、c的代码示例*/
#include <stdio.h>
#include <sys/types.h>
int main()
{
pid_t p1,p2;
p1 = fork();
if(p1 < 0)
printf("error in fork !\n");
else if(p1 == 0)
printf("child process b \n");
else
{
p2 = fork();
if(p2 < 0)
printf("error in fork!\n");
else if(p2 == 0)
printf("child process c\n");
else
printf("parent process a\n");
}
return 0;
}
/*如果运行程序,会发现进程的运行顺序有调度器决定,与进程的创建顺序无关*/函数execu(const char *path,cahr *const argv[])
子进程调用execu()后,系统会立即为子进程加载执行文件分配私有内存空间。调用execu()前,进程有自己的堆栈和数据区,但是没有自己的程序执行空间;调用execu()后除了有自己的堆栈和数据区,也分配了程序执行空间。
子进程调用fork(),再调用execu()函数后,子进程和父进程不再共享任何系统资源,父进程和子进程唯一存留的关系是父进程有回收子进程的责任。
/*父进程调用fork()创建子进程,子进程调用execu()执行可执行文件*/
Hello.c文件:
#include <stdio.h>
#include <sys/types.h>
int main()
{
printf("Hello!\n");
return 0;
}
创建子进程的代码文件:
#include <stdio.h>
#include <sys/types.h>
int main()
{
pid_t pid;
if(!(pid = fork()))
{
execu("./Hello.o",NULL);
}
else
{
printf("my pid is %d\n",getpid());
}
return 0;
}wait()函数
按照计算机技术中谁创建谁负责的惯例,在处理父进程与子进程的关系上,那就是等待某个子进程已经退出的信息;如果父进程得到这个信息,父进程就会在处理子进程的“后事”之后才会继续执行。
创建子进程的代码文件:
#include <stdio.h>
#include <sys/types.h>
int main()
{
pid_t pid;
if(!(pid = fork()))
{
execu("./Hello.o",NULL);
printf("pid %d:I am back,something is wrong!\n",getppid());
}
else
{
printf("my pid is %d\n",getpid());
wait4(pid,NULL,0,NULL);
for(int i=0;i<10;i++)
{
printf("done\n");
}
}
return 0;
}
系统调用vfork()
与fork()不同的是vfork()有自己的程序代码,但是没有自己的数据区和栈区,fork()、vfork()创建的子进程都有自己的系统堆栈区;以上的特性导致调用vfork()之后的代码也会被执行两次,但对数据区和栈区里变量的修改会互相影响,因为子进程在调用execu()函数之前,与父进程使用同一个数据区和用户堆栈[栈区].同样也是重要的是,vfork()创建的子进程一定先于父进程运行。
Linux进程的时间片与权重参数
所有进程时间片的总和为一个调度周期,当未被阻塞的进程片都耗尽时,一个调度周期结束,然后由调度器重新分配时间片,开始下一个调度周期。
时间片的初值存放在counter中,counter反应进程时间片的剩余情况,处理器根据counter值大的优先运行。但是在实际问题中,系统真正用来确定进程的优先权时,使用的依据为权重参数weight,weight大者进程优先运行。
weight 正比 [counter + (20 - nice)]调度策略:
每个进程的进程控制块中都有一个域policy来指明进程为何种进程,采用何种策略,SCHED_OTHER说明进程为普通进程,采用普通进程的调度策略。
#if HZ < 200
#define TICK_SCALE(x) ((x) >> 2)
#define NICE_TO_TICKS(nice) (TICK_SCALE(20 - (nice)) + 1)
p->count = (p->counter >> 1) + NICE_TO_TICKS(p->nice);
/*
如果用户在文件include/asm-i386/param.h中定义的HZ为100,counter、nice的默认值为0,于是计算结果counter的值为6ticks,即进程片的默认值大小约为60ms。 10100 >> 2 ---> 101 ---> 5 ,5+1等于6。
*/为实时进程赋值一个远大于普通进程的固定权重参数weight,以确保实时进程的优先权
weight 正比 [counter + (20 - nice)],这个表达式也体现出进程调度的公平性,上一个调度结束时还处于阻塞状态的进程,在这一次调度中counter的值会加上上一次剩余值的一半,使其获得更高的权重weigth。
Linux文件系统
磁盘上管理文件的文件、数据结构和操作构成了磁盘文件系统,简称文件系统。
文件的存储
通常一个文件需要占用多个存储快,存储快约为1KB
目录项记录文件的名称、存储位置等信息,一个记录叫做目录项
目录是目录项的集合,目录文件是目录的集合
目录文件是系统自用文件,也叫做特殊文件,用户文件叫做普通文件。
文件块的索引组织方式
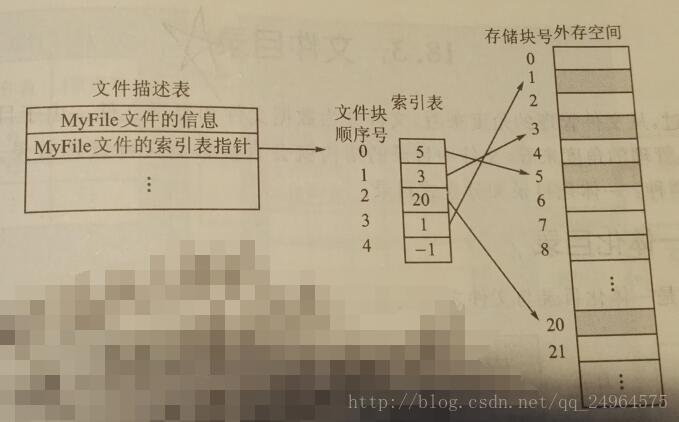
以文件块的逻辑顺序号为数组元素的下标
以文件存储块的指针为数组元素的内容
这就形成了一个文件的索引表
索引表就是文件块的逻辑块号与存储块号的对照表
空闲块的记录:
位图管理方式:以数据的一个二进制位表示对应块的空闲状态,0表示未占用、1表示占用;
链表管理方式:把所有存储块用链表链接起来;
分组链表方式:链表再链接成一个链表;
位图管理方式简单,分组链表方式能够迅速的找到大量的空闲的存储块。
文件目录:

把一个文件的所有信息都放在一个目录项中叫做一体化目录
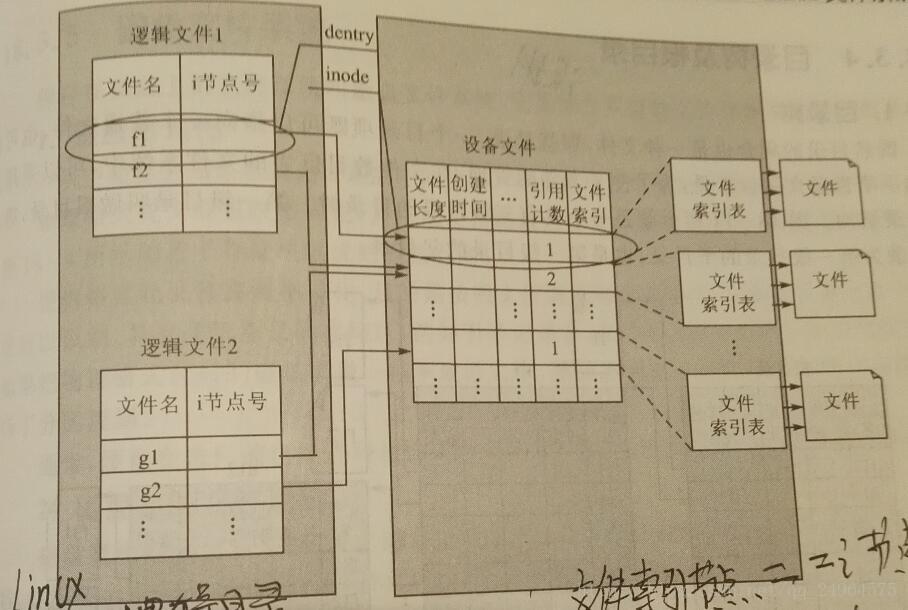
分立式目录一部分只记录文件名等用户关系的逻辑信息[逻辑目录],另一部分则只记录文件所占用的存储块数目、位置等物理信息[文件索引结点]。
记录逻辑目录的文件叫做逻辑目录文件
记录文件索引节点的文件叫做设备文件
多个逻辑目录文件的目录项可以对应多个设备文件的文件索引节点
为了记录一个文件有多少个引用,在设备目录中有一个引用计数的项
Ext2文件系统:
在Linux文件include/linux/ext2_fs.h中定义了文件索引节点结构ext2_inode:
struct ext2_inode{
_le16 i _mode //文件模式
_le32 i_block[15] //文件索引表
};
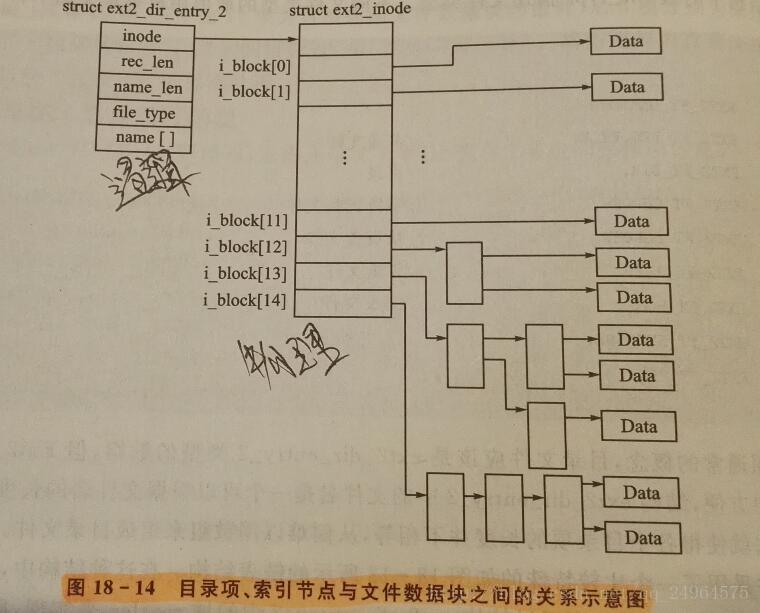
文件索引表的一个元素的大小为32位,即4个字节,若Ext2块大小为1KB,则有256个数据项,那么Ext2的最大容量:
1KB * 12 + 256 * 256 KB + 256 * 256 * 256KB = 16.842020GB。
虚拟文件系统:
虚拟文件系统的目的就是不让用户与实际的文件系统见面,使用户面对一个具有统一界面的文件系统,隐藏实际文件系统的操作细节。
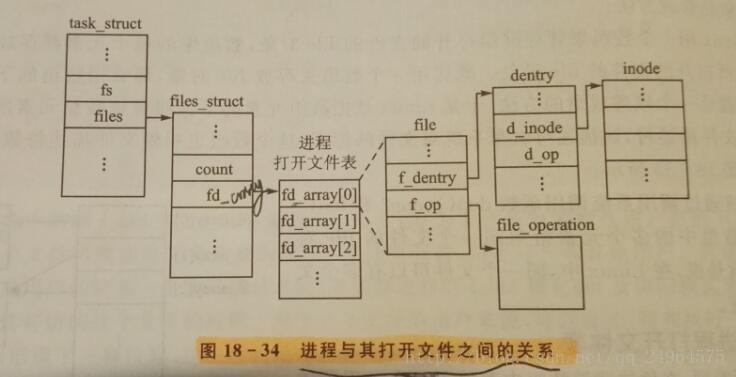
文件与进程的关联:
管道:
int pipe(int fildes[2]);
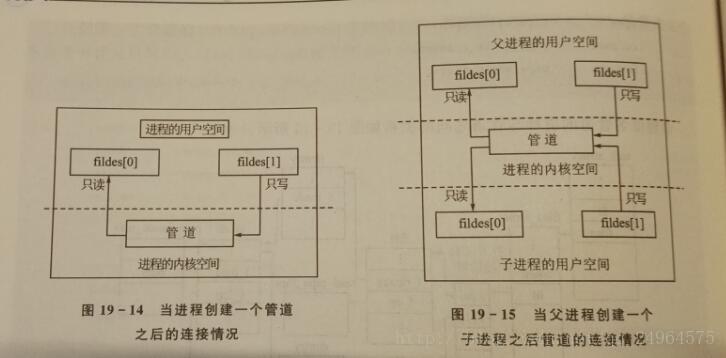
匿名管道是在具有公共祖父的进程之间进行通信的手段。
pipe()就是创建一个内存文件,在参数中返回这个文件的两个描述符fildes[0]、fildes[1]。fildes[0]是一个具有”只读“属性的文件描述符,fildes[1]是一个具有”只写“属性的文件描述符。使得文件像一个只能单向流通的管道一样,一头专门用来输入数据,另一头专门用来输出数据。
#include <stdio.h>
#include <string.h>
#include <wait.h>
#include <unistd.h>
#define MAX_LINE 80
int main()
{
int testPipe[2],ret;
char buf[MAX_LINE + 1];
const char * testbuf = {"主进程发送的数据."};
if(pipe(testPipe) == 0) //0 正常, -1 不正常
{
if(fork() == 0)//子进程fork返回0
{
ret = read(testPipe[0],buf,MAX_LINE);//只读
buf[ret] = 0;
printf("子进程读到的数据为:%s\n",buf);
clase(testPipe[0]);
}
else
{
ret = read(testPipe[1],testbuf,strlen(testbuf));//只写
ret = wait(NULL);
clase(testPipe[1]);
}
}
return 0;
}