1. 认识HashMap
HashMap是用来存储key-value键值对的数据结构。
当我们创建HashMap的时候,如果不指定任何参数,它会为我们创建一个初始容量为16,负载因子为0.75的HashMap (load factor,记录数/数组长度)。当loadFactor达到0.75或指定值的时候,HashMap的总容量自动扩展一倍。
它的底层采用Entry数组来保存所有的key-value对。当需要存储一个Entry对象时,会根据Hash算法(key的hashCode值)来决定其存储位置;当需要取出一个Entry时,也会根据Hash算法找到其存储位置,直接取出该Entry。由此可见:HashMap之所以能快速存、取它所包含的Entry,完全类似于现实生活中母亲从小教我们的:不同的东西要放在不同的位置,需要时才能快速找到它。
如果两个Entry的key的hashCode()返回值相同,那它们的存储位置相同。如果这两个Entry的key通过equals()比较返回true,新添加Entry的value将覆盖集合中原有Entry的value,但key不会覆盖。如果这两个Entry的key通过equals()比较返回false,新添加的Entry将与集合中原有Entry形成Entry链,而且新添加的Entry位于Entry链的头部。我们来看下图:

注:图片源自http://www.admin10000.com/doc...
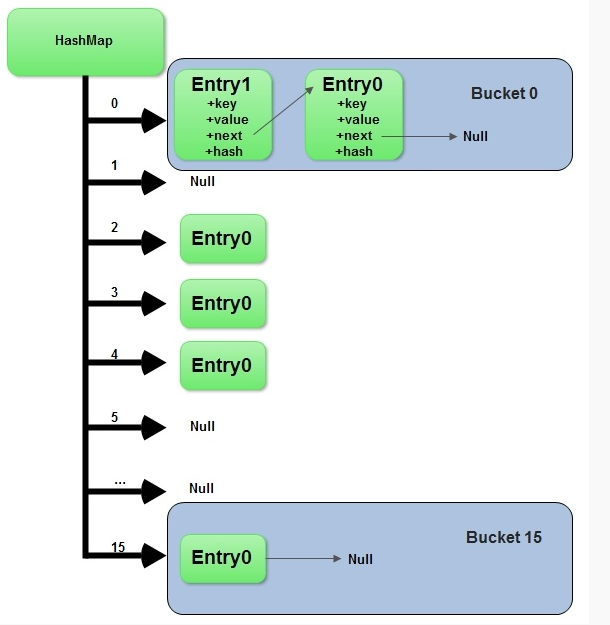
2. 小结
HashMap底层实现:数组+链表+红黑树
通常,只使用Entry数组存放键值对,key的hashcode()值决定它的存放位置,equals()方法决定最终的值。
如果hash算法设计的足够好,是不会发生碰撞冲突的,但实际中肯定不存在这么完美的事情。
当key的hashcode()相同,equals()方法返回不同时,会在相同的位置上形成一个链表,当链表长度大于8的时候,会转化成红黑树,链表的查找的时间复杂度为O(n),而红黑树为O(lgn),会提高查询的性能。
当Entry数组不足以容纳更多的元素的时候,以负载因子为0.75,数组长度为20来说,当数组元素数到达15的时候,会自动触发一次resize操作,会把旧的数据映射到新的哈希表,数组扩容到原来的2倍。
resize在多线程环境下,可能产生条件竞争
因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。
在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing,否则针对key的hashcode相同的Entry每次添加还要定位到尾节点)。
如果条件竞争发生了,可能出现环形链表。之后当我们get(key)操作时,就有可能发生死循环。
另外,既然都有并发的问题了,我们就该使用ConcurrentHashMap了。
不使用HashTable的原因
它使用synchronized来保证线程安全,会锁住整个哈希表。在线程竞争激烈的情况下效率非常低下,当一个线程访问HashTable的同步方法时,其它线程访问HashTable的同步方法只能进入阻塞或轮询状态。
3. ConcurrentHashMap
核心:采用segment分段锁来保护不同段的数据,是线程安全且高效的。
当多线程访问容器里不同段的数据时,线程间就不会存在锁竞争,从而可以有效提高并发访问效率。
ConcurrentHashMap类图

初始化中除了initialCapacity,loadFactor参数,还有一个重要的concurrency level,它决定了segment数组的长度(默认是16,长度需要是2的N次方,与采用的哈希算法有关)。
每次get/put操作都会通过hash算法定位到一个segment,然后再通过hash算法定位到具体的entry。
get操作是不需要加锁的,因为get方法里将要使用的共享变量都定义成了volatile。
定义成volatile的变量,能够在线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期的值,但是只能被单线程写(有一种情况可以被多线程写,就是写入的值不依赖于原值,像直接set值就可以,而i++这样的操作就是非线程安全的)。
put方法在操作共享变量时必须加锁,首先会定位到segment,然后在segment里进行插入操作。
size方法,需要统计每个segment中count变量的值,然后加和。但是我们拿到的count值累加前可能已经发生了变化,那么统计结果就不准确了。所以最安全的做法就是统计size的时候把所有segment的put,remove和clear方法全部锁住,但是这种做法显然非常低效。
ConcurrentHashMap的做法是先尝试2次通过不锁住segment的方式来统计各个segment大小,如果统计过程中,容器的count发生了变化,再采用加锁的方式统计所有segment的大小(put、remove和clear操作元素前都会将modCount进行加1,所以可以通过在统计前后比较modCount是否发生变化来得知容器大小是否发生了变化)。
关于ConcurrentHashMap的迭代
使用了不同于传统集合的快速失败迭代器的另外一种迭代方式,我们称为弱一致迭代器。在这种迭代方式中,当iterator被创建后集合再发生改变就不再是抛出ConcurrentModificationException,取而代之是在改变时new新的数据从而不影响原有的数据,iterator完成后再将头指针替换为新的数据,这样iterator线程可以使用原来老的数据,而写线程也可以并发的完成改变。更重要的,这保证了多个线程并发执行的连续性和扩展性,是性能提升的关键。
4. 拓展补充
4.1 LinkedList
HashMap使用了链表来存储相同位置的Entry元素,接下来我们参考jdk源码实现一个简化版的LinkedList,代码如下:
/**
* 手动实现一个链表
* Date: 7/24/2016
* Time: 3:45 PM
*
* @author xiaodong.fan
*/
public class MyLinkedList<E> implements Iterable<E> {
int size = 0;
int modCount = 0;
Node<E> first;
Node<E> last;
/**
* 添加元素
* @param e
*/
public void add(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
/**
* 移除元素
* @param index
* @return E
*/
public E remove(int index) {
checkElementIndex(index);
Node<E> x = node(index);
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
/**
* 修改元素
* @param index
* @param element
* @return E
*/
public E set(int index, E element) {
checkElementIndex(index);
Node<E> x = node(index);
E oldVal = x.item;
x.item = element;
modCount++;
return oldVal;
}
/**
* 获取元素
* @param index
* @return E
*/
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
/**
* 迭代元素
* @return Iterator<E>
*/
@Override
public Iterator<E> iterator() {
return new Itr();
}
/*************************私有方法****************************/
// 数据节点
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
// 快速失败迭代器
private class Itr implements Iterator<E> {
// 迭代当前位置
int cursor = 0;
// 上一个迭代位置
int lastRet = -1;
// 迭代过程中判断是否有并发修改
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size;
}
public E next() {
checkForComodification();
try {
int i = cursor;
E next = get(i);
lastRet = i;
cursor = i + 1;
return next;
} catch (IndexOutOfBoundsException e) {
checkForComodification();
throw new NoSuchElementException();
}
}
public void remove() {
if (lastRet < 0) {
throw new IllegalStateException();
}
checkForComodification();
try {
MyLinkedList.this.remove(lastRet);
if (lastRet < cursor) {
cursor--;
}
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException e) {
throw new ConcurrentModificationException();
}
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
private Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
private void checkElementIndex(int index) {
if (!(index >= 0 && index < size))
throw new IndexOutOfBoundsException("Index: "+index+", Size: "+size);
}
}4.2 实现LRU缓存
LRU是Least Recently Used 的缩写,翻译过来就是“最近最少使用”,LRU缓存就是使用这种原理实现,简单的说就是缓存一定量的数据,当超过设定的阈值时就把一些过期的数据删除掉。那怎么确定删除哪条过期数据呢,采用LRU算法实现的话就是将最老的数据删掉。
LinkedHashMap自身已经实现了顺序存储,默认情况下是按照元素的添加顺序存储,也可以启用按照访问顺序存储(指定构造函数第3个参数为true即可),也就是最近读取的数据放在最前面,最早读取的数据放在最后面。它还有一个判断是否删除最老数据的方法,默认是返回false,即不删除数据。所以我们可以使用LinkedHashMap很方便的实现LRU缓存。代码如下:
/**
* LRU缓存(当容量达到最大值时,删除最近最少使用的记录)
* @param <K>
* @param <V>
*/
public class LRULinkedHashMap<K, V> extends LinkedHashMap<K, V> {
private static final long serialVersionUID = 1L;
private final int maxCapacity;
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
private final Lock lock = new ReentrantLock();
public LRULinkedHashMap(int maxCapacity) {
super(maxCapacity, DEFAULT_LOAD_FACTOR, true);
this.maxCapacity = maxCapacity;
}
@Override
protected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) {
return size() > maxCapacity;
}
@Override
public V get(Object key) {
try {
lock.lock();
return super.get(key);
} finally {
lock.unlock();
}
}
@Override
public V put(K key, V value) {
try {
lock.lock();
return super.put(key, value);
} finally {
lock.unlock();
}
}
@Override
public int size() {
try {
lock.lock();
return super.size();
} finally {
lock.unlock();
}
}
}5. 参考文章
HashMap的工作原理
LRU缓存实现(Java)
Hashtable与ConcurrentHashMap区别
《java并发编程的艺术》迷你书