1 - 引言
之前我们使用了K-NN对Cifar-10数据集进行了图片分类,正确率只有不到30%,但是还是比10%高的[手动滑稽],这次我们将学习使用SVM分类器来对Cafi-10数据集实现分类,但是正确率应该也不会很高
要想继续提高正确率,就要对图像进行预处理和特征的选取工作,而不是用整张图片进行识别。从计算机视觉发展的角度来将,在深度学习出来之前,传统的图像识别方法一直都是使用特征选取+分类器的方法来识别图像,虽然说正确率没有深度学习那么高,但是这些方法还是有必要学习掌握的。
2 - 准备工作
- 创建项目
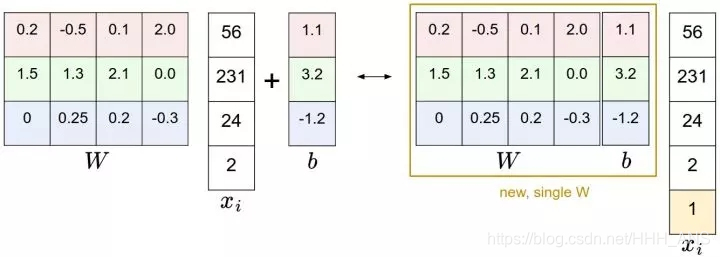
因为数据集还是Cifar-10,项目的结构和K-NN的一样 - 在classifiers文件中创建linear_svm.py
- 创建SVM.py文件进行实验
3 - 具体步骤
线性分类器为
hinge损失函数为:
使用梯度下降来最小化损失函数
则
根据这个思想,可以写出函数svm_loss_naive
def svm_loss_naive(W, X, y, reg):
"""
使用循环实现的SVM loss函数
输入维数为D,有C类,我们使用N个样本作为一批输入
输入:
-W :一个numpy 数组,维数为(D,C),存储权重
-X :一个numpy数组,维数为(N,D),存储一小批数据
-y : 一个numpy数组,维数为(N,),存储训练标签
-reg :float,正则化强度
输出:
- loss : 损失函数的值
- dW : 权重W的梯度,和W大小相同的array
"""
dW = np.zeros(W.shape) # initialize the gradient as zero
# compute the loss and the gradient
num_classes = W.shape[1]
num_train = X.shape[0]
loss = 0.0
for i in range(num_train):
scores = X[i].dot(W)
correct_class_score = scores[y[i]]
for j in range(num_classes):
if j == y[i]:
continue
margin = scores[j] - correct_class_score + 1 # note delta = 1
if margin > 0:
loss += margin
#计算j不等于yi的行的梯度
dW[:, j] += X[i]
#j=yi时的梯度
dW[:, y[i]]+=(-X[i])
# Right now the loss is a sum over all training examples, but we want it
# to be an average instead so we divide by num_train.
loss /= num_train
dW /= num_train
# Add regularization to the loss.
loss += 0.5*reg * np.sum(W * W)
dW += reg * W
return loss, dW
但是这个函数使用循环计算效率低,我们可以继续使用向量化的思想写出不需要循环的函数
def svm_loss_vectorized(W, X, y, reg):
"""
结构化的SVM损失函数,使用向量来实现
输入和输出的SVM_loss_naive一致
"""
loss = 0.0
dW = np.zeros(W.shape) #初始化梯度为0
"""
实现结构化SVM损失函数,将损失存储在loss变量中
"""
scores = X.dot(W)
num_classes = W.shape[1]
num_train = X.shape[0]
scores_correct = scores[np.arange(num_train), y]
scores_correct = np.reshape(scores_correct, (num_train, -1))
margins = scores - scores_correct + 1
margins = np.maximum(0, margins)
margins[np.arange(num_train), y] = 0
loss += np.sum(margins) / num_train
loss += 0.5 * reg * np.sum(W * W)
"""
使用向量计算结构化SVM损失函数的梯度,把结果保存在dW
"""
margins[margins > 0] = 1
row_sum = np.sum(margins, axis=1) # 1 by N
margins[np.arange(num_train), y] = -row_sum
dW += np.dot(X.T, margins) / num_train + reg * W
return loss, dW
我们可以验证一下这两个算法的计算结果和计算时间
from cs231n.classifiers.linear_svm import svm_loss_naive
import time
#生成一个很小的SVM随机权重矩阵
W = np.random.randn(3073, 10) * 0.0001
tic = time.time()
loss_naive, grad_naive = svm_loss_naive(W, X_dev, y_dev, 0.000005)
toc = time.time()
print('Naive loss: %e computed in %fs' % (loss_naive, toc - tic))
from cs231n.classifiers.linear_svm import svm_loss_vectorized
tic = time.time()
loss_vectorized, _ = svm_loss_vectorized(W, X_dev, y_dev, 0.000005)
toc = time.time()
print('Vectorized loss: %e computed in %fs' % (loss_vectorized, toc - tic))
# The losses should match but your vectorized implementation should be much faster.
print('difference: %f' % (loss_naive - loss_vectorized))
可以看到向量化的计算方法明显快于普通循环方法,而且计算的结果是一样的
Naive loss: 8.846791e+00 computed in 0.157097s
Vectorized loss: 8.846791e+00 computed in 0.006006s
difference: -0.000000
在我们得到损失、梯度之后,我们继续使用SGD来最小化损失
def train(self, X, y, learning_rate=1e-3, reg=1e-5, num_iters=100,
batch_size=200, verbose=False):
"""
使用随机梯度下降来训练这个分类器
输入:
-X :一个numpy数组,维数为(N,D)
-Y : 一个numpy数组,维数为(N,)
-learning rate: float ,优化的学习率
-reg : float,正则化强度
-num_iters: integer, 优化时训练的步数
-batch_size:integer, 每一步使用的训练样本数
-ver bose : boolean, 若为真,优化时打印过程
输出:
一个存储每次训练的损失函数值的List
"""
num_train, dim = X.shape
num_classes = np.max(y) + 1 #假设y的值时0...K-1,其中K是类别数量
if self.W is None:
#简易初始化W
self.W = 0.001 * np.random.randn(dim,num_classes)
#使用随机梯度下降优化W
loss_history = []
for it in range(num_iters):
X_batch = None
y_batch = None
"""
从训练集中采样batch_size个样本和对应的标签,在这一轮梯度下降中使用。
把数据存储在X_batch中,把对应的标签存储在y_batch中
采样后,X_batch的形状为(dim,batch_size),y_batch的形状为(batch_size,)
"""
batch_inx = np.random.choice(num_train,batch_size)
X_batch = X[batch_inx,:]
y_batch = y[batch_inx]
loss,grad = self.loss(X_batch, y_batch,reg)
loss_history.append(loss)
"""
使用梯度和学习率更新权重
"""
self.W = self.W - learning_rate * grad
if verbose and it % 100 == 0:
print('iteration %d / %d: loss %f' % (it,num_iters,loss))
return loss_history
现在我们可以训练权重,最小化损失函数
from cs231n.classifiers.linear_classifier import LinearSVM
import time
svm = LinearSVM()
tic = time.time()
loss_hist = svm.train(X_train, y_train, learning_rate=1e-7, reg=2.5e4,
num_iters=1500, verbose=True)
toc = time.time()
print('That took %fs' % (toc - tic))
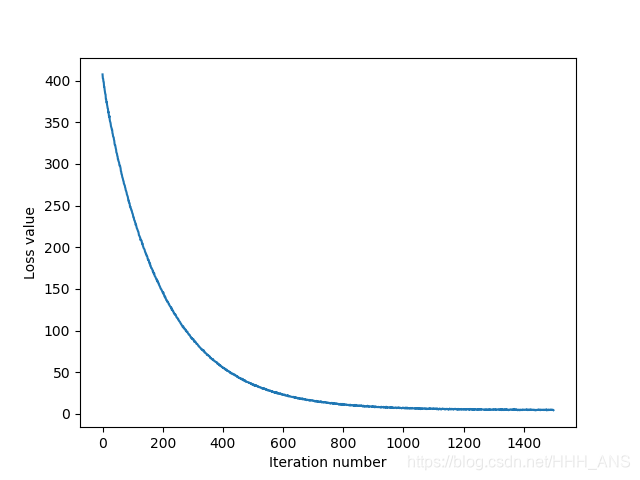
# A useful debugging strategy is to plot the loss as a function of
# iteration number:
plt.plot(loss_hist)
plt.xlabel('Iteration number')
plt.ylabel('Loss value')
plt.show()
# Write the LinearSVM.predict function and evaluate the performance on both the
# training and validation set
y_train_pred = svm.predict(X_train)
print('training accuracy: %f' % (np.mean(y_train == y_train_pred), ))
y_val_pred = svm.predict(X_val)
print('validation accuracy: %f' % (np.mean(y_val == y_val_pred), ))
然后我们可以在训练集和预测及上预测我们的准确率
def predict(self, X):
"""
Use the trained weights of this linear classifier to predict labels for
data points.
Inputs:
- X: A numpy array of shape (N, D) containing training data; there are N
training samples each of dimension D.
Returns:
- y_pred: Predicted labels for the data in X. y_pred is a 1-dimensional
array of length N, and each element is an integer giving the predicted
class.
"""
y_pred = np.zeros(X.shape[0])
scores = X.dot(self.W)
y_pred = np.argmax(scores, axis=1)
return y_pred
y_train_pred = svm.predict(X_train)
print('training accuracy: %f' % (np.mean(y_train == y_train_pred), ))
y_val_pred = svm.predict(X_val)
print('validation accuracy: %f' % (np.mean(y_val == y_val_pred), ))
training accuracy: 0.430408
validation accuracy: 0.358000
可以看到在训练集上有43%的正确率,验证集上有35%的正确率,为了提高正确率,我们可以使用验证集调整超参数(正则化强度和学习率)
from cs231n.classifiers.linear_classifier import LinearSVM
import time
"""
使用验证集去调整超参数(正则化和学习率)
"""
learning_rates = [2e-7,0.75e-7,1.5e-7,1.25e-7,0.75e-7]
regularation_strengths = [3e4,3.25e4,3.5e4,3.75e4,4e4,4.25e4,4.75e4,5e4]
"""
结果是一个词典,将形成(learning_rate,regularization_strength)的数组
"""
results = {}
best_val = -1 #出现的正确率最大值
best_svm = None #达到正确率最大值的SVM对象
"""
通过验证集选择最佳超参数,对于每一个超参数的组合在训练集训练一个线性SVM,
在训练集和测试集上计算它的准确度,然后在字典里存储这些值,另外,在best_val中
存储最好的验证集准确率,在best_svm中存储达到这个最佳值的SVM对象
"""
for rate in learning_rates:
for regular in regularation_strengths:
svm = LinearSVM()
svm.train(X_train,y_train,learning_rate=rate,reg=regular,num_iters=1000)
y_train_pred = svm.predict(X_train)
accuracy_train = np.mean(y_train==y_train_pred)
y_val_pred = svm.predict(X_val)
accuracy_val = np.mean(y_val==y_val_pred)
results[(rate,regular)]= (accuracy_train,accuracy_val)
if(best_val<accuracy_val):
best_val = accuracy_val
best_svm = svm
for lr, reg in sorted(results):
train_accuracy, val_accuracy = results[(lr,reg)]
print('lr %e reg %e train accuracy: %f val accuracy: %f' % (lr, reg, train_accuracy, val_accuracy))
print('best validation accuracy achieved during cross-validation: %f' % best_val)
输出入下:
lr 7.500000e-08 reg 3.000000e+04 train accuracy: 0.418571 val accuracy: 0.351000
lr 7.500000e-08 reg 3.250000e+04 train accuracy: 0.415714 val accuracy: 0.354000
lr 7.500000e-08 reg 3.500000e+04 train accuracy: 0.415918 val accuracy: 0.371000
lr 7.500000e-08 reg 3.750000e+04 train accuracy: 0.418980 val accuracy: 0.364000
lr 7.500000e-08 reg 4.000000e+04 train accuracy: 0.415306 val accuracy: 0.368000
lr 7.500000e-08 reg 4.250000e+04 train accuracy: 0.414082 val accuracy: 0.360000
lr 7.500000e-08 reg 4.750000e+04 train accuracy: 0.417143 val accuracy: 0.369000
lr 7.500000e-08 reg 5.000000e+04 train accuracy: 0.411429 val accuracy: 0.366000
lr 1.250000e-07 reg 3.000000e+04 train accuracy: 0.419184 val accuracy: 0.363000
lr 1.250000e-07 reg 3.250000e+04 train accuracy: 0.419388 val accuracy: 0.367000
lr 1.250000e-07 reg 3.500000e+04 train accuracy: 0.421020 val accuracy: 0.357000
lr 1.250000e-07 reg 3.750000e+04 train accuracy: 0.415510 val accuracy: 0.355000
lr 1.250000e-07 reg 4.000000e+04 train accuracy: 0.417347 val accuracy: 0.364000
lr 1.250000e-07 reg 4.250000e+04 train accuracy: 0.417551 val accuracy: 0.360000
lr 1.250000e-07 reg 4.750000e+04 train accuracy: 0.419796 val accuracy: 0.360000
lr 1.250000e-07 reg 5.000000e+04 train accuracy: 0.406735 val accuracy: 0.368000
lr 1.500000e-07 reg 3.000000e+04 train accuracy: 0.431837 val accuracy: 0.361000
lr 1.500000e-07 reg 3.250000e+04 train accuracy: 0.422653 val accuracy: 0.361000
lr 1.500000e-07 reg 3.500000e+04 train accuracy: 0.410816 val accuracy: 0.356000
lr 1.500000e-07 reg 3.750000e+04 train accuracy: 0.411837 val accuracy: 0.353000
lr 1.500000e-07 reg 4.000000e+04 train accuracy: 0.412653 val accuracy: 0.344000
lr 1.500000e-07 reg 4.250000e+04 train accuracy: 0.406531 val accuracy: 0.362000
lr 1.500000e-07 reg 4.750000e+04 train accuracy: 0.410816 val accuracy: 0.355000
lr 1.500000e-07 reg 5.000000e+04 train accuracy: 0.397347 val accuracy: 0.354000
lr 2.000000e-07 reg 3.000000e+04 train accuracy: 0.422245 val accuracy: 0.363000
lr 2.000000e-07 reg 3.250000e+04 train accuracy: 0.411224 val accuracy: 0.353000
lr 2.000000e-07 reg 3.500000e+04 train accuracy: 0.410816 val accuracy: 0.351000
lr 2.000000e-07 reg 3.750000e+04 train accuracy: 0.409592 val accuracy: 0.356000
lr 2.000000e-07 reg 4.000000e+04 train accuracy: 0.409184 val accuracy: 0.347000
lr 2.000000e-07 reg 4.250000e+04 train accuracy: 0.397347 val accuracy: 0.342000
lr 2.000000e-07 reg 4.750000e+04 train accuracy: 0.408571 val accuracy: 0.361000
lr 2.000000e-07 reg 5.000000e+04 train accuracy: 0.404082 val accuracy: 0.358000
best validation accuracy achieved during cross-validation: 0.371000
结果在设置的超参数循环中,最好的是0.371,比我们之前的提高了2%。如果继续尝试更多的超参数,可以到达40%左右