1 - 引言
这次,我们将使用Softmax来分类Cifar-10,过程其实很之前使用的SVM过程差不多,主要区别是在于损失函数的不同,而且Softmax分类器输出的结果是输入样本在不同类别上的概率值大小,Softmax分类器也叫多项Logistic回归
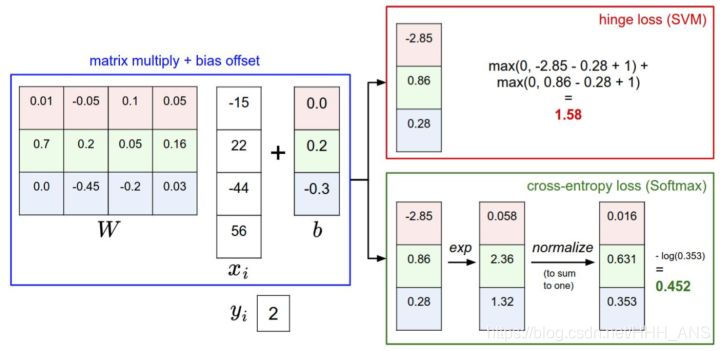
- 线性模型:
- Softmax模型:
- 损失函数模型corss-entropy loss:
那么对于线性模型
- 对W求导
我们得到了梯度函数后,可以观察一下函数,其实可以发现,这个函数的含义是,当我们有一个分值向量 ,损失函数对这个分值向量求导的结果等于这个向量里每个类别对应的概率值,但除了那个正确类别的概率值,它要再减去1,例如,我们的概率向量为p=[0.2,0.3,0.5],第二类为正确的类别,那么分支的梯度就为df = [0.2,-0.7,0.5]。然后再乘上 ,就可以得到我们的 了
2 - 具体步骤
根据上面的思想我们可以构建计算loss和dw的函数,首先,我们先简单的使用循环的方法来计算
def softmax_loss_naive(W, X, y, reg):
"""
使用循环计算softmax的loss、dw
输入:
- W : 一个numpy数组,维数(D,C)
- X :一个numpy数组,维数(N,D)
- y : 一个numpy数组,维数(N,)
返回:
- loss
- dw
"""
#初始化loss,dW
loss = 0.0
dW = np.zeros_like(W)
num_classes = W.shape[1]
num_train = X.shape[0]
for i in range(num_train):
scores = X[i].dot(W)
shift_scores = scores - max(scores)
loss_i = -shift_scores[y[i]] + np.log(sum(np.exp(shift_scores)))
loss += loss_i
for j in range(num_classes):
softmax_output = np.exp(shift_scores[j])/sum(np.exp(shift_scores))
if j == y[i]:
dW[:,j] += (-1 + softmax_output) * X[i]
else:
dW[:,j] += softmax_output * X[i]
loss /= num_train
loss += 0.5 * reg * np.sum(W*W)
dW = dW/num_train + reg * W
return loss, dW
但是使用循环对计算的开销太大,我们使用向量化的思想来优化这个算法
def softmax_loss_vectorized(W, X, y, reg):
"""
向量化的计算loss,dw
输入/输出:与softmax_loss_naive一致
"""
#初始化参数
loss = 0.0
dW = np.zeros_like(W)
num_classes = W.shape[1]
num_train = X.shape[0]
scores = X.dot(W)
shift_scores = scores - np.max(scores,axis=1).reshape(-1,1)
softmax_output = np.exp(shift_scores)/np.sum(np.exp(shift_scores),axis = 1).reshape(-1,1)
loss = -np.sum(np.log(softmax_output[range(num_train),list(y)]))
loss /= num_train
loss += 0.5 * reg * np.sum(W*W)
dS = softmax_output.copy()
dS[range(num_train),list(y)] += -1
dW = (X.T).dot(dS)
dW = dW / num_train + reg * W
return loss, dW
然后,我们来验证一下这两个算法的结果是否一样,和计算时间的差距
from cs231n.classifiers.softmax import softmax_loss_naive,softmax_loss_vectorized
import time
W = np.random.randn(3073, 10) * 0.0001
tic = time.time()
loss_naive, grad_naive = softmax_loss_naive(W, X_dev, y_dev, 0.00001)
toc = time.time()
print('naive loss: %e computed in %fs' % (loss_naive, toc - tic))
tic = time.time()
loss_vectorized, grad_vectorized = softmax_loss_vectorized(W, X_dev, y_dev, 0.00001)
toc = time.time()
print('vectorized loss: %e computed in %fs' % (loss_vectorized, toc - tic))
grad_difference = np.linalg.norm(grad_naive - grad_vectorized, ord='fro')
print('Loss difference: %f' % np.abs(loss_naive - loss_vectorized))
print('Gradient difference: %f' % grad_difference)
结果如下:
可以看到向量化的计算速度明显快于循环,并且计算的结果是一致的
naive loss: 2.347175e+00 computed in 0.154100s
vectorized loss: 2.347175e+00 computed in 0.006004s
Loss difference: 0.000000
Gradient difference: 0.000000
然后对于超参数的调整,还是和SVM一样,使用交叉验证,来得到最优的超参数
from cs231n.classifiers.linear_classifier import Softmax
results = {}
best_val = -1
best_softmax = None
learning_rates = [1e-7, 2e-7, 5e-7]
# regularization_strengths = [5e4, 1e8]
regularization_strengths = [(1 + 0.1 * i) * 1e4 for i in range(-3, 4)] + [(5 + 0.1 * i) * 1e4 for i in range(-3, 4)]
for lr in learning_rates:
for rs in regularization_strengths:
softmax = Softmax()
softmax.train(X_train, y_train, lr, rs, num_iters=2000)
y_train_pred = softmax.predict(X_train)
train_accuracy = np.mean(y_train == y_train_pred)
y_val_pred = softmax.predict(X_val)
val_accuracy = np.mean(y_val == y_val_pred)
if val_accuracy > best_val:
best_val = val_accuracy
best_softmax = softmax
results[(lr, rs)] = train_accuracy, val_accuracy
# Print out results.
for lr, reg in sorted(results):
train_accuracy, val_accuracy = results[(lr, reg)]
print('lr %e reg %e train accuracy: %f val accuracy: %f' % (lr, reg, train_accuracy, val_accuracy))
print('best validation accuracy achieved during cross-validation: %f' % best_val)
y_test_pred = best_softmax.predict(X_test)
test_accuracy = np.mean(y_test == y_test_pred)
print('softmax on raw pixels final test set accuracy: %f' % (test_accuracy, ))
结果如下:
lr 1.000000e-07 reg 7.000000e+03 train accuracy: 0.369184 val accuracy: 0.328000
lr 1.000000e-07 reg 8.000000e+03 train accuracy: 0.379592 val accuracy: 0.319000
lr 1.000000e-07 reg 9.000000e+03 train accuracy: 0.385918 val accuracy: 0.351000
lr 1.000000e-07 reg 1.000000e+04 train accuracy: 0.385510 val accuracy: 0.345000
lr 1.000000e-07 reg 1.100000e+04 train accuracy: 0.388776 val accuracy: 0.361000
lr 1.000000e-07 reg 1.200000e+04 train accuracy: 0.388776 val accuracy: 0.365000
lr 1.000000e-07 reg 1.300000e+04 train accuracy: 0.390204 val accuracy: 0.363000
lr 1.000000e-07 reg 4.700000e+04 train accuracy: 0.351020 val accuracy: 0.337000
lr 1.000000e-07 reg 4.800000e+04 train accuracy: 0.340816 val accuracy: 0.327000
lr 1.000000e-07 reg 4.900000e+04 train accuracy: 0.348980 val accuracy: 0.335000
lr 1.000000e-07 reg 5.000000e+04 train accuracy: 0.348367 val accuracy: 0.337000
lr 1.000000e-07 reg 5.100000e+04 train accuracy: 0.344286 val accuracy: 0.332000
lr 1.000000e-07 reg 5.200000e+04 train accuracy: 0.339184 val accuracy: 0.322000
lr 1.000000e-07 reg 5.300000e+04 train accuracy: 0.343878 val accuracy: 0.332000
lr 2.000000e-07 reg 7.000000e+03 train accuracy: 0.419184 val accuracy: 0.361000
lr 2.000000e-07 reg 8.000000e+03 train accuracy: 0.411633 val accuracy: 0.367000
lr 2.000000e-07 reg 9.000000e+03 train accuracy: 0.412245 val accuracy: 0.375000
lr 2.000000e-07 reg 1.000000e+04 train accuracy: 0.409388 val accuracy: 0.365000
lr 2.000000e-07 reg 1.100000e+04 train accuracy: 0.397347 val accuracy: 0.365000
lr 2.000000e-07 reg 1.200000e+04 train accuracy: 0.405306 val accuracy: 0.367000
lr 2.000000e-07 reg 1.300000e+04 train accuracy: 0.401224 val accuracy: 0.365000
lr 2.000000e-07 reg 4.700000e+04 train accuracy: 0.330612 val accuracy: 0.329000
lr 2.000000e-07 reg 4.800000e+04 train accuracy: 0.344898 val accuracy: 0.329000
lr 2.000000e-07 reg 4.900000e+04 train accuracy: 0.338571 val accuracy: 0.338000
lr 2.000000e-07 reg 5.000000e+04 train accuracy: 0.344490 val accuracy: 0.335000
lr 2.000000e-07 reg 5.100000e+04 train accuracy: 0.340612 val accuracy: 0.337000
lr 2.000000e-07 reg 5.200000e+04 train accuracy: 0.341020 val accuracy: 0.320000
lr 2.000000e-07 reg 5.300000e+04 train accuracy: 0.343265 val accuracy: 0.333000
lr 5.000000e-07 reg 7.000000e+03 train accuracy: 0.419184 val accuracy: 0.372000
lr 5.000000e-07 reg 8.000000e+03 train accuracy: 0.415714 val accuracy: 0.362000
lr 5.000000e-07 reg 9.000000e+03 train accuracy: 0.409388 val accuracy: 0.367000
lr 5.000000e-07 reg 1.000000e+04 train accuracy: 0.408776 val accuracy: 0.356000
lr 5.000000e-07 reg 1.100000e+04 train accuracy: 0.394490 val accuracy: 0.365000
lr 5.000000e-07 reg 1.200000e+04 train accuracy: 0.396531 val accuracy: 0.359000
lr 5.000000e-07 reg 1.300000e+04 train accuracy: 0.396122 val accuracy: 0.363000
lr 5.000000e-07 reg 4.700000e+04 train accuracy: 0.346735 val accuracy: 0.334000
lr 5.000000e-07 reg 4.800000e+04 train accuracy: 0.352245 val accuracy: 0.335000
lr 5.000000e-07 reg 4.900000e+04 train accuracy: 0.350816 val accuracy: 0.330000
lr 5.000000e-07 reg 5.000000e+04 train accuracy: 0.334898 val accuracy: 0.325000
lr 5.000000e-07 reg 5.100000e+04 train accuracy: 0.341633 val accuracy: 0.328000
lr 5.000000e-07 reg 5.200000e+04 train accuracy: 0.344082 val accuracy: 0.327000
lr 5.000000e-07 reg 5.300000e+04 train accuracy: 0.332653 val accuracy: 0.334000
best validation accuracy achieved during cross-validation: 0.375000
softmax on raw pixels final test set accuracy: 0.371000
最好的Softmax分类效果37%
最后我们可以可视化一下分类模板
# Visualize the learned weights for each class
w = best_softmax.W[:-1, :] # strip out the bias
w = w.reshape(32, 32, 3, 10)
w_min, w_max = np.min(w), np.max(w)
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
for i in range(10):
plt.subplot(2, 5, i + 1)
# Rescale the weights to be between 0 and 255
wimg = 255.0 * (w[:, :, :, i].squeeze() - w_min) / (w_max - w_min)
plt.imshow(wimg.astype('uint8'))
plt.axis('off')
plt.title(classes[i])
plt.show()
最终学习到的模板如下图所示,当图片越和模板接近时,就会被分到模板属于的那一类
