什么是Sqoop?
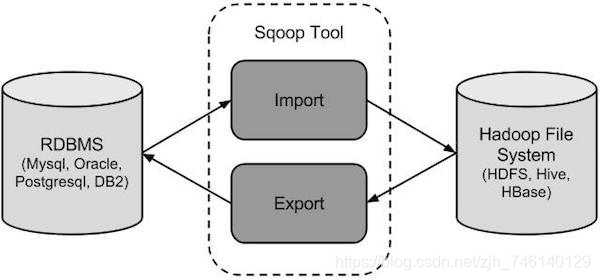
Sqoop 是 apache 旗下一款“Hadoop 和关系数据库服务器之间传送数据”的工具。
核心的功能有两个:
1、导入、迁入
2、导出、迁出
导入数据:MySQL,Oracle 导入数据到 Hadoop 的 HDFS、HIVE、HBASE 等数据存储系统
导出数据:从 Hadoop 的文件系统中导出数据到关系数据库 mysql 等 Sqoop 的本质还是一个命令行工具,和 HDFS,Hive 相比,并没有什么高深的理论。
Sqoop:
工具:本质就是迁移数据, 迁移的方式:就是把sqoop的迁移命令转换成MR程序
hive
工具,本质就是执行计算,依赖于HDFS存储数据,把SQL转换成MR程序
工作机制:
将导入或导出命令翻译成 MapReduce 程序来实现 在翻译出的 MapReduce 中主要是对 InputFormat 和 OutputFormat 进行定制。
Sqoop1和Sqoop2区别:
Sqoop1.x中,仅仅使用了一个Sqoop客户端,它是单用户的、架构部署简单。客户端发送命令到Sqoop,Sqoop转换为MapReduce作业运行在Hadoop集群环境上,从而实现RDBMS和Hadoop之间相互导入导出。Sqoop1.x只一个mapreduce作业,只有map没有reduce。
Sqoop2.x 中,引入了sqoop server集中化管理Connector,支持多种交互方式:命令行、Web UI、Rest API,所有的链接安装在sqoop server上,完善了权限管理机制(可配置管理员、使用者等角色),Connector规范化( 不再包含数据传输,格式转换、与Hive、Hbase交互等功能仅负责数据读写)。Sqoop2.x中的MapReduce作业既有Map也有Reduce。
Sqoop1和Sqoop2功能性对比:
| 功能 | Sqoop1 | Sqoop2 |
| 用于所有主要 RDBMS 的连接器 | 支持 | 不支持 解决办法: 使用已在以下数据库上执行测试的通用 JDBC 连接器: Microsoft SQL Server 、 PostgreSQL 、 MySQL 和 Oracle 。 此连接器应在任何其它符合 JDBC 要求的数据库上运行。但是,性能可能无法与 Sqoop 中的专用连接器相比 |
| Kerberos 安全集成 | 支持 | 不支持 |
| 数据从 RDBMS 传输至 Hive 或 HBase | 支持 | 不支持 解决办法: 按照此两步方法操作。 将数据从 RDBMS 导入 HDFS 在 Hive 中使用相应的工具和命令(例如 LOAD DATA 语句),手动将数据载入 Hive 或 HBase |
| 数据从 Hive 或 HBase 传输至 RDBMS | 不支持 解决办法: 按照此两步方法操作。 从 Hive 或 HBase 将数据提取至 HDFS (作为文本或 Avro 文件) 使用 Sqoop 将上一步的输出导出至 RDBMS |
不支持 按照与 Sqoop 1 相同的解决方法操作 |
部分资料来源:
1、https://www.cnblogs.com/qingyunzong/p/8807252.html
2、https://blog.csdn.net/lilychen1983/article/details/80241368