我的LeetCode代码仓:https://github.com/617076674/LeetCode
原题链接:https://leetcode-cn.com/problems/word-break-ii/description/
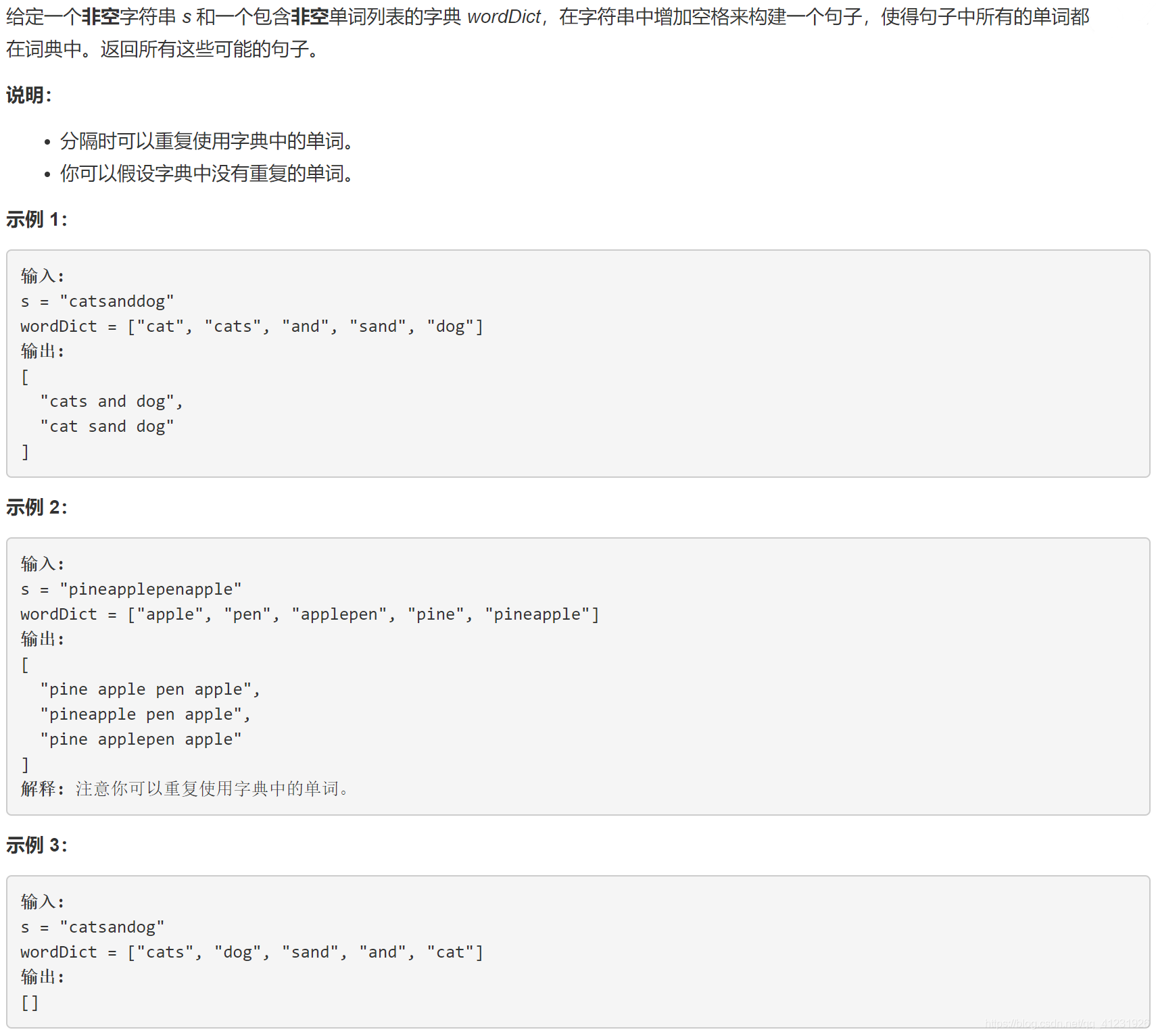
题目描述:
知识点:动态规划,回溯,记忆化搜索
思路一:动态规划(在LeetCode中提交会超时)
本题在LeetCode139——单词拆分的基础上进一步提高了要求,因此,除了LeetCode139——单词拆分中的状态定义和状态转移方程外,还需额外新增一个状态定义和状态转移方程,如下所述。
状态定义:
g(x, y) -------- s中范围在[x, y]内的子串能返回的所有可能的句子
状态转移:
如果s中范围在[x, y]内的子串出现在字典中,那么整个子串就是一个可能的返回的句子。
另外,我们需要去看s中范围在[x, j]和[j + 1, y],j = x, ..., y内的两个子串是否能被拆分,一旦发现两个子串均能被拆分的情况,就需要根据g[x, j]和g[j + 1, y],j = x, ..., y组合生成g[x, y]。
为了去重,用Set集合保存g(x, y)的结果,最后返回时转化成List集合即可。
时间复杂度和时间复杂度均与字符串以及字典的情况相关,但一定高于O(n ^ 2),其中n为字符串s的长度。
JAVA代码:
public class Solution1 {
public List<String> wordBreak(String s, List<String> wordDict) {
int n = s.length();
//canBreak[i][j]表示[i, j]子串能否被分割
boolean[][] canBreak = new boolean[n][n];
//results[i][j]表示[i, j]子串被分割的结果
Set<String>[][] results = new HashSet[n][n];
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
results[i][j] = new HashSet<>();
if(i == j){
String str = s.substring(i, i + 1);
canBreak[i][i] = include(str, wordDict);
if (canBreak[i][i]) {
results[i][i].add(str);
}
}
}
}
for (int gap = -1; gap >= - n + 1; gap--) {
for (int i = 0; i <= gap + n - 1; i++) {
String str = s.substring(i, i - gap + 1);
canBreak[i][i - gap] = include(str, wordDict);
if (canBreak[i][i - gap]) {
results[i][i - gap].add(str);
}
for (int j = -gap - 1; j >= 0; j--) {
if (canBreak[i][i + j] && canBreak[i + j + 1][i - gap]) {
canBreak[i][i - gap] = true;
Set<String> set1 = results[i][i + j];
Set<String> set2 = results[i + j + 1][i - gap];
for(String str1 : set1){
for(String str2 : set2){
results[i][i - gap].add(str1 + " " + str2);
}
}
}
}
}
}
return new ArrayList<>(results[0][n - 1]);
}
private boolean include(String string, List<String> wordDict) {
for (String s : wordDict) {
if (s.equals(string)) {
return true;
}
}
return false;
}
}思路二:回溯(在LeetCode中提交会超时)
回溯函数void nextWord(String s, List<String> wordDict, int index, String tempString)定义为从s字符串的第index个字符开始,寻找存在于wordDict中的下一个单词,其中tempString是s中[0, index - 1]范围内的子串可能产生的句子。
时间复杂度和时间复杂度均与字符串以及字典的情况相关。
JAVA代码:
public class Solution {
List<String> result = new ArrayList<>();
public List<String> wordBreak(String s, List<String> wordDict) {
nextWord(s, wordDict, 0, "");
return result;
}
private void nextWord(String s, List<String> wordDict, int index, String tempString){
if(index == s.length()){
result.add(tempString);
return;
}
for(String str : wordDict){
if(s.substring(index).startsWith(str)){
if(0 == tempString.length()){
nextWord(s, wordDict, index + str.length(), s.substring(index, index + str.length()));
}else{
nextWord(s, wordDict, index + str.length(), tempString + " " + s.substring(index, index + str.length()));
}
}
}
}
private boolean include(String string, List<String> wordDict) {
for (String s : wordDict) {
if(s.equals(string)) {
return true;
}
}
return false;
}
}思路三:记忆化搜索
利用一个hashMap记录某个字符串所能产生的句子的列表。
如果所要寻找的s已经存在在hashMap中,我们直接从hashMap中取得其值即可。否则,我们就需要进入我们的递归函数计算该字符串s所能产生的句子列表。
注意:当s的长度是0时,我们需要往list中添加空字符串元素。同时,在递归调用得到subList列表后,拼接字符串时需要判断所拼接的字符串sub是否为空字符串,如果是空字符串,我们不需要拼接空格字符。
时间复杂度和时间复杂度均与字符串以及字典的情况相关。
JAVA代码:
public class Solution {
HashMap<String, List<String>> hashMap = new HashMap<>();
public List<String> wordBreak(String s, List<String> wordDict) {
if(hashMap.containsKey(s)) {
return hashMap.get(s);
}
List<String> list = new ArrayList<>();
if(0 == s.length()){
list.add("");
return list;
}
for(String str : wordDict){
if(s.startsWith(str)){
List<String> subList = wordBreak(s.substring(str.length()), wordDict);
for(String sub : subList){
list.add(str + (Objects.equals("", sub) ? "" : " ") + sub);
}
}
}
hashMap.put(s, list);
return list;
}
}LeetCode解题报告:
