前言
众所周知,Flink内部为了实现它的高可用性,实现了一套强大的checkpoint机制,还能保证作用的Exactly Once的快速恢复。对此,围绕checkpoint过程本身做了很多的工作。在官方文档中,也为用户解释了checkpoint的部分原理以及checkpoint在实际生产中(尤其是大规模状态集下)的checkpoint调优参数。笔者结合官方文档,给大家做个总结,也算是对Flink checkpoint机理的一个学习。
Checkpoint快慢的性能指标
如果说我们想要对flink的checkpoint操作做调优,那么我们首先得有个衡量指标来展现当前checkpoint是否快慢。在这里,官方提供了以下2个metric指标:
- Checkpoint每次开始的时间。观察每次checkpoint开始的时间是为了检测在每次前后checkpoint中间是否存在空闲时间间隔。如果存在间隔时间,说明当前checkpoint都在合理时间内完成。
- 观察数据buffered的量。这个buffered动作是为了等待其它较慢数据流的stream barriers而设计的。这个偏向于checkpoint原理化的相关内容了。
但大体上,用户根据第一条就能够监测出应用的checkout快慢了。
相邻Checkpoint的间隔时间设置
我们假设一个使用场景,在极大规模状态数据集下,应用每次的checkpoint时长都超过系统设定的最大时间(也就是checkpoint间隔时长),那么会发生什么样的事情。
答案是应用会一直在做checkpoint,因为当应用发现它刚刚做完一次checkpoint后,又已经到了下次checkpoint的时间了,然后又开始新的checkpoint。最后就会造成一个很坏的结果:用户应用本身都没法跑了。。。
当然了,我们可能会说了,我们设置一下并行checkpoint数,或者说做增量checkpoint,不用每次做全量checkpoint。每次只checkpoint出对前一次checkpoint内的状态数据的增量改动。然后恢复的时候做状态改动的重放。
但是这里,我们可以采用一种更加直接有效的方法,设置连续checkpoint的时间间隔。形象地解释,就是强行在checkpoint间塞入空闲时间,如下图。
涉及的相关配置设置如下:
StreamExecutionEnvironment.getCheckpointConfig().setMinPauseBetweenCheckpoints(milliseconds)
外部State的存储选择
上小节的方法其实还并没有从本质上解决大规模状态集下checkpoint慢的问题,只是说它降低了这个慢的风险和造成的影响。在这里我们反复强调的是一个大规模状态,我们理理思路,因为规模之大,所以我们才会慢。那如果我们能找到一种更快的存储状态的介质(或者策略),那么这个过程也是能够变快的。
所以在这里,我们可以选择更加高效的外部存储介质来做State的存储(比如RocksDB),而不是仅限于存储于有限的内存空间里,或完全落地到磁盘上。这是我们在State Backend上做的一个选择。
Checkpoint的资源设置
当我们对越多的状态数据集做checkpoint时,需要消耗越多的资源。因为Flink在checkpoint时是首先在每个task上做数据checkpoint,然后在外部存储中做checkpoint持久化。在这里的一个优化思路是:在总状态数据固定的情况下,当每个task平均所checkpoint的数据越少,那么相应地checkpoint的总时间也会变短。所以我们可以为每个task设置更多的并行度(即分配更多的资源)来加速checkpoint的执行过程。
Checkpoint的task本地性恢复
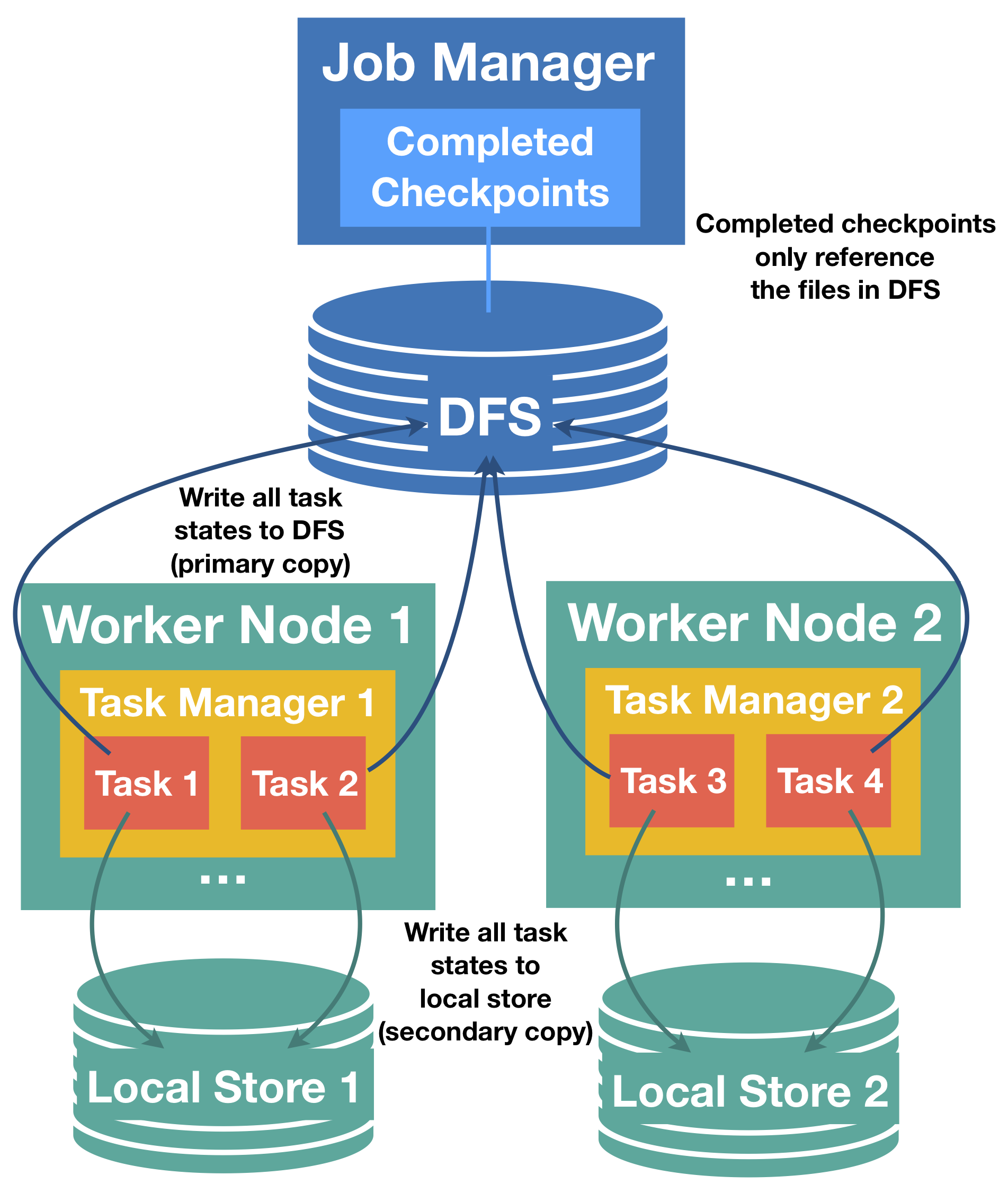
为了大家未来对checkpoint的优化,我们有必要在runtime级别的checkpoint过程。首先我们要明白一点,flink的checkpoint不是一个完全在master节点的过程,而是分散在每个task上执行,然后在做汇总持久化。这些task做的checkpoint数据在后面应用恢复时包括并行度扩增或减少时还能够重新打散分布。
为了快速的状态恢复,每个task会同时写checkpoint数据到本地磁盘和远程分布式存储,也就是说,这是一份双拷贝。只要task本地的checkpoint数据没有被破坏,系统在应用恢复时会首先加载本地的checkpoint数据,这样就大大减少了远程拉取状态数据的过程。此过程如下图所示:
引用
[1].https://ci.apache.org/projects/flink/flink-docs-master/ops/state/large_state_tuning.html