- `execution.checkpointing.interval`: 检查点之间的时间间隔(以毫秒为单位)。在此间隔内,系统将生成新的检查点
SET execution.checkpointing.interval = 6000;
- `execution.checkpointing.tolerable-failed-checkpoints`: 允许的连续失败检查点的最大数量。如果连续失败的检查点数量超过此值,作业将失败。
SET execution.checkpointing.tolerable-failed-checkpoints = 10;
- `execution.checkpointing.timeout`: 检查点的超时时间(以毫秒为单位)。如果在此时间内未完成检查点操作,作业将失败。
SET execution.checkpointing.timeout =600000;
- `execution.checkpointing.externalized-checkpoint-retention`: 外部化检查点的保留策略。`RETAIN_ON_CANCELLATION`表示在作业取消时保留外部化检查点。
SET execution.checkpointing.externalized-checkpoint-retention = RETAIN_ON_CANCELLATION;
- `execution.checkpointing.mode`: 检查点模式。`EXACTLY_ONCE`表示每个检查点只会在作业处理完全一次时生成。
SET execution.checkpointing.mode = EXACTLY_ONCE;
- `execution.checkpointing.unaligned`: 检查点是否对齐。如果设置为`true`,则检查点将在作业的所有任务完成之前生成。
SET execution.checkpointing.unaligned = true;
- `execution.checkpointing.max-concurrent-checkpoints`: 并发生成检查点的最大数量。在此数量的检查点生成之前,不会生成新的检查点。
SET execution.checkpointing.max-concurrent-checkpoints = 1;
- `state.checkpoints.num-retained`: 保留的检查点数量。超过此数量的检查点将被删除
SET state.checkpoints.num-retained = 3;
暂未使用
SET execution.checkpointing.interval = 6000;
SET execution.checkpointing.tolerable-failed-checkpoints = 10;
SET execution.checkpointing.timeout =600000;
SET execution.checkpointing.externalized-checkpoint-retention = RETAIN_ON_CANCELLATION;
SET execution.checkpointing.mode = EXACTLY_ONCE;
SET execution.checkpointing.unaligned = true;
SET execution.checkpointing.max-concurrent-checkpoints = 1;
SET state.checkpoints.num-retained = 3;
yaml 文件中 起作用的配置信息如下:
flinkConfiguration:
taskmanager.numberOfTaskSlots: "36"
state.backend: rocksdb
state.checkpoint-storage: filesystem
state.checkpoints.num-retained: "3"
state.backend.incremental: "true"
state.savepoints.dir: file:///flink-data/savepoints
state.checkpoints.dir: file:///flink-data/checkpoints
high-availability.type: kubernetes
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory # JobManager HA
high-availability.storageDir: file:///opt/flink/flink_recovery # JobManager HA数据保存路径
serviceAccount: flink
登录到
kubectl -n flink exec -it session-deployment-only-taskmanager-2-1 bash
查看 cat flink-conf.yaml
blob.server.port: 6124
kubernetes.jobmanager.annotations: flinkdeployment.flink.apache.org/generation:2
state.checkpoints.num-retained: 3
kubernetes.jobmanager.replicas: 2
high-availability.type: kubernetes
high-availability.cluster-id: session-deployment-only
state.savepoints.dir: file:///flink-data/savepoints
kubernetes.taskmanager.cpu: 4.0
kubernetes.service-account: flink
kubernetes.cluster-id: session-deployment-only
state.checkpoint-storage: filesystem
high-availability.storageDir: file:///opt/flink/flink_recovery
kubernetes.internal.taskmanager.replicas: 1
kubernetes.container.image: localhost:5000/flink-sql:1.14.21
parallelism.default: 1
kubernetes.namespace: flink
taskmanager.numberOfTaskSlots: 36
kubernetes.rest-service.exposed.type: ClusterIP
high-availability.jobmanager.port: 6123
kubernetes.jobmanager.owner.reference: blockOwnerDeletion:false,apiVersion:flink.apache.org/v1beta1,kind:FlinkDeployment,uid:fadef756-d327-4f19-b1b4-181d92c659eb,name:session-deployment-only,controller:false
taskmanager.memory.process.size: 6048m
kubernetes.internal.jobmanager.entrypoint.class: org.apache.flink.kubernetes.entrypoint.KubernetesSessionClusterEntrypoint
kubernetes.pod-template-file: /tmp/flink_op_generated_podTemplate_4716243666145995447.yaml
state.backend.incremental: true
web.cancel.enable: false
execution.target: kubernetes-session
jobmanager.memory.process.size: 1024m
taskmanager.rpc.port: 6122
kubernetes.container.image.pull-policy: IfNotPresent
internal.cluster.execution-mode: NORMAL
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory
kubernetes.jobmanager.cpu: 1.0
state.backend: rocksdb
$internal.flink.version: v1_14
state.checkpoints.dir: file:///flink-data/checkpoints
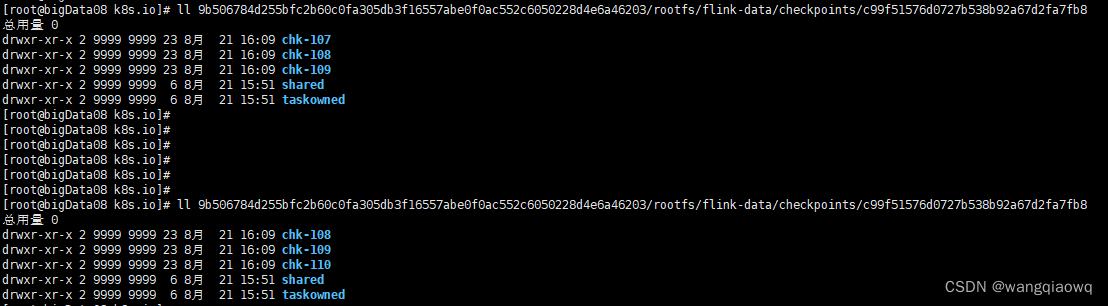
只产生3个chk文件了
一个chk-X代表了一次Checkpoint信息,里面存储Checkpoint的元数据和数据。
taskowned: TaskManagers拥有的状态
shared: 共享的状态
默认情况下,如果设置了Checkpoint选项,Flink只保留最近成功生成的1个Checkpoint。当Flink程序失败时,可以从最近的这个Checkpoint来进行恢复。但是,如果我们希望保留多个Checkpoint,并能够根据实际需要选择其中一个进行恢复,这样会更加灵活。Flink支持保留多个Checkpoint,需要在Flink的配置文件conf/flink-conf.yaml中,添加如下配置指定最多需要保存Checkpoint的个数,例如指定保留最近的10个Checkpoint(就是保留上面的10个chk-X):
state.checkpoints.num-retained: 10
ps1:Checkpoint目录如果删除,任务就无法指定从Checkpoint恢复了
ps2:如果job是失败了而不是手动cancel,那么无论选择上面哪种策略,state记录都会保留下来
ps3:使用RocksDB来作为增量checkpoint的存储,可以进行定期Lazy合并清除历史状态。
最后的yaml配置如下:
#Flink Session集群 源码请到
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
namespace: flink
name: session-deployment-only
spec:
image: 192.168.1.249:16443/bigdata/flink-sql:1.14.21
#image: localhost:5000/flink-sql:1.14.21
flinkVersion: v1_14
#imagePullPolicy: Never # 镜像拉取策略,本地没有则从仓库拉取
imagePullPolicy: IfNotPresent
ingress: # ingress配置,用于访问flink web页面
template: "flink.k8s.io"
className: "nginx"
annotations:
nginx.ingress.kubernetes.io/rewrite-target: "/"
flinkConfiguration:
taskmanager.numberOfTaskSlots: "48"
state.backend: rocksdb
state.checkpoint-storage: filesystem
state.checkpoints.num-retained: "20"
state.backend.incremental: "true"
state.savepoints.dir: file:///opt/flink/volume/flink-sp
state.checkpoints.dir: file:///opt/flink/volume/flink-cp
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory # JobManager HA
high-availability.storageDir: file:///opt/flink/volume/flink-ha # JobManager HA数据保存路径
serviceAccount: flink
jobManager:
replicas: 2
resource:
memory: "1024m"
cpu: 1
taskManager:
replicas: 1
resource:
memory: "6048m"
cpu: 4
podTemplate:
spec:
hostAliases:
- ip: "192.168.1.236"
hostnames:
- "sql.server"
- ip: "192.168.1.246"
hostnames:
- "doris.server"
containers:
- name: flink-main-container
env:
- name: TZ
value: Asia/Shanghai
volumeMounts:
- name: flink-volume #挂载checkpoint pvc
mountPath: /opt/flink/volume
volumes:
- name: flink-volume
persistentVolumeClaim:
claimName: flink-checkpoint-pvc
pvc:
#Flinnk checkpoint 持久化存储pvc
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: flink-checkpoint-pvc # checkpoint pvc名称
namespace: flink # 指定归属的名命空间
spec:
storageClassName: nfs-client #sc名称,更改为实际的sc名称
accessModes:
- ReadWriteMany #采用ReadWriteMany的访问模式
resources:
requests:
storage: 20Gi #存储容量,根据实际需要更改