欲装spark-2.4.0
linux环境有,java8 ,maven-3.6.0,hadoop-2.6.0-cdh5.7.0
下载源码并修改pom.xml里的文件下载地址
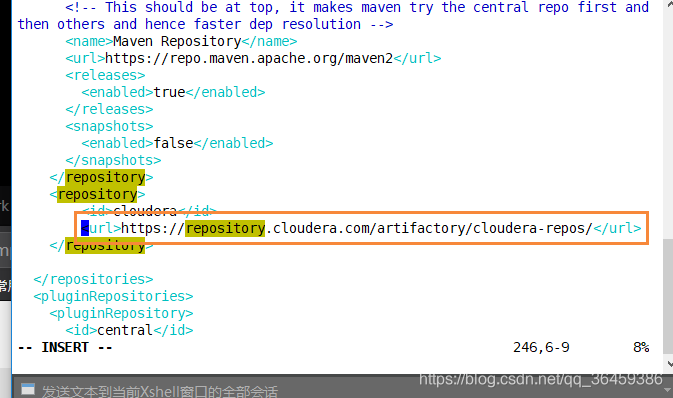
然后在spark目录下运行以下指令,设置需要对应的支持和名字
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Phadoop-2.6 -Phive -Phive-thriftserver -Pyarn -Dhadoop.version=2.6.0-cdh5.7.0
卡住不动,这是在检查环境变量,设置下
修改make-distribution.sh
这些部分加注释
 然后加上这么一段,hive=1就是让spark支持hive
然后加上这么一段,hive=1就是让spark支持hive

在idea里设置pom.xml
spark版本和hdfs的
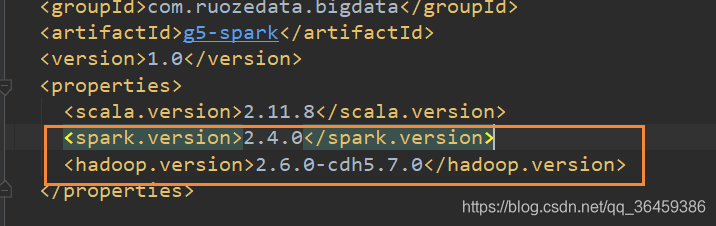
下载地址

依赖
pom.xml全部代码
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.ruozedata.bigdata</groupId>
<artifactId>g5-spark</artifactId>
<version>1.0</version>
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.4.0</spark.version>
<hadoop.version>2.6.0-cdh5.7.0</hadoop.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
RDD:弹性分布式数据集
代表一个不可变的(val),分区的,一群元素,这样可以并行化操作。弹性体现在依赖关系,如果rdd2挂了,会从rdd1重新计算。
看下源码
rdd类,泛型,抽象,继承序列化和logging,log和ser都是接口,本来是都要用with,但是第一个接口要用extends
abstract class RDD[T: ClassTag](
@transient private var _sc: SparkContext,
@transient private var deps: Seq[Dependency[_]]
) extends Serializable with Logging
五大特性:
1.rdd里面由分区构成
2.rdd作用函数相当于函数作用于每个分区上
3.rdd之间有依赖关系(rdd1=map>rdd2)
4.key-value类型的rdd(比如groupby)有一个分区器作用
5.数据在哪倾向于在哪做计算,移动计算>移动数据
分别对应源码的
1.protected def getPartitions
2.def compute
3.protected def getDependencies
4.@transient val partitioner
5. protected def getPreferredLocations
hdfs也是key-values的
key是偏移量
0 xxxxxxxx
第一行的长度(offset) yyyyyyyyyy
spark基本程序模板
import org.apache.spark.{SparkConf, SparkContext}
//spark自定义参数必须要spark.开头
object SparkContextApp {
def main(args: Array[String]): Unit = {
//本地模式
val sparkconf = new SparkConf().setMaster("local[2]").setAppName("asd")
//一个context运行在一个jvm。
val sc = new SparkContext(sparkconf)
sc.stop()
}
}