版权声明:转载请以链接形式注明出处 https://blog.csdn.net/pan_tian/article/details/80404114
消息队列的使用场景是怎样的? - 祁达方的回答 - 知乎 https://www.zhihu.com/question/34243607/answer/14073217
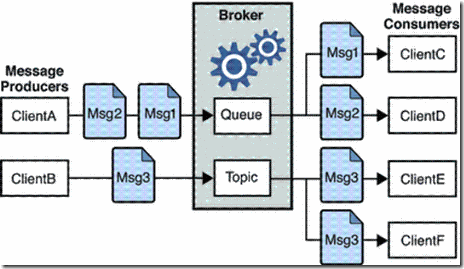
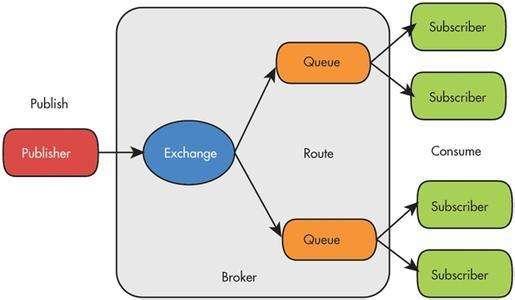










消息队列的主要特点是异步处理,是将比较耗时或不需要即时(同步)返回结果的操作作为消息放入消息队列。
主要的好处:
1、解耦:每个成员不必受其他成员影响,可以独立自主,只是通过一个中间件来联系,不会因为某个服务组件出现问题,而影响到整个系统的性能。
2、提速:消息生产者只需要把消息传给MQ就好,后续就不用管了,节省了消息生产者的时间。
3、削峰:对于消息消费方,把短时间内的高负载分散到更长的时间里来处理。服务组件通过消息中间件给别的组件发消息,别的组件即时当前没空处理,等到空闲时看到这个消息,就可以处理了。
4、广播:如果消息队列使用的是发布/订阅的模式的话,那么消息生产者只需发布一次,多个订阅者就可以从队列中读取消息,不需发布多次。
一般服务组件间进行通信,都是通过暴露数据接口的方式,这种通信方式比较直接,但系统之间的耦合度会比较高。如果系统的服务组件很多,互相调用起来,整个系统的接口调用关系会很复杂。通过消息中间件来通信的话,系统组件间的耦合度就大大降低。所以,
消息中间件的最主要的作用是解耦
。
另外每个服务组件的处理能力和承担的负载都是不同的,有些组件可能正忙得不亦乐乎,已经没法再接收新的请求,而有些组件现在可能根本就不在线,但不能让其他的组件都等着它。比较好的做法就是通知某个组件,你帮我干什么事情,干完了再回复我一下,也就是异步的方式。这样就不会因为某个服务组件出现问题,而影响到整个系统的性能。
MQ vs Webservice
Webservice
When you use a web service you have a client and a server:
1.If the server fails the client must take responsibility to handle the error.
2.When the server is working again the client is responsible of resending it.
3.If the server gives a response to the call and the client fails the operation is lost.
4.You don't have contention, that is: if million of clients call a web service on one server in a second, most probably your server will go down.
5.You can expect an immediate response from the server, but you can handle asynchronous calls too.
MQ
When you use a message queue like RabbitMQ, Beanstalkd, ActiveMQ, IBM MQ Series, Tuxedo you expect different and more fault tolerant results:
1.If the server fails, the queue persist the message (optionally, even if the machine shutdown).
2.When the server is working again, it receives the pending message.
3.If the server gives a response to the call and the client fails, if the client didn't acknowledge the response the message is persisted.
4.You have contention, you can decide how many requests are handled by the server (call it worker instead).
5.You don't expect an immediate synchronous response, but you can implement/simulate synchronous calls.
MQ的工作模式
主要有两种工作模式:一种是
生产者/消费者
(Producer/Consumer)模式;另一种是
发布/订阅
(Pub/Sub)模式。
生产/消费模式中有两种角色,消息生产者(Producer)负责生产消息,并把消息发送到队列中,然后消息消费者(Consumer)从队列中取出并且消费消息。
消息被消费以后,队列中就不再存储,所以其他消费者不可能消费到已经被消费的消息。 换句话说,存在多个消费者的情况下,对一个消息而言,只会有一个消费者可以消费它,所以生产/消费模式又称为
点对点(P2P)模式
。
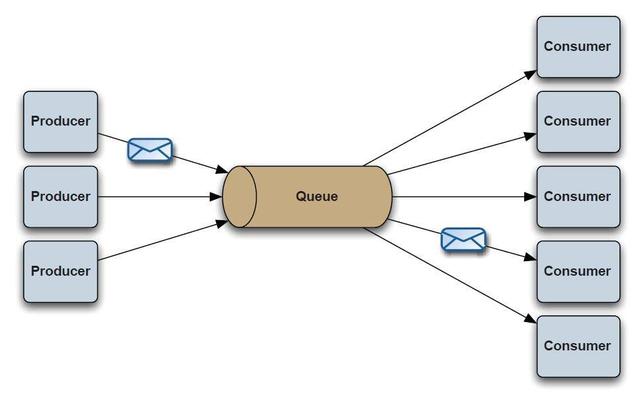
生产/消费模式是一种一对一的消息传递方式
在发布/订阅模式中,消息发布者(Publisher)将消息发布到某个主题(topic),同时有多个消息订阅者(Subscriber)会接收到该消息。和点对点方式不同,发布到主题的消息会被所有该主题的订阅者接收到,这是一种1对多的消息传递方式。
发布/订阅模式是一种一对多的消息传递方式
消息队列应用场景
以下介绍消息队列在实际应用中常用的使用场景:异步处理,应用解耦,流量削锋和消息通讯四个场景。
1、异步处理
场景说明:用户注册后,需要发注册邮件和注册短信。传统的做法有两种:串行的方式和并行方式。
串行方式
:将注册信息写入数据库成功后,发送注册邮件,再发送注册短信。以上三个任务全部完成后,返回给客户。
并行方式
:将注册信息写入数据库成功后,发送注册邮件的同时,发送注册短信。以上三个任务完成后,返回给客户端。与串行的差别是,并行的方式可以提高处理的时间。
假设三个业务节点每个使用50毫秒钟,不考虑网络等其他开销,则串行方式的时间是150毫秒,并行的时间可能是100毫秒。
因为CPU在单位时间内处理的请求数是一定的,假设CPU1秒内吞吐量是100次。则串行方式1秒内CPU可处理的请求量是7次(1000/150)。并行方式处理的请求量是10次(1000/100)。
小结
:如以上案例描述,传统的方式系统的性能(并发量,吞吐量,响应时间)会有瓶颈。如何解决这个问题呢?
引入消息队列,将不是必须的业务逻辑,异步处理。改造后的架构如下:
按照以上约定,用户的响应时间相当于是注册信息写入数据库的时间,也就是50毫秒。注册邮件,发送短信写入消息队列后,直接返回,因此写入消息队列的速度很快,基本可以忽略,因此用户的响应时间可能是50毫秒。因此架构改变后,系统的吞吐量提高到每秒20QPS。比串行提高了3倍,比并行提高了两倍!
2、应用解耦
场景说明:用户下单后,订单系统需要通知库存系统。传统的做法是,订单系统调用库存系统的接口。如下图:
传统模式的缺点:
假如库存系统无法访问,则订单减库存将失败,从而导致订单失败,订单系统与库存系统耦合。
如何解决以上问题呢?引入应用消息队列后的方案,如下图:
订单系统:用户下单后,订单系统完成持久化处理,将消息写入消息队列,返回用户订单下单成功
库存系统:订阅下单的消息,采用拉/推的方式,获取下单信息,库存系统根据下单信息,进行库存操作
假如:在下单时库存系统不能正常使用。也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦。
3、流量削锋
流量削锋也是消息队列中的常用场景,一般在秒杀或团抢活动中使用广泛!
应用场景:秒杀活动,一般会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般需要在应用前端加入消息队列。
可以控制活动的人数,可以缓解短时间内高流量压垮应用。
用户的请求,服务器接收后,首先写入消息队列。假如消息队列长度超过最大数量,则直接抛弃用户请求或跳转到错误页面。
秒杀业务根据消息队列中的请求信息,再做后续处理。
4、日志处理
日志处理是指将消息队列用在日志处理中,比如Kafka的应用,解决大量日志传输的问题。架构简化如下:
日志采集客户端,负责日志数据采集,定时写受写入Kafka队列;Kafka消息队列,负责日志数据的接收,存储和转发;日志处理应用:订阅并消费kafka队列中的日志数据。
以下是新浪kafka日志处理应用案例:
Kafka
:接收用户日志的消息队列;
Logstash
:做日志解析,统一成JSON输出给Elasticsearch;
Elasticsearch
:实时日志分析服务的核心技术,一个schemaless,实时的数据存储服务,通过index组织数据,兼具强大的搜索和统计功能;
Kibana
:基于Elasticsearch的数据可视化组件,超强的数据可视化能力是众多公司选择ELK stack的重要原因。
5、消息通讯
消息通讯是指,消息队列一般都内置了高效的通信机制,因此也可以用在纯的消息通讯。比如实现点对点消息队列,或者聊天室等。
点对点通讯:
客户端A和客户端B使用同一队列,进行消息通讯。
聊天室通讯:
客户端A,客户端B,客户端N订阅同一主题,进行消息发布和接收。实现类似聊天室效果。
以上实际是消息队列的两种消息模式,点对点或发布订阅模式。模型为示意图,供参考。
消息中间件产品
市场上出现过很多商用消息中间件产品,比如Sun的JMS等,还有很多开源消息引擎,比如ActiveMQ、Kafka等。另外像阿里、腾讯这样的大公司往往会开发自己的消息中间件,之所以要自己做,是因为这些大公司的业务场景相对固化,需要追求的是更高的性能。
中小公司一般没有能力造轮子,采用通用的开源产品是比较合适的。另外也可以使用阿里云、腾讯云这些云服务商的消息中间件产品。下面列举一些目前用的比较多的开源消息中间件。
(1)ActiveMQ/ApolloMQ
ActiveMQ是Apache出品的最流行的开源消息总线,同时也是一个完全支持JMS1.1和J2EE 1.4规范的 JMS Provider实现,使用Java语言编写。作为老牌消息队列,可谓历史悠久,但历史包袱也比较多。最新架构的产品为ApolloMQ。
(2)Kafka
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache顶级项目。Kafka主要特点是基于Pull的模式来处理消息消费,追求高吞吐量,设计目标就是用于日志收集和传输。
Kafka生态完善,其代码是用Scala语言编写,并且有很多不同编程语言的接口,尤其适合海量消息传递。
(3)RabbitMQ
RabbitMQ是一个在AMQP基础上完成的,可复用的企业消息系统。他遵循Mozilla Public License开源协议。由Erlang语言编写。
AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
(4)RocketMQ
这是由阿里开源的一款高性能、高吞吐量的消息中间件。与Kafka类似,同样专为海量消息传递打造,主张使用拉模式,天然的集群、HA、负载均衡支持。可以说RocketMQ包含了阿里十年来在电商中间件架构设计上积累的最宝贵的经验。
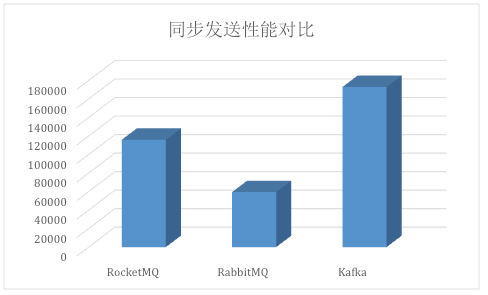
Kafka、RabbitMQ、RocketMQ消息中间件的对比 —— 消息发送性能
对比Kafka、RabbitMQ、RocketMQ发送小消息(124字节)的性能。这次压测我们只关注服务端的性能指标,所以压测的标准是:
不断增加发送端的压力,直到系统吞吐量不再上升,而响应时间拉长。这时服务端已出现性能瓶颈,可以获得相应的系统最佳吞吐量。
参考