机器学习100天,每天进步一点点。跟着GitHub开始学习!
英文项目地址https://github.com/Avik-Jain/100-Days-Of-ML-Code
中文项目地址https://github.com/MLEveryday/100-Days-Of-ML-Code
1 导入相应的库
import numpy as np #包含数学计算函数
import pandas as pd #用于导入和管理数据集
2 导入数据集
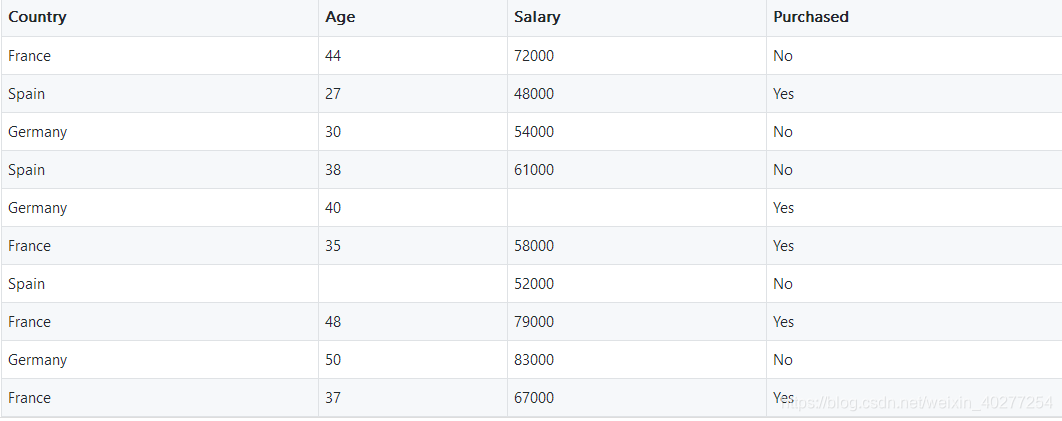
dataset = pd.read_csv('../datasets/Data.csv')
X = dataset.iloc[ : , :-1].values #iloc是取矩阵的某行某列,第一个冒号是所有行,第二个是除了最后一列的所有列
Y = dataset.iloc[ : , 3].values #取所有行,最后一列为依赖变量3 处理丢失数据
对缺失值进行处理的一般思路是使用这一列数据的“平均数”,“中位数”或“众数”来填充。
missing_values:遗失部分的数据用NaN的方式填补;
strategy:可选择mean,median,most_frequent,分别代表平均数 中间值 最常出现的数值;
axis:传0或者1,0代表处理列 ,1代表处理行。
from sklearn.preprocessing import Imputer #Imputer类对缺失数据进行处理
imputer = Imputer(missing_values = "NaN", strategy = "mean", axis = 0) #用特征列的均值替换缺失值
imputer = imputer.fit(X[ : , 1:3]) #用数据拟合X的前两列
X[ : , 1:3] = imputer.transform(X[ : , 1:3])4 解析分类数据
像Country和Purchased这两列数据,其实质是分类,而不是数值大小,使用虚拟编码对其进行处理。
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder() #LabelEncoder可将标签分配一个0——n_class-1之间的编码
X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0]) #拟合与转化所有行第0列
#Creating a dummy variable
onehotencoder = OneHotEncoder(categorical_features = [0]) #第0列进行独热编码
X = onehotencoder.fit_transform(X).toarray() #不加toarray()的话,输出稀疏的存储格式
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)5 拆分数据集为训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0) #训练集与测试集的比例一般为4:16 特征缩放
为了防止数值较大的自变量对数值较小的自变量的影响,或是为了在算法中使得收敛速度更快进行特征缩放。特征缩放有两种方法(标准化和正常化):

from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler() #针对某一特征维度进行标准化,经处理后的数据符合标准正态分布,均值为0,标准差为1
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)