本系列为100天机器学习学习笔记。详细请参考下方作者链接:
100天机器学习github:
https://github.com/MLEveryday/100-Days-Of-ML-Code
Day1

第1步:导入库
import numpy as np
import pandas as pd
数据集:
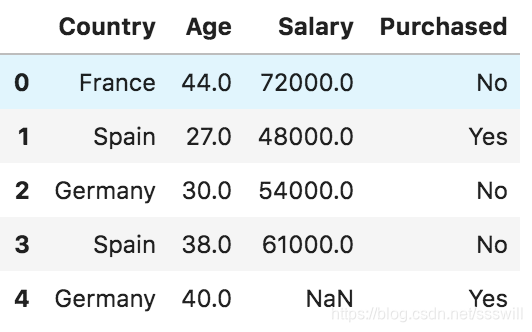
第2步:导入数据集
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[ : , :-1].values
Y = dataset.iloc[ : , 3].values
loc是显式索引,iloc是隐式索引(左闭右开)。
同时,.values把dataframe转为了np数组。所以,X,Y是这样的:
[['France' 44.0 72000.0]
['Spain' 27.0 48000.0]
['Germany' 30.0 54000.0]
['Spain' 38.0 61000.0]
['Germany' 40.0 nan]
['France' 35.0 58000.0]
['Spain' nan 52000.0]
['France' 48.0 79000.0]
['Germany' 50.0 83000.0]
['France' 37.0 67000.0]]
['No' 'Yes' 'No' 'No' 'Yes' 'Yes' 'No' 'Yes' 'No' 'Yes']
就是把df转为了np二维数组。
第3步:处理丢失数据
方法一,按照网站上面来:
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = "NaN", strategy = "mean", axis = 0)
imputer = imputer.fit(X[ : , 1:3])
X[ : , 1:3] = imputer.transform(X[ : , 1:3])
处理之后:

关于sklearn处理缺失值

图片来自:
https://blog.csdn.net/kancy110/article/details/75041923
同时,如果你在读入X,Y时候不加values,即认为他们就是dataframe,Imputer也是可以的。如下:
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = "NaN", strategy = "mean", axis = 0)
# imputer = imputer.fit(X.iloc[ : , 1:3])
# X.iloc[ : , 1:3] = imputer.transform(X.iloc[ : , 1:3])
X.iloc[ : , 1:3] = imputer.fit_transform(X.iloc[ : , 1:3])
print(X)
Country Age Salary
0 France 44.000000 72000.000000
1 Spain 27.000000 48000.000000
2 Germany 30.000000 54000.000000
3 Spain 38.000000 61000.000000
4 Germany 40.000000 63777.777778
5 France 35.000000 58000.000000
6 Spain 38.777778 52000.000000
7 France 48.000000 79000.000000
8 Germany 50.000000 83000.000000
9 France 37.000000 67000.000000
方法二:
利用pandas的fillna函数也是可以的。但是只针对df。
df['Age'].fillna(df['Age'].mean(),inplace=True)
第4步:解析分类数据
LabelEncoder 与OneHotEncoder:


图片来自:
https://www.jianshu.com/p/4b66d9586b06
Using the get_dummies will create a new column for every unique string
in a certain column:使用get_dummies进行one-hot编码
举例:
df = pd.get_dummies(df, columns=['c_2', 'c_3'])
下面这个链接很好:
https://blog.csdn.net/lujiandong1/article/details/52836051
好,回过来继续:
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder()
X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0])
把第一列的名字字符串变成了0,1,2
[[0 44.0 72000.0]
[2 27.0 48000.0]
[1 30.0 54000.0]
[2 38.0 61000.0]
[1 40.0 63777.77777777778]
[0 35.0 58000.0]
[2 38.77777777777778 52000.0]
[0 48.0 79000.0]
[1 50.0 83000.0]
[0 37.0 67000.0]]
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)
输出:
[[1.00000000e+00 0.00000000e+00 0.00000000e+00 4.40000000e+01
7.20000000e+04]
[0.00000000e+00 0.00000000e+00 1.00000000e+00 2.70000000e+01
4.80000000e+04]
[0.00000000e+00 1.00000000e+00 0.00000000e+00 3.00000000e+01
5.40000000e+04]
[0.00000000e+00 0.00000000e+00 1.00000000e+00 3.80000000e+01
6.10000000e+04]
[0.00000000e+00 1.00000000e+00 0.00000000e+00 4.00000000e+01
6.37777778e+04]
[1.00000000e+00 0.00000000e+00 0.00000000e+00 3.50000000e+01
5.80000000e+04]
[0.00000000e+00 0.00000000e+00 1.00000000e+00 3.87777778e+01
5.20000000e+04]
[1.00000000e+00 0.00000000e+00 0.00000000e+00 4.80000000e+01
7.90000000e+04]
[0.00000000e+00 1.00000000e+00 0.00000000e+00 5.00000000e+01
8.30000000e+04]
[1.00000000e+00 0.00000000e+00 0.00000000e+00 3.70000000e+01
6.70000000e+04]]
[0 1 0 0 1 1 0 1 0 1]
可以看到,第一列的0,1,2被转化为了100,010,001。也就是onehot编程。我认为用pandas的get_dummies更方便一些。
第5步:拆分数据集为训练集合和测试集合
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0)
print(X_train)
print(Y_train)
[[0.00000000e+00 1.00000000e+00 0.00000000e+00 4.00000000e+01
6.37777778e+04]
[1.00000000e+00 0.00000000e+00 0.00000000e+00 3.70000000e+01
6.70000000e+04]
[0.00000000e+00 0.00000000e+00 1.00000000e+00 2.70000000e+01
4.80000000e+04]
[0.00000000e+00 0.00000000e+00 1.00000000e+00 3.87777778e+01
5.20000000e+04]
[1.00000000e+00 0.00000000e+00 0.00000000e+00 4.80000000e+01
7.90000000e+04]
[0.00000000e+00 0.00000000e+00 1.00000000e+00 3.80000000e+01
6.10000000e+04]
[1.00000000e+00 0.00000000e+00 0.00000000e+00 4.40000000e+01
7.20000000e+04]
[1.00000000e+00 0.00000000e+00 0.00000000e+00 3.50000000e+01
5.80000000e+04]]
[1 1 1 0 1 0 0 1]
第6步:特征量化
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
#注意这里train与test对同一个train进行fit。不能train和test分别fit不同的数据集。
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
print(X_train)
print("-"*60)
print(X_test)
[[-1. 2.64575131 -0.77459667 0.26306757 0.12381479]
[ 1. -0.37796447 -0.77459667 -0.25350148 0.46175632]
[-1. -0.37796447 1.29099445 -1.97539832 -1.53093341]
[-1. -0.37796447 1.29099445 0.05261351 -1.11141978]
[ 1. -0.37796447 -0.77459667 1.64058505 1.7202972 ]
[-1. -0.37796447 1.29099445 -0.0813118 -0.16751412]
[ 1. -0.37796447 -0.77459667 0.95182631 0.98614835]
[ 1. -0.37796447 -0.77459667 -0.59788085 -0.48214934]]
------------------------------------------------------------
[[-1. 2.64575131 -0.77459667 -1.45882927 -0.90166297]
[-1. 2.64575131 -0.77459667 1.98496442 2.13981082]]