- Regular expression 正则表达式
正则表达式可以非常简洁的表达一组很长字符串的特征,所以把正则表达说成一行胜千言。
可以把一组字符串的特征或特点表达出来。
比如说有一组字符串:
无穷多个以L开头后面有一个或无穷多个H字符串。
‘LH’
‘LHH’
‘LHHH’
…
‘LHHHHHHH…’
正则表达式: LH+
‘PY’开头,后续存在不多于10个字符,后续字符不能是‘P’或‘H’
这样的字符有很多,但是如果我们枚举的话会很麻烦,所以可以用正则表达式来表示这组字符串的特点:PY[^PY]{0,10}
所以可以总结来说正则表达式是通用的字符串的表达框架,简洁表达一组字符串的表达式,针对字符串表达“简洁”和“特征”思想的工具,判断某字符串的特征归属。
- 正则表达式语法
| 操作符 | 说明 | 实例 |
|---|---|---|
| . | 表示任何单个字符 | |
| [] | 字符集,对单个字符给出取值范围 | [a,b,c]表示a,b,c,[a-z]表示a到z单个字母 |
| [^ ] | 非字符集,对单个字符给出排除范围 | [^abc] 表示非a或b或c的单个字符 |
| * | 前一个字符0次或无限次扩展 | abc*表示ab,abc,abcc,abccc等 |
| + | 前一个字符1次或无限次扩展 | abc+表示abc,abcc,abccc等 |
| ? | 前一个字符1次或1次扩展 | abc?表示ab,abc |
| | | 左右表达式任意一个 | abc|def表示abc或def |
| {m} | 扩展前一个字母m次 | ab{2}c表示abbc |
| {m,n} | 扩展前一个字母m次至n次 | ab{1,2}c表示 abc、abbc |
| \d | 数字,等价于[0-9] | |
| \w | 单词字符 | 等价于[A-Za-z0-9] |
- 如何用正则表达式提取数据
工具:re
正则表达式需要使用re模块中的findall函数。模块就是封装了许多相似功能函数的包,使用模块中的函数时需要先调用这个模块(import + 模块名),然后才能使用里面的函数。
import re
data='a1b88888a2b000000a3b00323'
result1=re.findall('a(.*?)b',data,re.S) #提取a、b之间的数字
result2=re.findall('b(.*?)a2',data,re.S) #提取数字88888
#运行结果:
result1=['1','2','3']
result2=['88888']
Findall函数第一个参数是提取的规则,括号内的是我们提取的内容,正则表达式根据括号前后的字符来定位提取数据的位置,括号所在位置代表我们所要提取的信息所在的位置然后用“(.*?)”代替。第二个参数是提取的对象,第三个参数的作用是可以换行匹配,正则表达式中,“.”的作用是匹配除“\n”以外的任何字符,也就是说,它是在一行中进行匹配。如果不使用re.S参数,则只在每一行内进行匹配,如果一行没有,就换下一行重新开始,不会跨行。而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,将“\n”当做一个普通的字符加入到这个字符串中,在整体中进行匹配。
上面的例子是一次提取一个元素,那么我来看一下如何一次提取两个元素:
import re
data='a1b1c---a2b2c---a3b3c---' #提取a、b、c之间的数字
result=re.findall('a(.*?)b(.*?)c',data)
print(result)
#结果
[('1', '1'), ('2', '2'), ('3', '3')]
上面就是一次提取两个元素,这两个元素放到一个元组里,因为被提取的字符串中有三个部分的字符串满足了所写正则表达式的条件,所以一共被提取出了三个元组,最后这三个元组被放到一个列表里。
找到感觉了没有,那么看看怎么爬取猫眼电影里的内容吧。
数据在哪提取?
数据在网页源码中提取
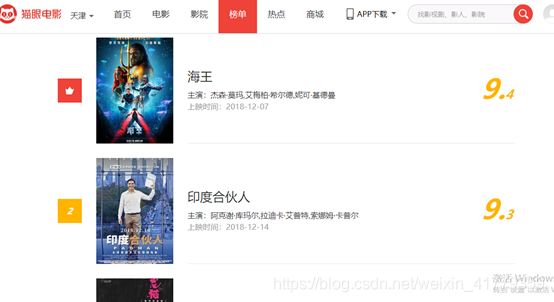
比如网页中可以看到这些电影的信息,比如排名,电影名,主演,上映时间,和评分。但我们并不是在我们看到的这个页面提取数据,因为这个页面只能看到但是我们得不到,我们能到的是这样网页的源码(爬虫的第二步),我们是在网页源码中提取数据。
右击网页,点击查看网页源代码就可以看到下面的这个页面。

首先我们先将看到的源代码复制下来(写爬虫的时候不需要复制,这里复制是为了演示正则表达式)
Str=‘
<p class="name"><a href="/films/1215919" title="印度合伙人" data-act="boarditem-click" data-val="{movieId:1215919}">印度合伙人</a></p>
<p class="name"><a href="/films/123" title="龙猫" data-act="boarditem-click" data-val="{movieId:123}">龙猫</a></p>’
Data=re.findall(‘<p class="name">< a href="/films/1215919" title="印度合伙人" data-act="boarditem-click" data-val="{movieId:1215919}">(.*?)</a></p>’,str,re.S)
#结果
['印度合伙人']
上面正则表达式存在的问题是,它只能提取‘印度合伙人’这一个电影的名字,如果网页中还有其他电影的名字,则提取不出来,因为上面写的提取规则只适用于那一个电影名字。
如果提取对象是下面的样子:
Str=“
<p class="name"><a href="/films/1215919" title="印度合伙人" data-act="boarditem-click" data-val="{movieId:1215919}">印度合伙人</a></p>
<p class="name"><a href="/films/123" title="龙猫" data-act="boarditem-click" data-val="{movieId:123}">龙猫</a></p>”
Data=re.findall(‘<p class="name"><a .*?>(.*?) </a></p>’,str,re.S)
print(Data)
#运行结果
['印度合伙人',‘龙猫’]_
这样就可以将两个电影名都提取出来,因为写的提取规则这个两个电影都适合,“.?”代表任意字符,如果在提取规则里只写“.?”而两边没有加括号,则代表在这个位置的字符是什么都可以,不影响我们要匹配的信息。
那么下面我们要一次性提取所有电影的名字和演员的信息
import re
data='<p class="name"><a href="/films/1215919" title="印度合伙人" data-act="boarditem-click" data-val="{movieId:1215919}">印度合伙人</a></p><p class="star">主演:阿克谢·库玛尔,拉迪卡·艾普特,索娜姆·卡普尔<p class="name"><a href="/films/123" title="龙猫" data-act="boarditem-click" data-val="{movieId:123}">龙猫</a></p><p class="star">主演:帕特·卡洛尔,蒂姆·达利,丽娅·萨隆加</p>'
result=re.findall('title="(.*?)".*?主演:(.*?)<',data,re.S)
print(result)
#运行结果:
[('印度合伙人', '阿克谢·库玛尔,拉迪卡·艾普特,索娜姆·卡普尔'), ('龙猫', '帕特·卡洛尔,蒂姆·达利,丽娅·萨隆加')]
这就是正则表达式,下篇文章是关于猫眼电影的爬虫案例,会有完整的代码。