一、概念
形式语言,描述语言的特征而不是具体的内容,常用于字符串的匹配。
二、语法和基本操作符
re库也可以采用string类型表示正则表达式,但更繁琐例如:
‘[1‐9]\\d{5}’ 相当于原生字符串的 ‘[1‐9]\d{5}’
‘\\d{3}‐\\d{8}|\\d{4}‐\\d{7}’ 相当于原生字符串的 ‘\d{3}‐\d{8}|\d{4}‐\d{7}’
建议:当正则表达式包含转义符时,使用raw string,否则两者是一样的。
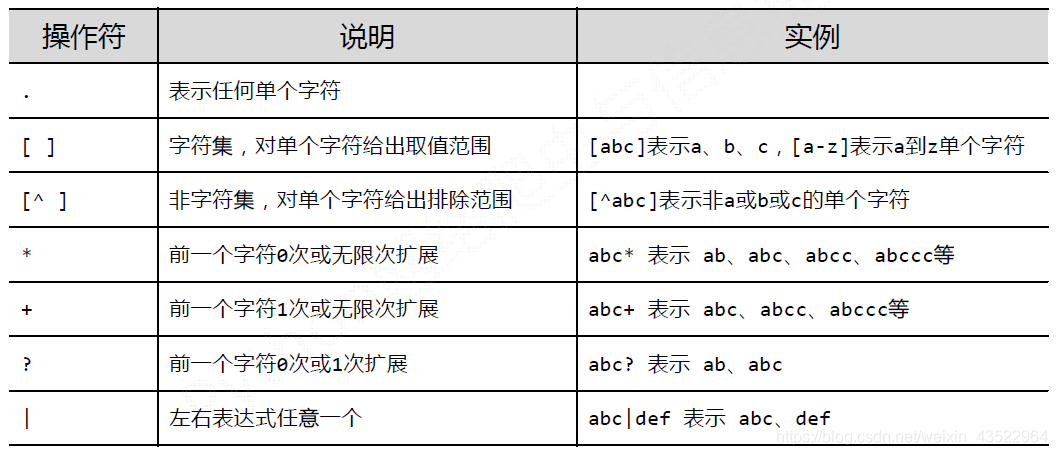
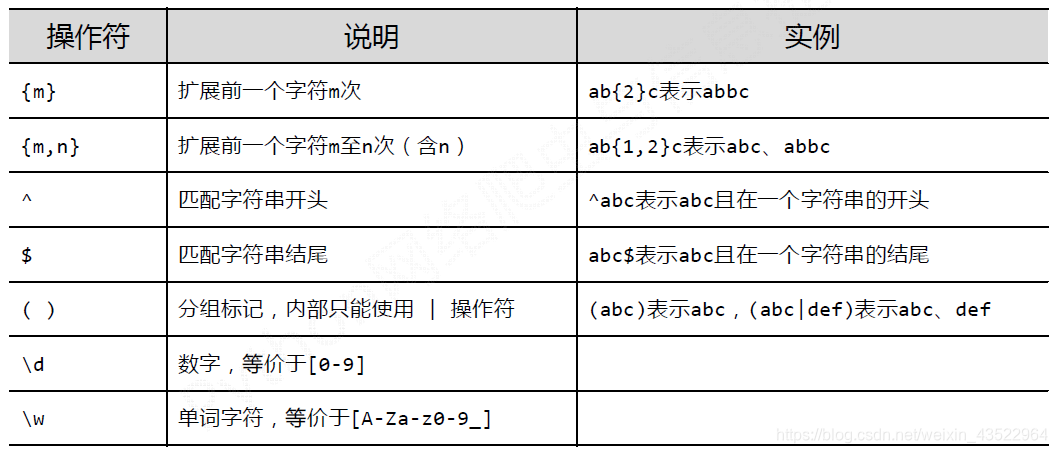
常用正则表达式:
| re表达式 | 内涵 |
|---|---|
| ^[A‐Za‐z]+$ | 以字母作为开头和结尾,长度>=1由,即26个字母组成的字符串 |
| ^[A‐Za‐z0‐9]+$ | 由26个字母和数字组成的字符串 |
| ^[0‐9][1‐9][0‐9]$ | 正整数形式的字符串 |
| [\u4e00‐\u9fa5] | 匹配中文字符 |
| \d{3}‐\d{8}|\d{4}‐\d{7} | 国内电话号码,010‐68913536 |
IP地址字符串形式的正则表达式(IP地址分4段,每段0‐255)
\d+.\d+.\d+.\d+ 或\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}
精确写法:
0‐99: [1‐9]?\d
100‐199: 1\d{2}
200‐249: 2[0‐4]\d
250‐255: 25[0‐5]
(([1‐9]?\d|1\d{2}|2[0‐4]\d|25[0‐5]).){3}([1‐9]?\d|1\d{2}|2[0‐4]\d|25[0‐5])
其他例子:
re.findall(r'[af].', 'abcaabbccfg') # 第一位为a或者f,第二位为任意字符
输出结果:
['ab', 'aa', 'fg']
re.findall(r'[af]+', 'abcafafaabbccfg') # 每个位置都必须是是a或者f,且长度至少为1(贪婪匹配)
输出结果:
['a', 'afafaa', 'f']
re.findall(r'[af]+', 'abcafafaabbccfg') # 每个位置都必须是是a或者f,且长度至少为1(贪婪匹配)
输出结果:
['a', 'afafaa', 'f']
//在开始位置匹配,开始不符合就返回nonetype,符合就返回不会再考虑后续位置的str
re.findall("^[a-z]{4}",'abcd0abcd2abb3abbbb')
re.findall("^[a-z]{4}",'3abcd0abcd2abb3abbbb')
输出:
['abcd']
[]
//在结尾匹配,结尾处不匹配就返回为nonetype不会再考虑其他的位置
string = "0abcdabce2abcd3abcab"
re.findall("[a-z]{2}$",string)
re.findall("[a-z]{4}$","0abcdabce2abcd3abc2ab")
输出:
['ab']
[]
//匹配中文
re.findall("[\u4e00-\u9fa5]{4}","0abcdabce2abcd3a匹配中文c2ab")
输出:
['匹配中文']
三、正则函数
在介绍具体的函数前,首先介绍其公共部分,即标记位和match对象
3.1 标记位flags
| 字符 | 含义 |
|---|---|
| re.I(Ignore) | 忽略正则表达式的大小写 |
| re.M(multiline) | 正则表达式中的^操作符能够将给定字符串的每行当作匹配开始 |
| re.S(dotalll) | 正则表达式中的.操作符能够匹配所有字符,默认匹配除换行外的所有字符 |
match对象是调用部分正则函数后返回的结果,包含很多的匹配信息。包括match属性和方法:
match属性包括:
| 字符 | 含义 |
|---|---|
| .string | 待匹配的文本 |
| .re | 匹配时使用的patter对象(正则表达式) |
| .pos | 正则表达式搜索文本的开始位置 |
| .endpos | 正则表达式搜索文本的结束位置 |
方法包括:
.group(0) 匹配结果
.start() 匹配的字符串在原始字符串的开始位置
.end() 匹配的字符串在原始字符串的结束位置
.span() 返回(.start(), .end())
3.2正则函数
3.2.1 re.search(pattren, string, flag)
功能:返回第一个匹配的对象,即便原始字符串中有很多匹配的str
match = re.search(r'[0-9]\d{5}', 'BIT 100081111111')
print(match)
print(type(match))
print(match.string)
print(match.re)
print(match.group(0))
print(match.pos)
print(match.endpos)
print(match.start())
print(match.end())
print(match.span())
输出结果:
<_sre.SRE_Match object; span=(4, 10), match='100081'>
<class '_sre.SRE_Match'>
BIT 100081111111
re.compile('[0-9]\\d{5}')
100081
0
16
4
10
(4, 10)
//忽略大小写
match = re.search(r'[A-Z]{3}', 'BIt 100081111111', re.I)
match.group(0)
输出:
'BIt'
3.2.2 re.match(pattern, string, flags)
功能:强制从头部开始匹配,如果头部的模式不符合则返回为空,即便原始字符串其他位置中有很多匹配的str
match = re.match(r'[1-9]\d{5}', 'BIT 100081')
type(match)
输出结果:
NoneType
3.2.3 findall(pattren, string, flags) # 返回列表
功能:返回所有的匹配对象,分段前进已经匹配的位置不会再次考虑。
match = re.findall(r'[0-9]\d{5}', 'BIT 100001,2000123') # 返回列表
print(type(match))
if match:
for i in match:
print(i)
输出结果:
<class 'list'>
100001
200012
3.2.4 split(pattern, string, maxsplit=0, flags=0) # 返回列表
功能:定位匹配位置后,将原始字符串切割(不会保留匹配的部分),maxsplits参数控制切割的次数。
re.split(r'[1-9]\d{5}', 'ABC100081TSU1000792') # 返回删除匹配字符后的部分
re.split(r'[1-9]\d{5}', 'ABC100081TSU1000792', maxsplit=1) # 返回删除匹配字符后的部分
输出结果:
['ABC', 'TSU', '2']
['ABC', 'TSU1000792']
3.2.5 finditer(pattern, string, flags=0) # 返回可迭代match对象
功能:类似于findall,区别在于前者返回匹配记过列表,次函数返回match列表
for m in re.finditer(r'[1-9]\d{5}', 'BIT100081 TSU100084'):
if m:
print(type(m),m.group(0))
输出结果:
<class '_sre.SRE_Match'> 100081
<class '_sre.SRE_Match'> 100084
3.2.6 re.sub(pattern, repl, string, count=0, flags=0)
功能:将匹配的位置用repl传入的参数替换,count控制替换的次数。
re.sub(r'[1-9]\d{5}', ':zipcode', 'BIT100081, TSU100084')
re.sub(r'[1-9]\d{5}', ':zipcode', 'BIT100081, TSU100084', count=1)
输出结果:
'BIT:zipcode, TSU:zipcode'
'BIT:zipcode, TSU100084'
四、等价用法
先生成正则表达式对象,在调用类的方法。后面会以search函数为例讲解:
regex = re.compile(pattern, flags=0)
∙ pattern : 正则表达式的字符串或原生字符串表示
∙ flags : 正则表达式使用时的控制标记
regex = re.compile(r'[1‐9]\d{5}')
将正则表达式的字符串形式编译成正则表达式对象
例如:
rst = re.search(r'[1‐9]\d{5}', 'BIT 100081') 函数式用法:一次性操作
pat = re.compile(r'[1‐9]\d{5}') 面向对象用法:编译后的多次操作
rst = pat.search('BIT 100081')
五、贪婪匹配与最小匹配
match = re.search(r'PY.*N', 'PYANBNCNDN')
match.group(0)
同时匹配长短不同的多项,返回哪一个呢?—> ‘PYANBNCNDN’
Re库默认采用贪婪匹配,即输出匹配最长的子串
最小匹配方式:
match = re.search(r'PY.*?N', 'PYANBNCNDN')
match.group(0)
'PYAN'
操作符说明
*?: 前一个字符0次或无限次扩展,最小匹配
+?: 前一个字符1次或无限次扩展,最小匹配
??: 前一个字符0次或1次扩展,最小匹配
{m,n}?: 扩展前一个字符m至n次(含n),最小匹配
正则入门代码
