机器学习模型
- 在完成特征抽取后,我们就将文本型数据转化成了规范的数字格式数据,可以送入机器学习模型或深度学习模型进行训练了。如果采用机器学习的方式,比较适合的模型有LR,LinearSVC, NaiveBayse,如果向量的维度不是很高很稀疏,一些树类模型如RandomForest, Xgboost, LightGBM也可以对其进行训练。
深度学习模型
- 随着近些年深度学习的发展,在计算力和数据量足够的条件下,深度学习越来越能发挥其深层特征抽取的能力,获得更好的预测效果和泛化效果。常见的模型有MLP, TextCNN, TextRNN, TextRCNN, LSTM, GRU, FastText,Bert… 这里以TextCNN举例讲解一个深度学习模型的构建
LSTM
-
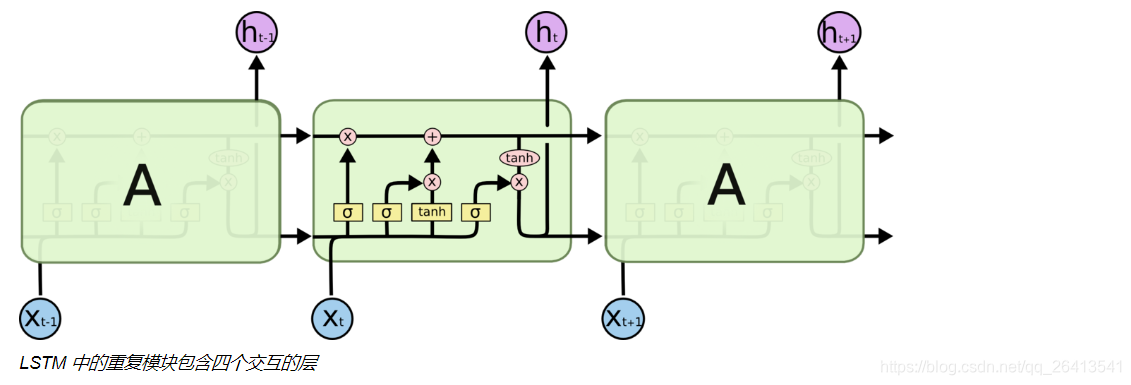
LSTM是RNN的一个变体,目的是解决RNN循环次数增加后,会产生梯度消失现象导致导致模型不能很好的学习长期依赖信息的问题。
-
RNN结构中,本层输入和上层的输出用一个很简单的tanh进行融合。
普通RNN结构

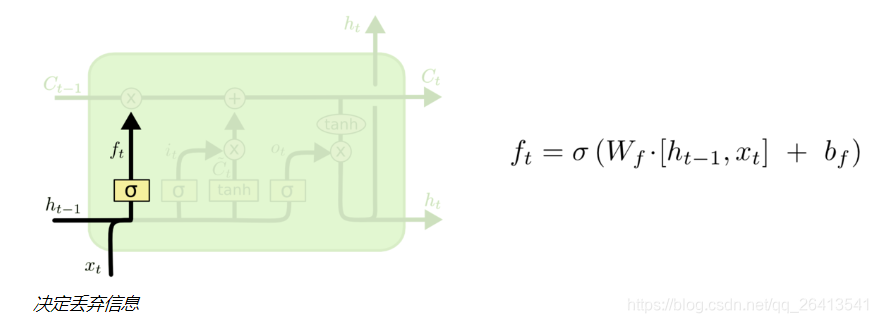
遗忘门
- 遗忘门由上层输出和本轮输入共同决定,决定的方式是sigmoid输出一个0-1的值(这个值往往可以看做是非0即1的),当这个值f为0时,之前的状态C(t-1)与之点乘变成0,之前的状态便被遗忘,反之之前的状态与1点乘,原始信息得以保留。
更新门
- 遗忘门是对之前的信息做一个过滤,来确定遗忘还是记住之前的信息状态C(t-1)
- 除此之外,我们还要对当前输入信息X(t)做一个过滤,这就是更新门的作用
- 更新门由两部分i(t)和C(t-1)组成,这两部分都由上轮输出h(t-1)和本轮输出x(t)共同决定,i(t)的作用是用一个sigmoid函数产生一个近似0或1的值来确定是否保留C(t),而C~(t)则是通过非线性函数tanh将x(t)和h(t-1)融合产生的类状态信息。
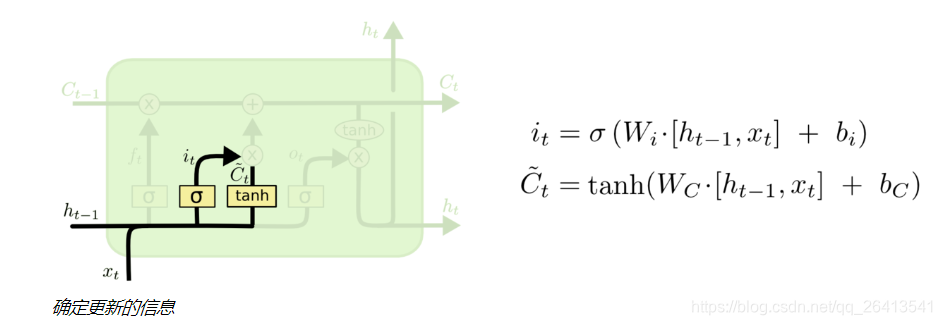
细胞状态
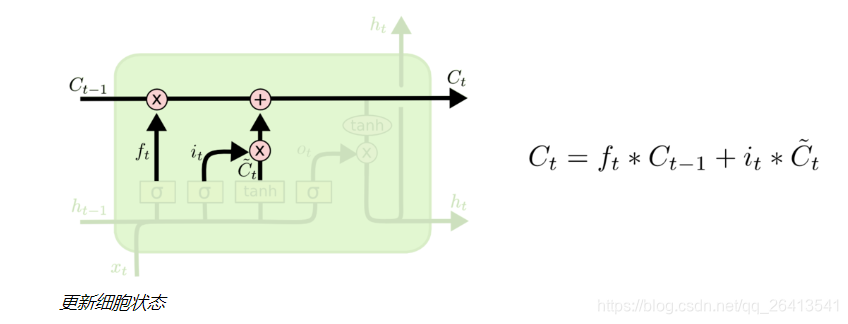
- LSTM的可以记忆长期依赖信息的核心就是细胞状态,它是一个贯通多个细胞单元的单向传送带,只有一些很基本的点乘和叠加操作,状态(也就是信息)在上面的长期保持很容易。
- 之前的状态先经过状态门的点乘,确定下来是否被保留,在附加上更新门增添的信息,这样就构成了新的细胞状态C(t)
- 注意,状态C(t)并不是输出h(t),它是保留了长期记忆信息的输出辅助。
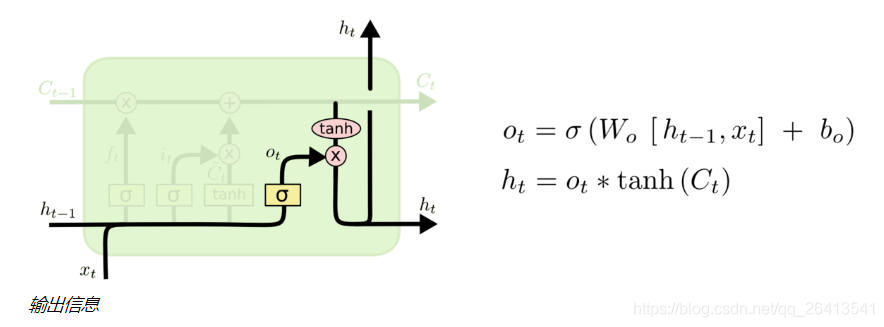
输出门
- 状态C(t)并不是输出h(t),它是保留了长期记忆信息的输出辅助,所以自然的他要和上轮输出h(t-1)、本轮输入X(t)构成本轮输出信息h(t)。
- 输出门也是由两个部分构成,类似于更新们,sigmoid的作用是控制信息是否保留,tanh的作用是引入非线性。
循环往复
- 在一个神经细胞当中,信息经历了遗忘门、更新门和输出门三个部分产生了变化,将这个过程在多个神经细胞中不断循环,就构成了LSTM
超参数调节
- LSTM的超参数并不是很多,核心参数有以下几个:
① units 细胞个数
② input_dim 输入向量的最大值不超过多少
③ output_dim 输出向量的维度
④ input_length 输入向量的维度,当下一层接的是Flatten层的时候,这个参数是必须指定的,用于Flatten层维度的计算。
⑤ return_sequences 是返回一个最终输出,还是所有细胞产生的输出序列,当使用两层LSTM的时候,需要将第一层的return_sequences设置为True
⑥ dropout 控制过拟合
⑦ learning_rate 学习速率
⑧ batch_size 批数量
⑨ epoch 轮次
⑩ Optimizer 优化器(Adam,Momenten,RMSprop)
TextCNN
- TextCNN是处理文本问题的卷积神经网络,因为文本数据和图像数据略有不同,所以TextCNN较CNN有一些微小的变化。
嵌入层
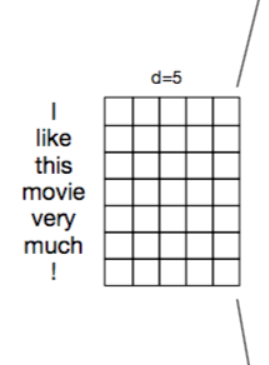
- 嵌入层的作用是将计算机不能理解的文本数据转化成可以理解的向量化表示。
- 一般是使用稠密的向量化表示如Word2vec或者Glove,比较少的情况是经过pad_sequence补齐的Tokenizer,一般不使用词袋模型CountVectorizer或者TF-IDF,因为这些方式产生的向量过于稀疏且不能很好的表示词汇之间的相关性
- 词嵌入的方式有两种:
①随机初始化参数,自己从头学习,过程比较缓慢,但是如果语料库足够的话,训练出来的词嵌入会比较好的拟合当前语料。
②下载预训练好的词嵌入,赋值给词嵌入矩阵,然后进行微调,微调的方法是将参数trainable设置为True,还有更好但也更麻烦的方式是从输出层到输入层逐层微调的歧视性学习。
卷积层
- 卷积层的作用是特征抽取
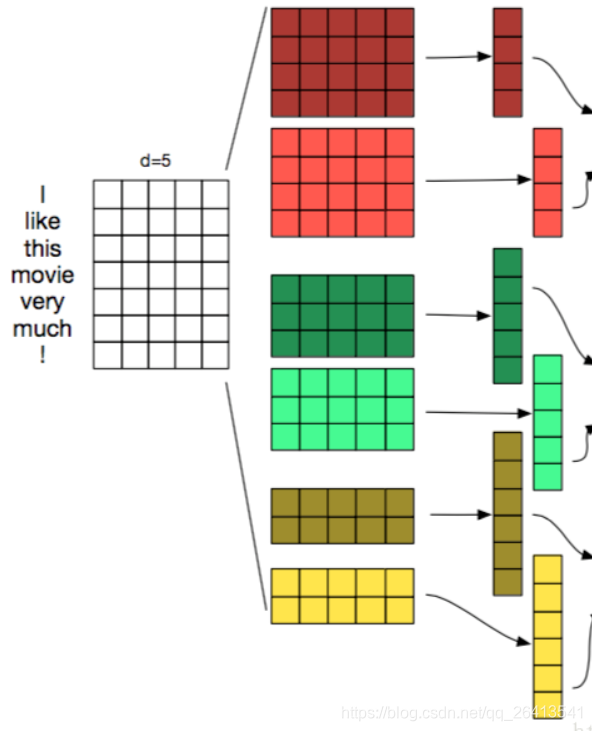
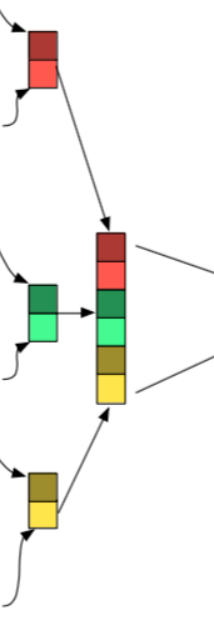
- TextCNN的卷积层和CNN中的很类似,都是用一个滤窗去和原矩阵相乘,再将这些值相加得到Feature Map,相当于将原来n维的词向量降维到1维,这1维综合了原来多维词向量中包含的信息。
- 下图中的三个部分,左边是词嵌入矩阵WordEmbedding,中间是滤窗Filter,右边是运算后的结果Feature Map
- TextCNN中滤窗的大小,必须要包含一个完整的词向量,在横向的维度中,这个大小是不能改变的,而纵向的大小可以调节,其意义相当于每次从n个单词中抽取信息,和N-gram有异曲同工之妙。
- 卷积层可以设置的参数有滤窗的个数,和滤窗的大小,以下图为例,尺寸为2,3,4的滤窗,每个尺寸都构建了两个滤窗,一共6个。
- 不同尺寸的滤窗可以分属不同的channel
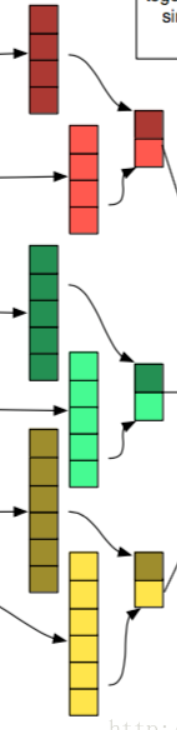
池化层
- 池化层的作用是特征平移不变性,最大池化层操作的方式是仅保留原始Feature Map中最大的值而舍弃掉其余的部分。
- 常见的有最大池化层和平均池化层,一般认为最大池化层的效果更好一些。
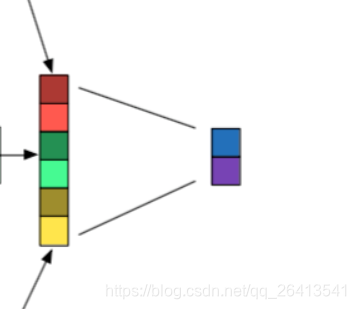
拼接层
- 将多个maxpooling得到的结果拼接成一个一维的长向量
全连接层
- 最后一般还会接一至两个全连接层,作为隐藏层和输出层,隐藏层的激活函数一般是relu或者tanh,如果是分类问题,输出层的激活函数一般是softmax。
超参数调节
① 初始化词向量,一般是word2vec或者Glove,注意不要使用One-Hot Vectors
② 卷积核尺寸,1-10之间,一般认为文本越长,需要的卷积核尺寸越大,用以捕捉不同词之间的共现关系,该参数对最终结果影响较大。
③ 每种尺寸卷积核数量,100-600之间,可以理解未某种意义上的epoch,该数值越大,训练时间越长。
④ 激活函数的选择,用来带来非线性表达能力,一般relu和tanh比较常见,输出层的激活函数可能是sigmoid或者是softmax
⑤ 池化层的选择,带来特征平移不变性,一般使用maxpooling1D
⑥ 正则化项,对最终效果影响较小。
FastText
- FastText是facebook开源的一个词向量与文本分类工具,典型应用场景是“带监督的文本分类问题”。
- FastText提供简单而高效的文本分类和表征学习的方法,性能比肩深度学习而且速度更快
- FastText的结构特点可以分为3个部分:
① 在输入层使用基于N-Gram的特征抽取
② 在隐藏层使用无激活函数的线性运算(求和或平均)
③ 在输出层使用层次化SoftMax直接输出分类结果 - FastText可以执行的任务有两类:
① 文本分类任务
② 词向量学习 - FastText和Word2vec的共同点:
① 都是用word embedding的稠密向量表达形式
② 优化结构类似,都采用层次化softmax进行加速和优化和线性的激活函数 - FastText和Word2vec的区别:
① Word2vec的输出是词向量,而FastText输出的是分类类别,而中间产生的词向量不会被保留。
② Word2vec的输入是term,而FastText的输入是sentence,FastText会自动的将其分词并运行N-Gram
朴素贝叶斯
- 朴素贝叶斯基于条件独立假设和贝叶斯公式,属于生成式模型,运算速度比较快,在有大量样本的情况下效果尚可。
- 虽然独立假设的判断并非完全正确,但是极大的简化了运算。
- 贝叶斯公式: P(A|B) = P(B|A) P(A) / P(B)
- 其中A代表标签,B代表特征,这样就把通过特征预测标签的问题转化为通过已有标签中某特征的分布/某标签比例/某特征比例三者间的统计运算。
- 为了避免某特征B的出现概率为零导致上述公式分母为零无法运算的问题,引入拉普拉斯平滑,将P(B)+1
- 朴素贝叶斯常用的模型有三种:
① 高斯模型: 处理特征是连续型变量的情况
② 多项式模型: 最常见,要求特征是离散数据
③ 伯努利模型: 要求特征是离散的,且为布尔类型,即true和false,或者1和0