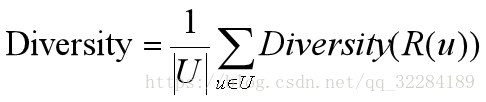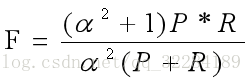推荐系统评价指标
2.1 覆盖率
覆盖率描述了一个推荐系统对物品长尾的发掘能力,最简单的覆盖率的定义为推荐系统能够推荐出来的物品占总物品集合的比列。假设系统用户的集合为U,推荐系统为每个用户推荐一个长度为N的物品列表R(u)。那么推荐系统的覆盖率可以通过下面公式计算。
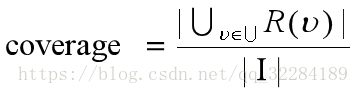
2.2 多样性
用户的兴趣是广泛的,如果用户的推荐列表比较多样,覆盖了用户绝大多数的兴趣点,那么就会增加用户找到感兴趣物品的概率,多样性描述了推荐列表中物品两两之间的不相似性,假设s(i,j)
[0,1]定义了物品i和j之间的相似度,那么用户u的推荐列表R(u)的多样性定义如下:
而推荐系统整体的多样性可以定义为所有用户推荐列表多样性的平均值:
2.3 准确度
预测准确度度量一个推荐系统或者推荐算法预测用户行为的能力, 这个指标是最终要的推荐系统离线评测指标。
2.3.1 评分预测:
评分预测的预测准确度一般通过均方根误差(RMSE)和平均绝对误差(MAE)计算,对于测试集的一个用户u和物品i,令
是用户u对物品i的实际评分,而
python代码如下:
其中records存放的是用户的评分数据,records[i]=[u,i,rui,pui],其中rui是用户u对物品i的实际评分,pui是算法预测出来的用户u对物品i的评分。
import math def RMSE(records): return math.sqrt(sum([(rui-pui)*(rui-pui) for u,i,rui,pui in records])/float(len(records)))MAE采用绝对值计算预测误差,它的定义为:
python代码如下:
import math def MAE(records): return sum([abs(rui,pui) for u,i,pui,rui in records])/float(len(records))2.3.2 TopN推荐:
再推荐服务时,如果一般给用户一个推荐列表,则这种推荐叫做TopN推荐,TopN推荐的预测准确率一般通过准确率和召回率来度量,令R(u)是根据用户在训练集上的行为给用户做出的推荐列表,而T(u)是用户在测试集上的行为列表,那么推荐结果的召回率为:
推荐结果的准确率定义为:
数据集为data[i] = [u,i,source]其中u为用户,i为物品,source可有可无,train为训练集,test为测试集,划分训练集与测试集的代码可以参考:
def SplitData(Data,M,k,seed): ''' 划分训练集和测试集 :param data:传入的数据 :param M:测试集占比 :param k:一个任意的数字,用来随机筛选测试集和训练集 :param seed:随机数种子,在seed一样的情况下,其产生的随机数不变 :return:train:训练集 test:测试集,都是字典,key是用户id,value是电影id集合 ''' data=Data.keys() test=[] train=[] random.seed(seed) # 在M次实验里面我们需要相同的随机数种子,这样生成的随机序列是相同的 for user,item in data: if random.randint(0,M)==k: # 相等的概率是1/M,所以M决定了测试集在所有数据中的比例 # 选用不同的k就会选定不同的训练集和测试集 for label in Data[(user,item)]: test.append((user,item,label)) else: for label in Data[(user, item)]: train.append((user,item,label)) print "splitData successed!" return train,test在调用函数时:(train, test) = SplitData(UI_label, 10, 5, 10)传入不同参数,可以的到不同的结果。
计算召回率和准确率的代码如下:
def recallAndPrecision(self, train=None, test=None, k=8, nitem=10): train = train or self.traindata test = test or self.testdata hit = 0 recall = 0 precision = 0 for user in train.keys(): tu = test.get(user, {}) rank = self.recommend(user, train=train, k=k, nitem=nitem) for item, _ in rank.items(): if item in tu: hit += 1 recall += len(tu) precision += nitem return (hit / (recall * 1.0), hit / (precision * 1.0))
有时,我们不单独去用召回率和准确率去评价推荐结果,而是综合去考虑两个值得变化,采用综合评价指标(F-measure),准确率和召回率的指标有时会出现矛盾的情况,这是我们需要综合的考虑它,最常见的方法就是F-measure(F-Score),F-measure是准确率和召回率的加权调和平均。具体计算为:
当参数α=1时,就是最常见的F1,也就是F1 = 2*P*R/(P+R),代码:F1 = 2*precision*recall/(precision+recall)
详细实现基于用户相似度计算的代码如下,包括计算过程与评价指标:
class UserBasedCF: def __init__(self, train=None, test=None): self.trainfile = train self.testfile = test self.readData() def readData(self, train=None, test=None): self.train_df = train or self.trainfile self.test_df = test or self.testfile self.traindata = {} self.testdata = {} box_id = list(self.train_df['box_id']) film_id = list(self.train_df['llable']) source = list(self.train_df['source']) box_id2 = list(self.test_df['box_id']) film_id2 = list(self.test_df['llable']) source2 = list(self.test_df['source']) for i in range(len(box_id)): userid, itemid, record = box_id[i], film_id[i], source[i] self.traindata.setdefault(userid, {}) self.traindata[userid][itemid] = record print self.traindata for i in range(len(box_id2)): userid, itemid, record = box_id2[i], film_id2[i], source2[i] self.testdata.setdefault(userid, {}) self.testdata[userid][itemid] = record print self.testdata def userSimilarityBest(self, train=None): train = train or self.traindata # self.userSimBest = dict() self.userSimBest = defaultdict(defaultdict) item_users = dict() for u, item in train.items(): for i in item.keys(): item_users.setdefault(i, set()) item_users[i].add(u) user_item_count = dict() count = dict() for item, users in item_users.items(): for u in users: user_item_count.setdefault(u, 0) user_item_count[u] += 1 for v in users: if u == v: continue count.setdefault(u, {}) count[u].setdefault(v, 0) count[u][v] += 1 for u, related_users in count.items(): self.userSimBest.setdefault(u, dict()) for v, cuv in related_users.items(): self.userSimBest[u][v] = cuv / math.sqrt(user_item_count[u] * user_item_count[v] * 1.0) def recommend(self, user, train=None, k=8, nitem=40): train = train or self.traindata rank = dict() interacted_items = train.get(user, {}) for v, wuv in sorted(self.userSimBest[user].items(), key=lambda x: x[1], reverse=True)[0:k]: for i, rvi in train[v].items(): if i in interacted_items: continue rank.setdefault(i, 0) rank[i] += wuv return dict(sorted(rank.items(), key=lambda x: x[1], reverse=True)[0:nitem]) # 准确率、召回率 def recallAndPrecision(self, train=None, test=None, k=8, nitem=10): train = train or self.traindata test = test or self.testdata hit = 0 recall = 0 precision = 0 for user in train.keys(): tu = test.get(user, {}) rank = self.recommend(user, train=train, k=k, nitem=nitem) for item, _ in rank.items(): if item in tu: hit += 1 recall += len(tu) precision += nitem return (hit / (recall * 1.0), hit / (precision * 1.0)) # 覆盖率 def coverage(self, train=None, test=None, k=8, nitem=10): train = train or self.traindata test = test or self.testdata recommend_items = set() all_items = set() for user in train.keys(): for item in train[user].keys(): all_items.add(item) rank = self.recommend(user, train, k=k, nitem=nitem) for item, _ in rank.items(): recommend_items.add(item) return len(recommend_items) / (len(all_items) * 1.0) # 流行度 def popularity(self, train=None, test=None, k=8, nitem=10): train = train or self.traindata test = test or self.testdata item_popularity = dict() for user, items in train.items(): for item in items.keys(): item_popularity.setdefault(item, 0) item_popularity[item] += 1 ret = 0 n = 0 for user in train.keys(): rank = self.recommend(user, train, k=k, nitem=nitem) for item, _ in rank.items(): ret += math.log(1 + item_popularity[item]) n += 1 return ret / (n * 1.0) def testUserBasedCF(): path = 'C:\\...' train_filmname = '...' test_filmname = '...' train_data_df = pd.read_csv(path + train_filmname, sep=',') test_data_df = pd.read_csv(path + test_filmname, sep=',') Train_data = train_data_df Test_data = test_data_df cf = UserBasedCF(Train_data, Test_data) cf.userSimilarityBest() print("%3s%20s%20s%20s%20s" % ('K', "precision", 'recall', 'coverage', 'popularity')) # K个和它兴趣最相似的用户 for k in [5, 10, 20, 40, 80, 160]: recall, precision = cf.recallAndPrecision(k=k) coverage = cf.coverage(k=k) popularity = cf.popularity(k=k) print("%3d%19.3f%%%19.3f%%%19.3f%%%20.3f" % (k, precision * 100, recall * 100, coverage * 100, popularity)) if __name__ == "__main__": testUserBasedCF()