特征工程
俗话说,“巧妇难为无米之炊”,机器学习中,数据和特征便是“米”,模型和算法则是“巧妇”。对于一个机器学习问题,数据和特征往往决定了结果的上限,而模型、算法的选择及优化则是在逐步接近这个上限。
特征工程,顾名思义,是对原始数据进行一系列的工程处理,将其提炼为特征,作为输入供算法和模型使用。
本文主要讨论以下两种常用的数据类型。
(1)结构化数据。结构化数据类型可以看做关系型数据库的一张表,每列都有清晰的定义,包含了数值型和类别型两种基本类型;每一行数据表示一个样本的类型。
(2)非结构化数据。非结构化数据主要包括文本、图像、音频、视频等数据,其中包含的信息无法用一个简单的数值表示,也没有清晰的类别定义,并且每条数据的大小各不相同。
01 特征归一化
为了消除数据特征之间的量纲影响,我们需要对特征进行归一化处理(normalization),使得不同的指标之间具有可比性。
Q1为什么要对数值类型的特征做归一化?
对数值类型的特征做归一化可以将所有的特征都统一到一个大致相同的数值区间内。最常用的方法主要有以下两种:
-
线性函数归一化(Min-Max Scaling)。
它对原始数据进行线性变换,使结果映射到[0,1]的范围,实现对原始数据的等比缩放。归一化公式如下:
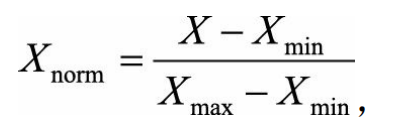
其中X为原始数据,X_max、X_min分别为数据最大值和最小值。 -
零均值归一化(Z-Score Normalization)
它会将原始数据映射到均值为0、标准差为1的分布上。具体来说,假设原始特征的均值为μ、标准差为σ,那么归一化公式定义为:
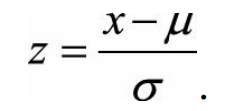
为什么需要对数值型特征做归一化呢? 我们不妨借助随机梯度下降的实例来说明归一化的重要性。假设有两种数值型特征,x_1的取值范围为 [0, 10],x_2的取值范围为[0, 3],于是可以构造一个目标函数符合图1.1(a)中的等值图。
在学习速率相同的情况下,x_1的更新速度会大于x_2,需要较多的迭代才能找到最优解。如果将x_1和x_2归一化到相同的数值区间后,优化目标的等值图会变成图1.1(b)中的圆形,x_1和x_2的更新速度变得更为一致,容易更快地通过梯度下降找到最优解。

数据归一化并不是万能的。 在实际应用中,通过梯度下降法求解的模型通常是需要归一化的,包括线性回归、逻辑回归、支持向量机、神经网络等模型。但对于决策树模型则并不适用,决策树在进行节点分裂时主要依据数据集D关于特征x的信息增益比,而信息增益比跟特征是否经过归一化是无关的,因为归一化并不会改变样本在特征x上的信息增益。