3D Segmentation with Exponential Logarithmic Loss for Highly Unbalanced Object Sizes
随着完全卷积神经网络的引入,深度学习提高了医学图像分割的速度和准确度的基准,并且已经提出了用于2D和3D分割的不同网络,并且具有有希望的结果。然而,大多数网络仅处理相对较少数量的标签(<10),并且在处理高度不平衡的对象尺寸方面的工作非常有限,尤其是在3D分割中。在本文中,我们提出了一种网络架构和相应的损失函数,它们可以改善非常小的结构的分割。通过结合跳过连接和深度监督三维分割的计算可行性,我们提出了一种快速收敛和计算有效的网络架构,以实现精确分割。此外,受焦点损失概念的启发,我们提出了一种指数对数损失,它不仅通过它们的相对大小而且通过它们的分割困难来平衡标记。我们使用20个标签对大脑分割实现平均Dice系数为82%,最小对象大小与最大对象大小的比率为0.14%。要达到这样的精确度,需要不到100个时期,而分割128×128×128的音量只需要大约0.4秒。
随着完全卷积神经网络(CNN)的引入,深度学习提高了医学图像分割速度和准确度的基准[7]。提出了不同的2D [5,8]和3D [1,2,6,10]网络,以从医学图像中分割出各种解剖结构,例如心脏,脑,肝脏和前列腺。无论这些网络的有希望的结果如何,3D CNN图像分割仍然具有挑战性。大多数网络应用于具有少量标签(<10)的数据集,尤其是在3D分割中。当需要更详细的分割以及更多的解剖结构时,需要通过新的网络架构和算法来解决先前未见过的问题,例如计算可行性和高度不平衡的对象大小。
对于高度不平衡的标签,只提出了一些框架。在[8]中,提出了2D网络架构来分割3D脑容积的所有切片。引入了错误校正增强来计算标签权重,强调对具有较低验证准确性的类的参数更新。尽管结果很有希望,但标签权重仅应用于加权交叉熵但不应用于骰子损失,并且用于3D分割的2D结果的堆叠可能导致连续切片之间的不一致。
在[9]中,广义骰子损失被用作损失函数。 不是计算每个标签的Dice损失,而是针对广义Dice损失计算产品在地面实况和预测概率之和之间的加权和上的加权和,其中权重与标签频率成反比。 实际上,Dice系数对于小结构是不利的,因为误分类的一些像素可能导致系数的大幅减小,并且这种灵敏度与结构之间的相对尺寸无关。 因此,通过标签频率进行平衡对于Dice损失是非最优的。
为了解决三维分割中高度不平衡的物体尺寸和计算效率的问题,我们在本文中有两个关键的贡献。 (I)我们提出指数对数损失函数。在[4]中,为了处理两类图像分类问题的高度不平衡的数据集,仅通过网络输出的softmax概率计算的调制因子乘以加权的交叉熵以关注不太准确的类。受这种平衡分类困难的概念的启发,我们提出了一种包含对数Dice损失的损失函数,其本质上更侧重于不太精确的分段结构。对数Dice损失和加权交叉熵的非线性可以通过所提出的指数参数进一步控制。以这种方式,网络可以在小型和大型结构上实现精确分割。 (II)我们提出了一种快速收敛和计算效率高的网络架构,它结合了跳过连接和深度监控的优点,它只有V-Net的1/14,并且速度是V-Net的两倍[6]。 。在具有20个高度不平衡标签的脑磁共振(MR)图像上进行实验。结合这两项创新,平均分割系数达到82%,平均分割时间为0.4秒。
2 Methodology
2.1 Proposed Network Architecture
3D分割网络比2D网络需要更多的计算资源。因此,我们提出了一种网络架构,旨在针对有限的资源进行精确分割和快速收敛(图1)。与大多数分段网络类似,我们的网络包括编码和解码路径。该网络由卷积块组成,每个卷积块包括与批量归一化(BN)和整流线性单元(ReLU)相关联的n个通道的k级联3×3×3卷积层。为了更好地收敛,在每个块中使用具有1×1×1卷积层的跳过连接。我们将两个分支添加在一起以减少内存消耗,而不是连接,因此该块允许有效的多规模处理,并且可以训练更深的网络。每次最大池化后,通道数(n)加倍,每次上采样后减半。更多层(k)与较小尺寸的张量一起使用,以便在可行的存储器使用的情况下可以学习更抽象的知识。来自编码路径的特征信道与解码路径中的相应张量连接,以便更好地收敛。我们还包括高斯噪声层和丢失层,以避免过度拟合。
与[5]类似,我们利用深度监督,允许更直接的反向传播到隐藏层,以实现更快的收敛和更高的准确性[3]。 虽然深度监督可以显着提高收敛性,但在3D网络中尤其是内存昂贵。 因此,我们省略了具有最多通道的块的张量(块(192,3)),以便可以在具有12GB内存的GPU上执行训练。 具有softmax函数的1×1×1卷积的最后一层提供分割概率。

2.2指数对数损失
我们提出了一种损失函数,可以改善小结构的分割:
![]()
用w Dice和w交叉指数对数Dice损失(LDice)和加权指数交叉熵(LCross)的各自权重:
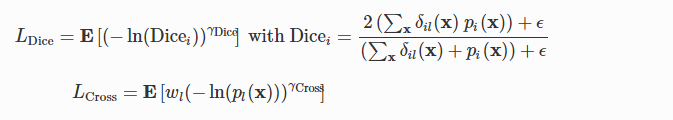
用x表示像素位置和标签。 l是x的地面实况标签。 E [∙]分别是LDice和LCross中关于i和x的平均值。 δil(x)是Kronecker delta,当i = 1时为1,否则为0。 pi(x)是softmax概率,其在计算Dicei时充当标签i所拥有的像素x的部分。 ε= 1是用于处理训练样本中缺失标签的加法平滑的伪计数。 wl =((Σkfk)/ fl)0.5,标签k的频率为fk,是用于减少更常见标签影响的标签重量。 γDice和γCross进一步控制损失函数的非线性,为简单起见,我们在这里使用γDice=γCross=γ。
在[6]中提出了在CNN中使用骰子损失。 Dice系数不利于小结构,因为对几个像素进行错误分类会导致系数大幅下降。标签权重的使用不能减轻这种敏感性,因为它与相对对象大小无关,并且Dice系数已经是标准化度量。因此,我们使用对数骰子损失而不是尺寸差异,而骰子损失更多地集中在不太准确的标签上。图2显示了线性(E [1-Dicei])和对数Dice损失之间的比较。
我们通过引入指数γDice和γCross来进一步控制损耗的非线性。在[4]中,调制因子(1-pl)γ乘以加权交叉熵,变为wl(1-pl)γ(-ln(pl)),用于两类图像分类。除了使用标签权重wl平衡标签频率之外,该焦点损失还在易于和硬的样本之间平衡。我们的指数损失实现了类似的目标。当γ> 1时,损失更多地集中在比对数损失更不准确的标签上(图2)。虽然焦点损失适用于[4]中的两类图像分类,但是当应用于具有20个标签的分割问题时,我们得到了更差的结果。这可能是由于标签精度变高时过度抑制损耗功能引起的。相反,我们可以在0 <γ<1时获得更好的结果。图2显示当γ= 0.3时,在x = 0.5附近存在拐点,其中x可以是Dicei或pl(x)。对于x <0.5,该损失表现类似于γ≥1时的损耗,随着x增加,梯度幅度减小。随着梯度幅度的增加,这种趋势在x> 0.5时反转。因此,这种损失促进了低预测精度和高预测精度的改进。这个特征是使用所提出的指数形式而不是[4]中的指数形式的原因。

2.3培训策略
图像增强用于学习不变特征并避免过度拟合。 由于实际的非刚性变形难以实现且计算成本昂贵,因此我们将增强限制为刚性变换,包括旋转(轴向,±30∘),偏移(±20%)和缩放([0.8,1.2])。 每个图像有80%的机会在训练中被转换,因此增强图像的数量与时期的数量成比例。 优化器Adam与Nesterov动量一起用于快速收敛,学习率为10 -3,批量大小为1,并且100个时期。 使用具有12 GB内存的TITAN X GPU。
3实验
3.1数据和实验设置
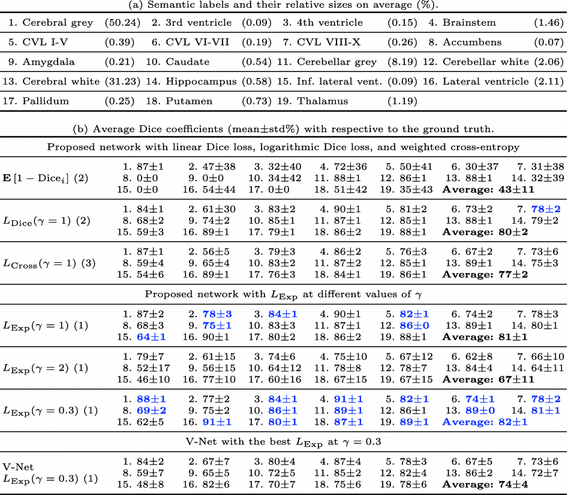
来自不同患者的43个3D脑MR图像的数据集被神经解剖学标记以提供训练和验证样品。图像由T1加权的MP-RAGE脉冲序列产生,其提供高组织对比度。它们由训练有素的专家手动分割,结果由咨询神经解剖学家审查。每个分割具有19个脑结构的语义标签,因此包括20个具有背景的标签(表1(a))。由于存在各种图像尺寸(128至337)和间距(0.9至1.5mm),每个图像使用最小间距重新采样为各向同性间距,在短边上填充零,并调整为128×128×128。
表1(a)显示标签高度不平衡。背景平均占据了图像的93.5%。在没有背景的情况下,最小和最大结构的相对尺寸分别为0.07%和50.24%,因此比率为0.14%。
我们使用所提出的网络研究了六种损失函数,并将最好的一种应用于V-Net架构[6],因此总共研究了七种情况。对于LExp,我们设置wDice = 0.8和wCross = 0.2,因为它们提供了最好的结果。通过改组和拆分数据集生成五组数据,其中70%用于培训,30%用于每组验证。对于每个研究的案例,对所有五组数据进行了实验,以获得更具统计学意义的结果。针对每个验证图像计算实际Dice系数,而不是(2)中的Dicei。在所有实验中使用相同的设置和训练策略。
表格1。
语义脑分割。 (a)语义标签及其相对大小(%),没有背景。 CVL代表小脑的小叶。 背景平均占据了图像的93.5%。 (b)从五次实验中平均预测和地面实况之间的骰子系数(格式:平均值±标准%)。 最佳结果以蓝色突出显示。 对于所有LExp,wDice = 0.8并且wCross = 0.2。
3.2结果与讨论
表1(b)显示了五次实验的平均Dice系数。线性骰子损失(E [1-Dicei])具有最差的性能。它在灰色和白色等相对较大的结构上表现良好,但性能随着结构尺寸的减小而降低。在所有实验中都遗漏了非常小的结构,例如伏隔核和扁桃体。相反,对数Dice损失(LDice(γ= 1))提供了更好的结果,尽管标签2的大标准偏差表明存在未命中。我们还进行了加权交叉熵(LCross(γ= 1))的实验,其性能优于线性Dice损失但差于对数Dice损失。对数Dice损失和加权交叉熵(LExp(γ= 1))的加权和优于单个损失,并且在测试案例中提供了第二好的结果。正如在Sect。中所讨论的。 2.2,LExp(γ= 2)即使在较大的结构上也是无效的。这与我们在图2中的观察结果一致,即当精度越来越高时,损失函数被过度抑制。相反,LExp(γ= 0.3)给出了最好的结果。虽然在平均值方面仅略好于LExp(γ= 1),但较小的标准偏差表明它也更精确。

图4。
可视化的一个例子。 上图:轴向视图。 底部:隐藏的脑灰色,脑白色和小脑灰色的3D视图,以便更好地说明。
当将最佳损失函数应用于V-Net时,其性能仅优于线性Dice损失和LExp(γ= 2)。这表明我们提出的网络架构在这个问题上比V-Net表现得更好。
图3显示了验证Dice系数与时间的关系,平均来自五个实验。我们显示Dice系数,而不是损失,因为它们的大小在各个案例中是一致的。与表1(b)类似,对数Dice损失,LExp(γ= 1)和LExp(γ= 0.3)具有良好的收敛性和性能,LExp(γ= 0.3)表现稍好。这三个案例聚集在大约80个时代。加权交叉熵和LExp(γ= 2)更加波动。线性骰子损失也在约80个时期收敛,但Dice系数小得多。使用LExp(γ= 0.3)比较V-Net和建议的网络,V-Net的收敛性更差,特别是在早期时期。这表明所提出的网络具有更好的收敛性。
图4显示了一个示例的可视化。有两个明显的观察结果。首先,与表1(b)一致,线性骰子损失错过了一些小结构,例如伏隔核和扁桃体,尽管它在大型结构上表现良好。其次,V-Net的分割偏离了实际情况。对数Dice损失,LExp(γ= 1)和LExp(γ= 0.3)具有最佳分割和平均Dice系数。加权交叉熵具有与LExp(γ= 2)相同的平均Dice系数,尽管加权交叉熵过分割一些结构如脑干和LExp(γ= 2)具有噪声分割。
比较拟议网络和V-Net之间的效率,建议的网络有大约500万个参数,而V-Net有大约7100万个参数,相差14倍。此外,建议的网络平均仅花费约0.4秒来分割128×128×128的体积,而V-Net花费约0.9秒。因此,建议的网络更有效。
4。结论
在本文中,我们提出了一种针对三维图像分割优化的网络架构,以及一种用于分割非常小的结构的损失函数。 所提出的网络架构仅具有大约1/14的参数,并且是V-Net的两倍。 对于损失函数,对数Dice损失优于线性Dice损失,并且对数Dice损失和加权交叉熵的加权和优于单个损失。 通过引入指数形式,可以进一步控制损失函数的非线性,以提高分割的准确性和精度。