spark Web UI是学习调试spark任务的入口,查看spark UI任务日志也是一项必备技能。但在几番搜索后,一直没能找到全面详细地对如何查看spark Web UI方法的文章,故在查看资料及个人理解的基础上整理了本篇文章,欢迎大家一起交流学习!
下面对spark Web UI的各tab页分别进行介绍:
1. Jobs
在提交spark任务运行后,日志中会输出tracking URL即任务的日志链接。在浏览器中打开tracking URL后,默认进入Jobs页。Jobs展示的是整个spark应用任务的job整体信息:
User: spark任务提交的用户,用以进行权限控制与资源分配。
Total Uptime: spark application总的运行时间,从appmaster开始运行到结束的整体时间。
Scheduling Mode: application中task任务的调度策略,由参数spark.scheduler.mode来设置,可选的参数有FAIR和FIFO,默认是FIFO。这与yarn的资源调度策略的层级不同,yarn的资源调度是针对集群中不同application间的,而spark scheduler mode则是针对application内部task set级别的资源分配,不同FAIR策略的参数配置方式与yarn中FAIR策略的配置方式相同。
Completed Jobs: 已完成Job的基本信息,如想查看某一个Job的详细情况,可点击对应Job进行查看。
Active Jobs: 正在运行的Job的基本信息。
Event Timeline: 在application应用运行期间,Job和Exector的增加和删除事件进行图形化的展现。这个就是用来表示调度job何时启动何时结束,以及Excutor何时加入何时移除。我们可以很方便看到哪些job已经运行完成,使用了多少Excutor,哪些正在运行。
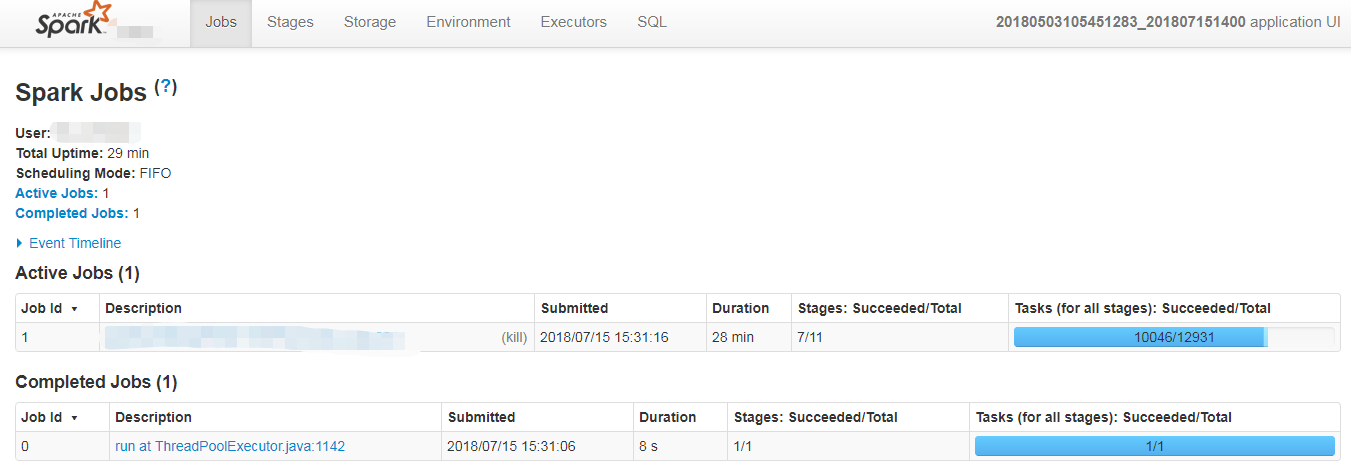
Job默认都是串行提交运行的,如果Job间没有依赖,可以使用多线程并行提交Job,实现Job并发。
2. Jobs Detail
在Jobs页面点击进入某个Job之后,可以查看某一Job的详细信息:
Staus: 展示Job的当前状态信息。
Active Stages: 正在运行的stages信息,点击某个stage可进入查看具体的stage信息。
Pending Stages: 排队的stages信息,根据解析的DAG图stage可并发提交运行,而有依赖的stage未运行完时则处于等待队列中。
Completed Stages: 已经完成的stages信息。
Event Timeline: 展示当前Job运行期间stage的提交与结束、Executor的加入与退出等事件信息。
DAG Visualization: 当前Job所包含的所有stage信息(stage中包含的明细的tranformation操作),以及各stage间的DAG依赖图。DAG也是一种调度模型,在spark的作业调度中,有很多作业存在依赖关系,所以没有依赖关系的作业可以并行执行,有依赖的作业不能并行执行。
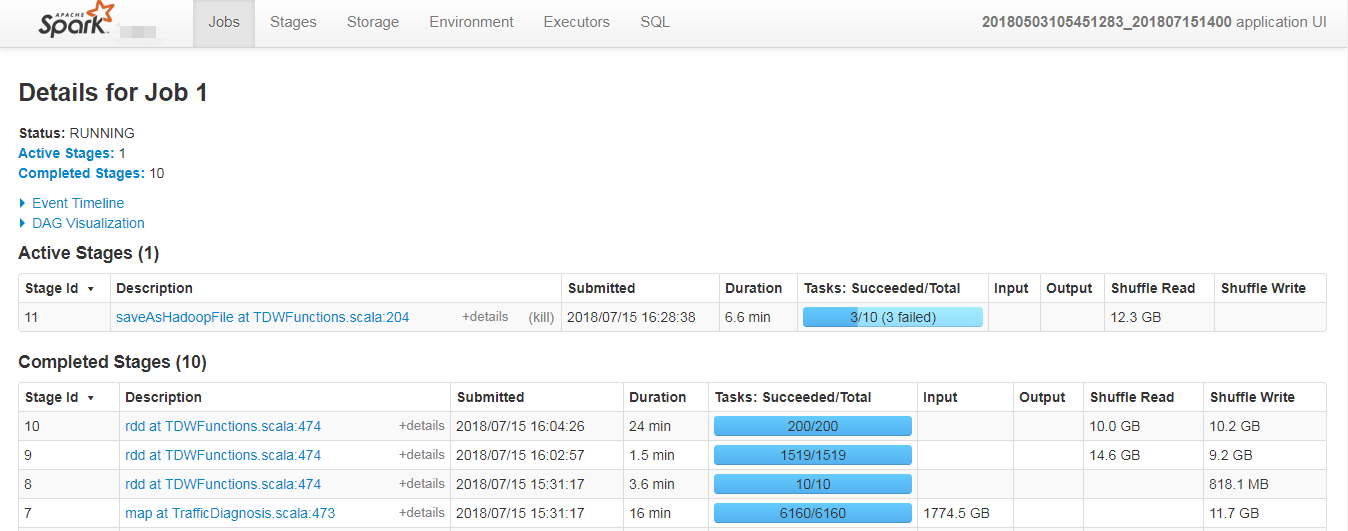
3. Stages
在Job Detail页点击进入某个stage后,可以查看某一stage的详细信息:
Total time across all tasks: 当前stage中所有task花费的时间和。
Locality Level Summary: 不同本地化级别下的任务数,本地化级别是指数据与计算间的关系(PROCESS_LOCAL进程本地化:task与计算的数据在同一个Executor中。NODE_LOCAL节点本地化:情况一:task要计算的数据是在同一个Worker的不同Executor进程中;情况二:task要计算的数据是在同一个Worker的磁盘上,或在 HDFS 上,恰好有 block 在同一个节点上。RACK_LOCAL机架本地化,数据在同一机架的不同节点上:情况一:task计算的数据在Worker2的Executor中;情况二:task计算的数据在Worker2的磁盘上。ANY跨机架,数据在非同一机架的网络上,速度最慢)。
Input Size/Records: 输入的数据字节数大小/记录条数。
Shuffle Write: 为下一个依赖的stage提供输入数据,shuffle过程中通过网络传输的数据字节数/记录条数。应该尽量减少shuffle的数据量及其操作次数,这是spark任务优化的一条基本原则。
DAG Visualization: 当前stage中包含的详细的tranformation操作流程图。
Metrics: 当前stage中所有task的一些指标(每一指标项鼠标移动上去后会有对应解释信息)统计信息。
Event Timeline: 清楚地展示在每个Executor上各个task的各个阶段的时间统计信息,可以清楚地看到task任务时间是否有明显倾斜,以及倾斜的时间主要是属于哪个阶段,从而有针对性的进行优化。
Aggregated Metrics by Executor: 将task运行的指标信息按excutor做聚合后的统计信息,并可查看某个Excutor上任务运行的日志信息。
Tasks: 当前stage中所有任务运行的明细信息,是与Event Timeline中的信息对应的文字展示(可以点击某个task查看具体的任务日志)。
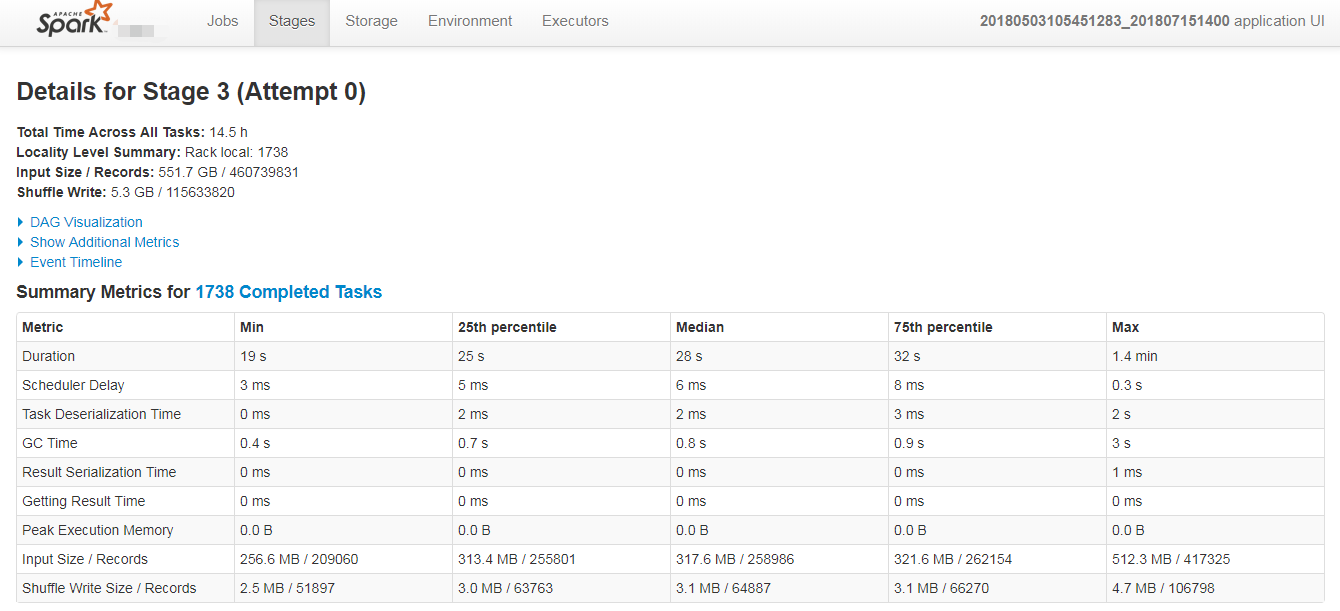
4. Storage
storage页面能看出application当前使用的缓存情况,可以看到有哪些RDD被缓存了,以及占用的内存资源。如果job在执行时持久化(persist)/缓存(cache)了一个RDD,那么RDD的信息可以在这个选项卡中查看。
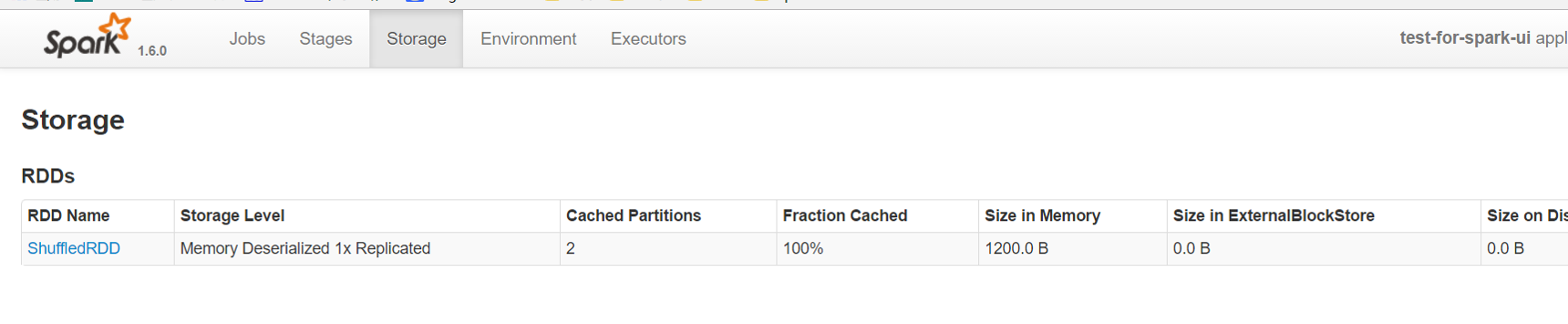
5. Storage Detail
点击某个RDD即可查看该RDD缓存的详细信息,包括缓存在哪个Executor中,使用的block情况,RDD上分区(partitions)的信息以及存储RDD的主机的地址。

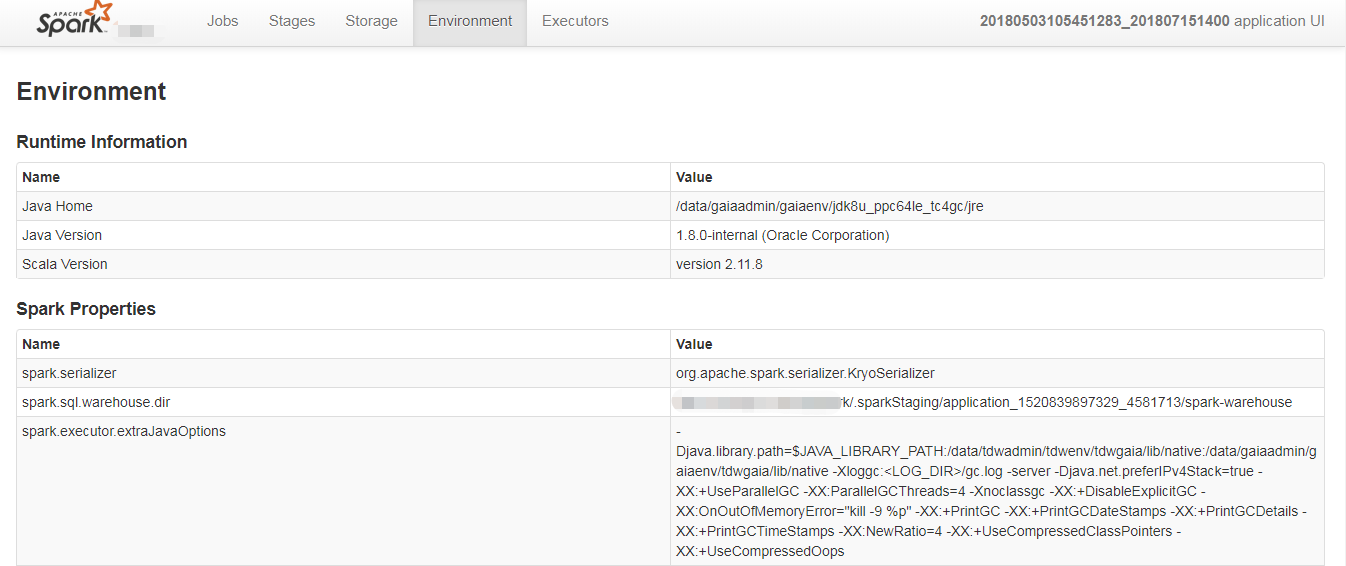
6. Enviroment
Environment选项卡提供有关Spark应用程序(或SparkContext)中使用的各种属性和环境变量的信息。用户可以通过这个选项卡得到非常有用的各种Spark属性信息,而不用去翻找属性配置文件。
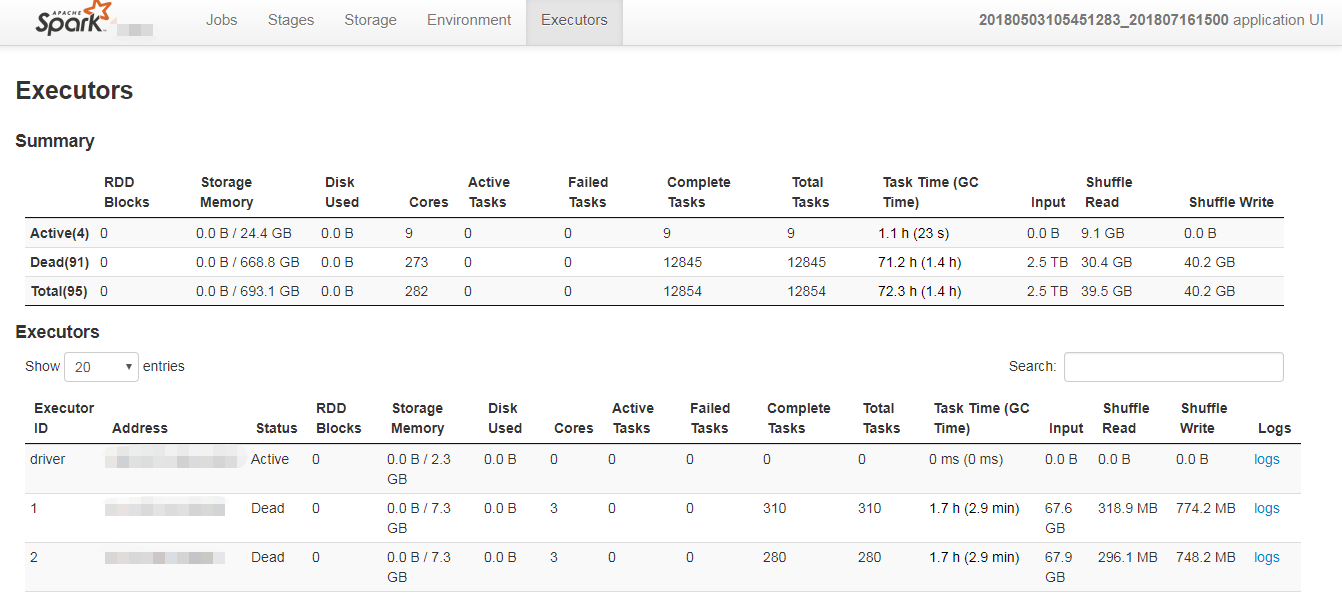
7. Executor
Executors选项卡提供了关于内存、CPU核和其他被Executors使用的资源的信息。这些信息在Executor级别和汇总级别都可以获取到。一方面通过它可以看出来每个excutor是否发生了数据倾斜,另一方面可以具体分析目前的应用是否产生了大量的shuffle,是否可以通过数据的本地性或者减小数据的传输来减少shuffle的数据量。
Summary: 该application运行过程中使用Executor的统计信息。
Executors: 每个Excutor的详细信息(包含driver),可以点击查看某个Executor中任务运行的详细日志。
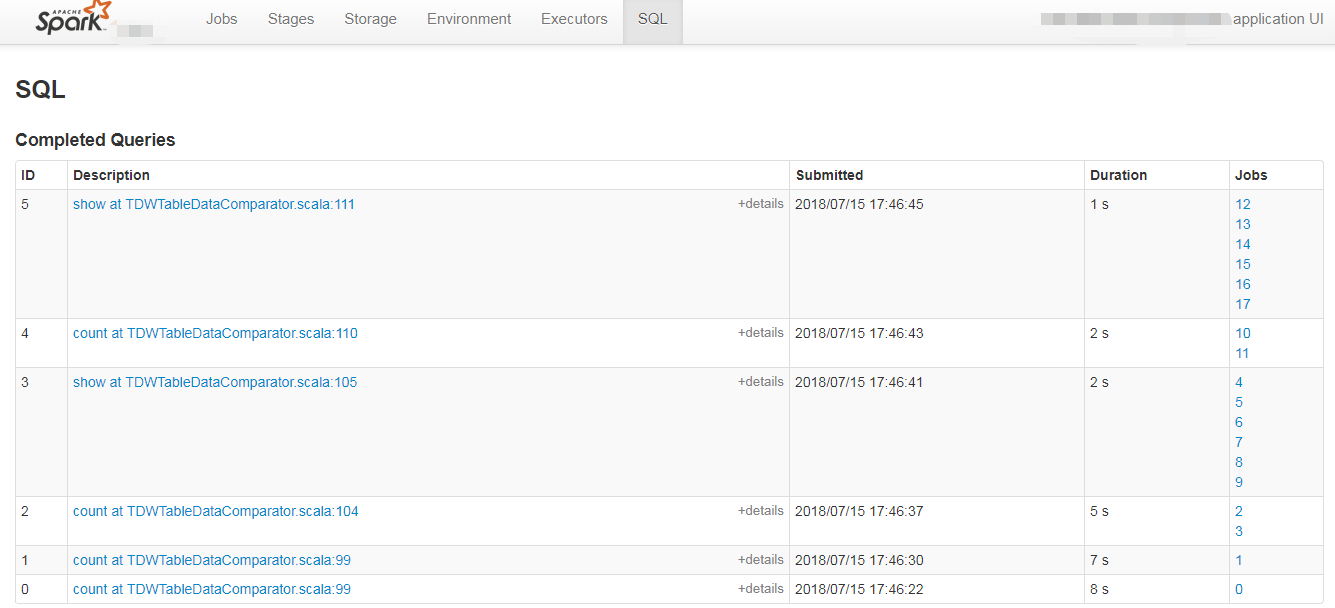
8. SQL
SQL选项卡(只有执行了spark SQL查询才会有SQL选项卡)可以查看SQL执行计划的细节,它提供了SQL查询的DAG以及显示Spark如何优化已执行的SQL查询的查询计划。
参考文章:
https://www.csdn.net/article/2015-07-08/2825162
https://blog.csdn.net/minge_se/article/details/79146737
原文:https://blog.csdn.net/qq_27639777/article/details/81069893