一、MemCached概念
Memcached是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。Memcached基于一个存储键/值对的hashmap。其守护进程(daemon )是用C写的,但是客户端可以用任何语言来编写,并通过memcached协议与守护进程通信
一、缓存概述
1、分类
本地缓存(HashMap/ConcurrentHashMap、Ehcache、Guava Cache等),缓存服务(Redis/Tair/Memcache等)。
2、使用场景
什么情况适合用缓存?考虑以下两种场景:
- 短时间内相同数据重复查询多次且数据更新不频繁,这个时候可以选择先从缓存查询,查询不到再从数据库加载并回设到缓存的方式。此种场景较适合用单机缓存。
- 高并发查询热点数据,后端数据库不堪重负,可以用缓存来扛。
3、选型考虑
- 如果数据量小,并且不会频繁地增长又清空(这会导致频繁地垃圾回收),那么可以选择本地缓存。具体的话,如果需要一些策略的支持(比如缓存满的逐出策略),可以考虑Ehcache;如不需要,可以考虑HashMap;如需要考虑多线程并发的场景,可以考虑ConcurentHashMap。
- 其他情况,可以考虑缓存服务。目前从资源的投入度、可运维性、是否能动态扩容以及配套设施来考虑,我们优先考虑Tair。除非目前Tair还不能支持的场合(比如分布式锁、Hash类型的value),我们考虑用Redis。
二、Memcached 的使用
1.什么是Memcached
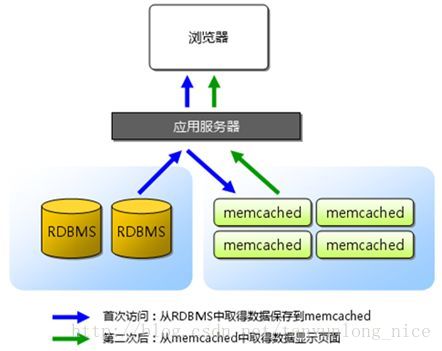
许多Web应用程序都将数据保存到RDBMS中,应用服务器从中读取数据并在浏览器中显示。但随着数据量的增大,访问的集中,就会出现REBMS的负担加重,数据库响应恶化,网站显示延迟等重大影响。Memcached是高性能的分布式内存缓存服务器。一般的使用目的是通过缓存数据库查询结果,减少数据库的访问次数,以提高动态Web应用的速度、提高扩展性。如图:

2. Memcached的特点
Memcached作为高速运行的分布式缓存服务器具有以下特点。
- 协议简单:memcached的服务器客户端通信并不使用复杂的MXL等格式,而是使用简单的基于文本的协议。
- 基于libevent的事件处理:libevent是个程序库,他将Linux的epoll、BSD类操作系统的kqueue等时间处理功能封装成统一的接口。memcached使用这个libevent库,因此能在Linux、BSD、Solaris等操作系统上发挥其高性能。
- 内置内存存储方式:为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。由于数据仅存在于内存中,因此重启memcached,重启操作系统会导致全部数据消失。另外,内容容量达到指定的值之后memcached回自动删除不适用的缓存。
- Memcached不互通信的分布式:memcached尽管是“分布式”缓存服务器,但服务器端并没有分布式功能。各个memcached不会互相通信以共享信息。他的分布式主要是通过客户端实现的
3.Memcached的内存管理
最近的memcached默认情况下采用了名为SlabAllocatoion的机制分配,管理内存。在改机制出现以前,内存的分配是通过对所
有记录简单地进行malloc和free来进行的。但是这中方式会导致内存碎片,加重操作系统内存管理器的负担。
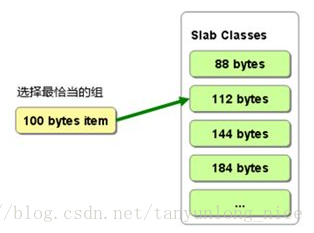
Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,已完全解决内存碎片问题。SlabAllocation 的原理相当简单。将分配的内存分割成各种尺寸的块(chucnk),并把尺寸相同的块分成组(chucnk的集合)如图:

而且slab allocator 还有重复使用已分配内存的目的。也就是说,分配到的内存不会释放,而是重复利用。
Slab Allocation 的主要术语
- Page:分配给Slab 的内存空间,默认是1MB。分配给Slab 之后根据slab 的大小切分成chunk.
- Chunk :用于缓存记录的内存空间。
- SlabClass:特定大小的chunk 的组。
在Slab 中缓存记录的原理
Memcached根据收到的数据的大小,选择最合适数据大小的Slab,memcached中保存着slab内空闲chunk的列表,根据该列表选择chunk,然后将数据缓存于其中。
Memcached在数据删除方面有效里利用资源
Memcached删除数据时数据不会真正从memcached中消失。Memcached不会释放已分配的内存。记录超时后,客户端就无法再看见该记录(invisible透明),其存储空间即可重复使用。
LazyExpriationmemcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过期。这种技术称为lazyexpiration.因此memcached不会再过期监视上耗费CPU时间。
对于缓存存储容量满的情况下的删除需要考虑多种机制,一方面是按队列机制,一方面应该对应缓存对象本身的优先级,根据缓存对象的优先级进行对象的删除。
LRU:从缓存中有效删除数据的原理
Memcached会优先使用已超时的记录空间,但即使如此,也会发生追加新纪录时空间不足的情况。此时就要使用名为LeastRecently Used(LRU)机制来分配空间。这就是删除最少使用的记录的机制。因此当memcached的内存空间不足时(无法从slabclass)获取到新空间时,就从最近未使用的记录中搜索,并将空间分配给新的记录。
3.Spirng整合Memcached
memcached和spring集成(主要说spring和memcached的集成,spring本身的东东就不多说啦),这里主要是实现底层Spirng的Cache接口,思路如图:
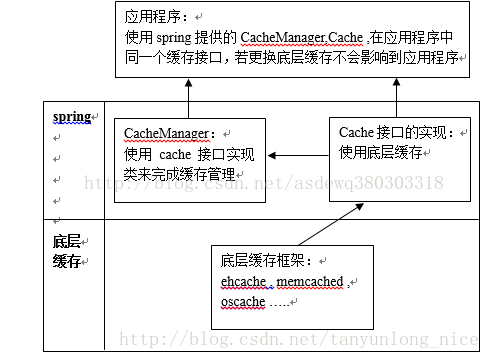
在以上思路基础上,我们结合具体业务逻辑和程序扩展性,封装改造了一下具体实现,由原有的KEY,VALUE形式下,增加了变成两个Key,提高缓存命中率
二、MemCached的安装
1、下载MemCached软件
2、将memcached.exe文件拷贝到应用目录下,注意目录不能出现中文和空格等特殊字符
3、在memcached.exe所在目录下,打开cmd终端(注意:需要以admin的身份来打开)
memcached.exe -d install 安装
memcached.exe -d uninstall 卸载
4、启动memcached
Memcached.exe -d start
使用netstat -an命令查看是否启动成功,如果查看到11211端口在监听,说明启动ok,如果启动不成功,可以使用memcached.exe -p 端口号 的方式来启动,这种方式是以shell的方式来启动的,启动之后,窗口不能关闭,一旦窗口关闭,程序也就终止了。
三、操作MemCached
1、使用telnet操作
1.1 登录telnet,连接memcached服务
telnet 127.0.0.1 11211
1.2 添加
基本语法:
add key 0(压缩标志位) 缓存时间(秒) 数据大小(字符)
举例:
add name 0 30 6
chhliu
返回STORED说明添加成功
1.3 获取
举例:
get name
返回VALUE name 0 6
chhliu
END
则说明成功
隔30s后再获取,会返回END,说明缓存过期

1.4修改
set key 0 存放时间 数据大小
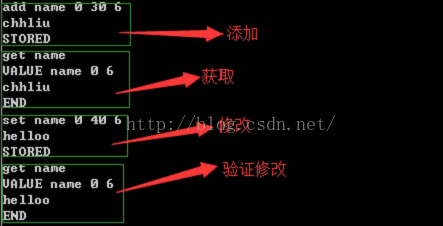
replace key 0 存放时间 数据大小

1.5 删除
基本语法:
delete key

2、使用Java操作
2.1 新建一个maven项目,并加入依赖的jar包,pom文件如下:
- <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
- <modelVersion>4.0.0</modelVersion>
- <groupId>com.chhliu.myself</groupId>
- <artifactId>memcached</artifactId>
- <version>0.0.1-SNAPSHOT</version>
- <packaging>jar</packaging>
- <name>memcached</name>
- <url>http://maven.apache.org</url>
- <properties>
- <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
- </properties>
- <dependencies>
- <dependency>
- <groupId>junit</groupId>
- <artifactId>junit</artifactId>
- <version>4.8.1</version>
- <scope>test</scope>
- </dependency>
- <dependency>
- <groupId>org.apache.common</groupId>
- <artifactId>pool</artifactId>
- <version>1.5.6</version>
- <scope>system</scope>
- <systemPath>${basedir}/lib/commons-pool-1.5.6.jar</systemPath>
- </dependency>
- <dependency>
- <groupId>org.apache</groupId>
- <artifactId>slf4j-api</artifactId>
- <version>1.6.1</version>
- <scope>system</scope>
- <systemPath>${basedir}/lib/slf4j-api-1.6.1.jar</systemPath>
- </dependency>
- <dependency>
- <groupId>org.apache</groupId>
- <artifactId>slf4j-simple</artifactId>
- <version>1.6.1</version>
- <scope>system</scope>
- <systemPath>${basedir}/lib/slf4j-simple-1.6.1.jar</systemPath>
- </dependency>
- <dependency>
- <groupId>org.apache</groupId>
- <artifactId>java_memcached-release</artifactId>
- <version>2.6.6</version>
- <scope>system</scope>
- <systemPath>${basedir}/lib/java_memcached-release_2.6.6.jar</systemPath>
- </dependency>
- </dependencies>
- </project>
- public class MyDefCache {
- public static void main(String[] args) {
- MemCachedClient client = new MemCachedClient();
- String[] addr = { "127.0.0.1:11211", "127.0.0.1:11212", "127.0.0.1:11213" };
- Integer[] weights = { 3, 3, 3 };
- SockIOPool pool = SockIOPool.getInstance();
- pool.setServers(addr);
- pool.setWeights(weights);
- pool.setInitConn(5);
- pool.setMinConn(5);
- pool.setMaxConn(200);
- pool.setMaxIdle(1000 * 30 * 30);
- pool.setMaintSleep(30);
- pool.setNagle(false);
- pool.setSocketTO(30);
- pool.setSocketConnectTO(0);
- pool.initialize();
- // 将数据放入缓存
- client.set("name", "chhliu");
- // 将数据放入缓存,并设置失效时间
- client.set("company", "tencent", 60);
- // 获取缓存数据
- String name = (String) client.get("name");
- String company = (String) client.get("company");
- System.out.println("name:"+name+" company:"+company);
- // 删除缓存数据
- // client.delete("company");
- // 获取缓存数据
- // company = (String) client.get("company");
- // System.out.println("after delete company:"+company);
- }
- }
- 以上代码中涉及到的API,在后面统一说明。
运行结果如下:
name:chhliu company:tencent
我们再通过前面的方式来看下这2条数据是怎么分布的,
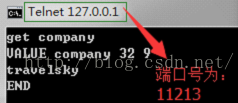
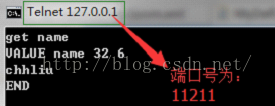
通过从远程查看服务器上的值,说明memcached已经实现了分布式的缓存,那么memcached是怎么来实现分布式缓存的了,下面我们来了解下:
1、Memcached是基于C/S的架构实现的
2、MemCached是基于客户端来实现分布式的,Server端不支持分布式缓存
3、动态建立连接,每次操作MemCached服务端的时候,通过客户端动态建立连接,例如name:chhliu添加的时候是添加到127.0.0.1:11211服务端,当我们需要获取的时候,客户端会只连接127.0.0.1:11211服务器,而不是同时连了上面3个服务器。也就是说MemCached客户端每次只保证一个连接。
4、散列算法,可以根据权重来动态计算缓存数据的分布,数据缓存更均匀,合理。
四、由Memcached分布式思想,设计分布式数据库
以下是我在使用MemCached的过程中的一些感悟和理解,其实MemCached实现分布式的思想很优秀,在很多需要分布式的地方都很实用。以下是用这种思想,实现的一个分布式数据库系统。
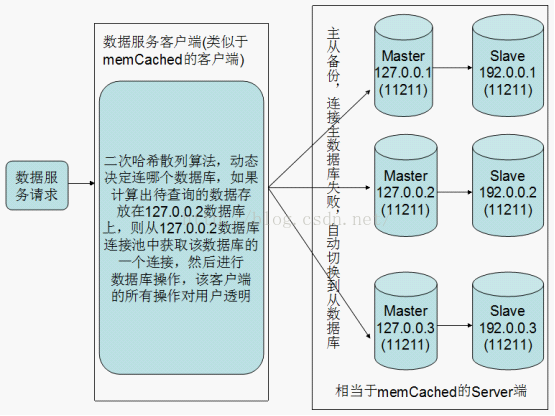
上图是一个整体的架构,主要是运用了Memcached分布式的实现思想,这种架构下的分布式数据库结构有如下优点:
1、实现分布式的数据库操作:各主数据库之间无须互相通信同步数据,节约带宽,主从之间通信,备份数据。
2、提供高可用性:主从结构,无缝切换。
3、C/S架构,直接通过客户端来实现Server端的分布式操作。
4、实现了数据库服务和业务程序的分离,当业务程序不可用或者是业务服务器宕机的时候,对数据库服务无任何影响。
5、动态的多节点负载均衡。
6、客户端保证每次只连接一个主数据库服务端,并不是同时建立多个连接,也就是说在真正需要建立连接的时候才会建立一个连接,减少维护连接的开销。
7、可扩展性好,横向扩展简单方便,只需要将主从Server端中的主数据库在客户端注册即可。
8、集群中性能好,每个集群中的节点类似于单节点下的主从备份结构。
六、Memcached Java Client API详解
1、SockIOPool
这个类用来创建管理客户端和服务器通讯连接池,客户端主要的工作包括数据通讯、服务器定位、hash码生成等都是由这个类完成的。
· public static SockIOPool getInstance()
· 获得连接池的单态方法。这个方法有一个重载方法getInstance( String poolName ),每个poolName只构造一个SockIOPool实例。缺省构造的poolName是default。
· 如果在客户端配置多个memcached服务,一定要显式声明poolName。
· public void setServers( String[] servers )
· 设置连接池可用的cache服务器列表,server的构成形式是IP:PORT(如:127.0.0.1:11211)
· public void setWeights( Integer[] weights )
· 设置连接池可用cache服务器的权重,和server数组的位置一一对应
· 其实现方法是通过根据每个权重在连接池的bucket中放置同样数目的server(如下代码所示),因此所有权重的最大公约数应该是1,不然会引起bucket资源的浪费
· public void setInitConn( int initConn )
· 设置开始时每个cache服务器的可用连接数
· public void setMinConn( int minConn )
· 设置每个服务器最少可用连接数
· public void setMaxConn( int maxConn )
· 设置每个服务器最大可用连接数
· public void setMaxIdle( long maxIdle )
· 设置可用连接池的最长等待时间
· public void setMaintSleep( long maintSleep )
· 设置连接池维护线程的睡眠时间
· 设置为0,维护线程不启动
· 维护线程主要通过log输出socket的运行状况,监测连接数目及空闲等待时间等参数以控制连接创建和关闭。
· public void setNagle( boolean nagle )
· 设置是否使用Nagle算法,因为我们的通讯数据量通常都比较大(相对TCP控制数据)而且要求响应及时,因此该值需要设置为false(默认是true)
· ublic void setSocketTO( int socketTO )
· 设置socket的读取等待超时值
· public void setSocketConnectTO( int socketConnectTO )
· 设置socket的连接等待超时值
· public void setAliveCheck( boolean aliveCheck )
· 设置连接心跳监测开关。
· 设为true则每次通信都要进行连接是否有效的监测,造成通信次数倍增,加大网络负载,因此该参数应该在对HA要求比较高的场合设为TRUE,默认状态是false。
· public void setFailback( boolean failback )
· 设置连接失败恢复开关
· 设置为TRUE,当宕机的服务器启动或中断的网络连接后,这个socket连接还可继续使用,否则将不再使用,默认状态是true,建议保持默认。
· public void setFailover( boolean failover )
· 设置容错开关
· 设置为TRUE,当当前socket不可用时,程序会自动查找可用连接并返回,否则返回NULL,默认状态是true,建议保持默认。
· public void setHashingAlg( int alg )
· 设置hash算法
· alg=0 使用String.hashCode()获得hash code,该方法依赖JDK,可能和其他客户端不兼容,建议不使用
· alg=1 使用original 兼容hash算法,兼容其他客户端
· alg=2 使用CRC32兼容hash算法,兼容其他客户端,性能优于original算法
· alg=3 使用MD5 hash算法
· 采用前三种hash算法的时候,查找cache服务器使用余数方法。采用最后一种hash算法查找cache服务时使用consistent方法。
· public void initialize()
· 设置完pool参数后最后调用该方法,启动pool。
2、MemCachedClient
· public void setCompressEnable( boolean compressEnable )
· 设定是否压缩放入cache中的数据
· 默认值是ture
· 如果设定该值为true,需要设定CompressThreshold?
· public void setCompressThreshold( long compressThreshold )
· 设定需要压缩的cache数据的阈值
· 默认值是30k
· public void setPrimitiveAsString( boolean primitiveAsString )
· 设置cache数据的原始类型是String
· 默认值是false
· 只有在确定cache的数据类型是string的情况下才设为true,这样可以加快处理速度。
· public void setDefaultEncoding( String defaultEncoding )
· 当primitiveAsString为true时使用的编码转化格式
· 默认值是utf-8
· 如果确认主要写入数据是中文等非ASCII编码字符,建议采用GBK等更短的编码格式
· cache数据写入操作方法
· set方法
· 将数据保存到cache服务器,如果保存成功则返回true
· 如果cache服务器存在同样的key,则替换之
· set有5个重载方法,key和value是必须的参数,还有过期时间,hash码,value是否字符串三个可选参数
· add方法
· 将数据添加到cache服务器,如果保存成功则返回true
· 如果cache服务器存在同样key,则返回false
· add有4个重载方法,key和value是必须的参数,还有过期时间,hash码两个可选参数
· replace方法
· 将数据替换cache服务器中相同的key,如果保存成功则返回true
· 如果cache服务器不存在同样key,则返回false
· replace有4个重载方法,key和value是必须的参数,还有过期时间,hash码两个可选参数
· 建议分析key的规律,如果呈现某种规律有序,则自己构造hash码,提高存储效率
· cache数据读取操作方法
· 使用get方法从cache服务器获取一个数据
· 如果写入时是压缩的或序列化的,则get的返回会自动解压缩及反序列化
· get方法有3个重载方法,key是必须的参数,hash码和value是否字符串是可选参数
· 使用getMulti方法从cache服务器获取一组数据
· get方法的数组实现,输入参数keys是一个key数组
· 返回是一个map
· 通过cache使用计数器
· 使用storeCounter方法初始化一个计数器
· 使用incr方法对计数器增量操作
· 使用decr对计数器减量操作