版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/guanyuqiu/article/details/85276372
scikit-learn 中实现了朴素贝叶斯的方法来源于sklearn.naive_bayes模块,在这个模块下,基于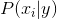
1.Bernoulli Naive Bayes
函数说明:https://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.BernoulliNB.html
此方法主要是针对数据符合多元伯努利分布的朴素贝叶斯分类算法。例如,可能会有多个特征,但每一个被假定为一个二进制值(伯努利、布尔)变量,因此,这类要求的样品被表示为二进制值的特征向量;如果交给其他任何类型的数据,一个bernoullinb实例可以进行输入(取决于二值化参数)
伯努利朴素贝叶斯决策规则的基础上
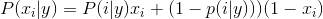
在文本分类中,词出现的频次(不是词数量)可以使用该分类器。bernoullinb对某些数据集执行效果比较好,尤其是那些短的文件。如果时间允许的话,建议对两种模型进行评估。
调用方法:
sklearn.naive_bayes.BernoulliNB(alpha=1.0, binarize=0.0, fit_prior=True, class_prior=None)例子:
import numpy as np
X = np.random.randint(2, size=(6, 100))
Y = np.array([1, 2, 3, 4, 4, 5])
from sklearn.naive_bayes import BernoulliNB
clf = BernoulliNB()
clf.fit(X, Y)
BernoulliNB(alpha=1.0, binarize=0.0, class_prior=None, fit_prior=True)
print(clf.predict(X[2:3]))2.Gaussian Naive Bayes
scikit-learn中高斯贝叶斯应用于分类,特征满足高斯分布:
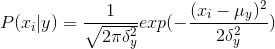
调用方法:
sklearn.naive_bayes.GaussianNB(priors=None, var_smoothing=1e-09)例子:
3.Multinomial Naive Bayes
适用于数据满足multinomially的分布的朴素贝叶斯,经典应用于文本分类(其中的数据是通常表示为词的数量,虽然TF-IDF向量在实际项目中表现得更好),每一类y的分布为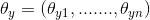
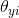
调用方法:
sklearn.naive_bayes.ComplementNB(alpha=1.0, fit_prior=True, class_prior=None, norm=False)