1.BS4的理解
# BS4会将html文档对象转换为python可以识别的四种对象:
Tag: 标签对象
NavigableString : 字符内容操作对象
BeautifulSoup: 文档对象
Comment: 文档中注释节点的内容
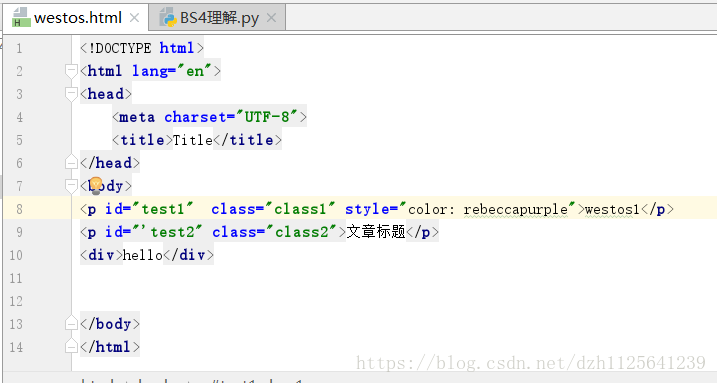
获取标签内容和属性
# 1. 获取标签内容
from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html',encoding="utf-8"),'html.parser')
# 获取标签, 默认获取找到的第一个符合的内容
print(soup.title)
print(type(soup.title))
print(soup.p)
#2. 获取标签的属性
print(soup.p.attrs)
# 获取标签指定属性的内容
print(soup.p['id'])
print(soup.p['class'])
print(soup.p['style'])
# 对属性进行修改
soup.p['id'] = 'dzh'
print(soup.p)
print(type(soup.p))

获取标签的文本内容
# 3. 获取标签的文本内容
from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
print(dir(soup.title))
print(soup.title.text)
print(soup.title.string)
print(soup.title.name)
print(soup.head.title.string)

操作子节点
# 4. 操作子节点
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
print(soup.head.contents)
print(soup.head.children)
for el in soup.head.children:
print('--->', el)

面向对象的匹配
# 5.面向对象的匹配
import re
from bs4 import BeautifulSoup
# # 查找指定的标签内容(指定的标签)
res1 = soup.find_all('p')
print(res1)
# # 查找指定的标签内容(指定的标签)--与正则的使用
res2 = soup.find_all(re.compile(r'd+'))
print(res2)
# # 对于正则表达式进行编译, 提高查找速率;
pattern = r'd.+'
pattern = re.compile(pattern)
print(re.findall(pattern, 'dog hello d'))

import re
from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
# 详细查找标签
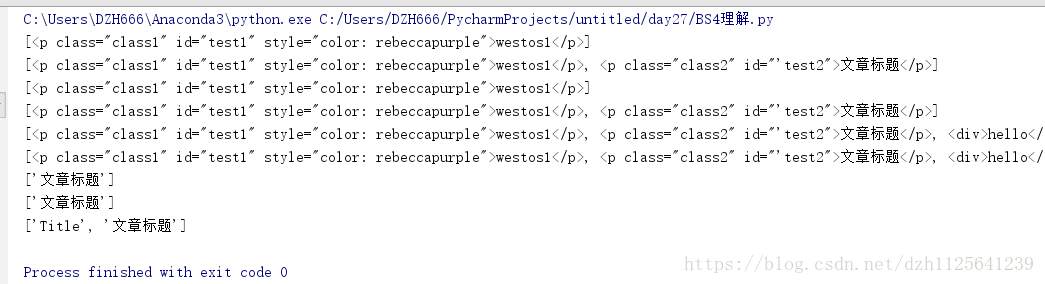
print(soup.find_all('p', id='test1'))
print(soup.find_all('p', id=re.compile(r'test\d{1}')))
print(soup.find_all('p', class_="class1"))
print(soup.find_all('p', class_=re.compile(r'class\d{1}')))
# 查找多个标签
print(soup.find_all(['p', 'div']))
print(soup.find_all([re.compile('^d'), re.compile('p')]))
# 内容的匹配
print(soup.find_all(text='文章标题'))
print(soup.find_all(text=re.compile('标题')))
print(soup.find_all(text=[re.compile('标题'), 'Title']))
CSS匹配
import re
from bs4 import BeautifulSoup
# 构造对象
soup = BeautifulSoup(open('westos.html'), 'html.parser')
# CSS常见选择器: 标签选择器(div), 类选择器(.class1), id选择器(#idname), 属性选择器(p[type="text"])
# 标签选择器(div)
res1 = soup.select("p")
print(res1)
# 类选择器(.class1)
res2 = soup.select(".class2")
print(res2)
# id选择器(#idname)
res3 = soup.select("#test1")
print(res3)
# 属性选择器(p[type="text"]
print(soup.select("p[id='test1']"))
print(soup.select("p['class']"))

2.获取豆瓣最新电影的id号和电影名称
import requests
from bs4 import BeautifulSoup
url = "https://movie.douban.com/cinema/nowplaying/xian/"
# 1). 获取页面信息
response = requests.get(url)
content = response.text
# print(content)
# 2). 分析页面, 获取id和电影名
soup = BeautifulSoup(content, 'lxml')
# 先找到所有的电影信息对应的li标签;
nowplaying_movie_list = soup.find_all('li', class_='list-item')
# print(nowplaying_movie_list[0])
# print(type(nowplaying_movie_list[0]))
# 存储所有电影信息[{'title':"名称", "id":"id号"}]
movies_info = []
# 依次遍历每一个li标签, 再次提取需要的信息
for item in nowplaying_movie_list:
nowplaying_movie_dict = {}
# 根据属性获取title内容和id内容
# item['data-title']获取li标签里面的指定属性data-title对应的value值;
nowplaying_movie_dict['title'] = item['data-title']
nowplaying_movie_dict['id'] = item['id']
# 将获取的{'title':"名称", "id":"id号"}添加到列表中;
movies_info.append(nowplaying_movie_dict)
print(movies_info)

3.获取指定电影的影评信息
# 目标:
# 1). 爬取某一页的评论信息;
# 2).爬取某个电影的前2页评论信息;
import threading
import requests
from bs4 import BeautifulSoup
# # 1). 爬取某一页的评论信息;
def getOnePageComment(id, pageNum):
# 1). 根据页数确定start变量的值
# 第一页: https://movie.douban.com/subject/26425063/comments?start=0&limit=20&sort=new_score&status=P
# 第二页: https://movie.douban.com/subject/26425063/comments?start=20&limit=20&sort=new_score&status=P
# 第三页: https://movie.douban.com/subject/26425063/comments?start=40&limit=20&sort=new_score&status=P
start = (pageNum-1)*20
url = "https://movie.douban.com/subject/%s/comments?start=%s&limit=20&sort=new_score&status=P" %(id, start)
# 2). 爬取评论信息的网页内容
content = requests.get(url).text
# 3). 通过bs4分析网页
soup = BeautifulSoup(content,'lxml')
# 分析网页得知, 所有的评论信息都是在span标签, 并且class为short;
commentsList = soup.find_all('span', class_='short')
pageComments = ""
# 依次遍历每一个span标签, 获取标签里面的评论信息, 并将所有的评论信息存储到pageComments变量中;
for commentTag in commentsList:
pageComments += commentTag.text
# return pageComments
print("%s page" %(pageNum))
#定义comments为全局变量
global comments
comments += pageComments
# 2).爬取某个电影的前2页评论信息;
id = '26425063'
comments = ''
threads = []
# 爬取前2页的评论信息;获取前几页就循环几次;
for pageNum in range(2): # 0 , 1 2
pageNum = pageNum + 1
# getOnePageComment(id, pageNum)
# 通过启动多线程获取每页评论信息
t = threading.Thread(target=getOnePageComment, args=(id, pageNum))
threads.append(t)
t.start()
# 等待所有的子线程执行结束, 再执行主线程内容;
_ = [thread.join() for thread in threads]
print("执行结束")
print(comments)

4.数据清洗
完整的分析过程:
- 数据的获取: 通过爬虫获取(urllib|requests<获取页面内容> + re|bs4<分析页面内容>)
- 数据清洗: 按照一定的格式岁文本尽心处理;
import re
import wordcloud
import jieba
# 1. 对于爬取的评论信息进行数据清洗(删除不必要的逗号, 句号, 表情, 只留下中文或者英文内容)
with open('./doc/26425063.txt') as f:
comments = f.read()
# 通过正则表达式实现
pattern = re.compile(r'([\u4e00-\u9fa5]+|[a-zA-Z]+)')
deal_comments = re.findall(pattern, comments)
newComments = ''
for item in deal_comments:
newComments += item
print(newComments)
5.词云分析
import jieba
import wordcloud
import numpy as np
from PIL import Image
text= "马云曾公开表态称对钱没兴趣称其从来没碰过钱上了微博热搜"
# 2). '微博热', '搜'切割有问题, 可以强调
# jieba.suggest_freq(('微博'),True)
# jieba.suggest_freq(('热搜'),True)
# 强调文件中出现的所有词语;
jieba.load_userdict('./doc/newWord')
# 1). 切割中文, lcut返回一个列表, cut返回一个生成器;
result = jieba.lcut(text)
print("切分结果:", result)
# 4). 绘制词云
wc = wordcloud.WordCloud(
background_color='snow',
font_path='./font/msyh.ttf', # 处理中文数据时
min_font_size=5, # 图片中最小字体大小;
max_font_size=15, # 图片中最大字体大小;
width=200, # 指定生成图片的宽度
)
wc.generate(",".join(result))
wc.to_file('./doc/douban.png')
6.电影评论词云分析
import jieba
import wordcloud
import numpy as np
# 在python2中处理图像,Image; python3中如果处理图像, 千万不要安装Image, 安装pillow
from PIL import Image
# 1). 切割中文, lcut返回一个列表, cut返回一个生成器;
result = jieba.lcut(open('./doc/26425063.txt').read())
# 2). 打开图片
imageObj = Image.open('./doc/mao.jpg')
cloud_mask = np.array(imageObj)
# 4). 绘制词云
wc = wordcloud.WordCloud(
mask = cloud_mask,
background_color='black',
font_path='./font/msyh.ttf', # 处理中文数据时
min_font_size=5, # 图片中最小字体大小;
max_font_size=50, # 图片中最大字体大小;
width=500, # 指定生成图片的宽度
)
wc.generate(",".join(result))
wc.to_file('./doc/douban.png')