用python爬取贴吧数据
有时会逛贴吧,看故事,看别人侃大山,
但是一页一页翻费劲啊;
又没有按回复量排序的功能(实验功能根本不能用!),ಥ_ಥ…
这促使我写了个python爬虫,爬取点击量超过某个阈值的帖子。
自身需求绝对是学习的第一动力。
虽然代码量不大,但有效地解决了问题,
看到成果出来,心中好像有泉水汩汩涌出~

实现思路很简单,
用python模拟浏览器发送get请求,
从返回的信息中提取点击量高的帖子,
以上两步循环若干次,
再将最终结果转为pandas对象,
然后可以导出到Excel,
就完成啦~
用到的python包有requests,BeautifulSoup,pandas,官网有详细用例。
代码如下:
# 导入需要的包
import time
# 模拟http请求 和 解析内容 的包
import requests
from bs4 import BeautifulSoup
# 数据展示 的包
import numpy as np
import pandas as pd# 设置点击量阈值
M = 3000
# get请求模版
template_url = "https://tieba.baidu.com/f?kw=%E5%BF%83%E7%90%86%E5%AD%A6&ie=utf-8&pn={}"{ }为占位符,方便发送不同页面(第n页)的请求。
# 从一页中提取 帖子
def extra_from_one_page(page_lst):
'''从一页中提取 帖子'''
# 临时列表保存字典数据,每一个帖子都是一个字典数据
tmp = []
for i in page_lst:
# 判断是否超过阈值
if int(i.find(class_='threadlist_rep_num').text) > M:
dic = {}
# 点击量
dic['num'] = int(i.find(class_='threadlist_rep_num').text)
# 帖子名称
dic['name'] = i.find(class_='threadlist_title').text
# 帖子地址
dic['address'] = 'https://tieba.baidu.com' + i.find(class_='threadlist_title').a['href']
tmp.append(dic)
return tmp以上 class name 是基于对贴吧html页面结构的观察而定的。(方法:在浏览器中打开控制台仔细观察)
# 爬取n页的数据
def search_n_pages(n):
'''爬取n页数据'''
target = []
# 发起n次的get请求
for i in range(n):
# 跟踪进度
print('page:', i)
# 按照浏览贴吧的自然行为,每一页50条
target_url = template_url.format(50*i)
res = requests.get(target_url)
# 转为 bs 对象
soup = BeautifulSoup(res.text, 'html.parser')
# 获取该页帖子列表
page_lst = soup.find_all(class_='j_thread_list')
# 该页信息保存到target
target.extend(extra_from_one_page(page_lst))
# 休息0.2秒再访问,友好型爬虫
time.sleep(0.2)
return target功能主体实现完毕,下面以十分活跃的心理学吧为例,进行展示。
# 爬取贴吧前200页数据
d = search_n_pages(200)我电脑的运行时间:
CPU times: user 40.4 s, sys: 496 ms, total: 40.9 s
Wall time: 5min 5s
# 转化为pandas.DataFrame对象
data = pd.DataFrame(d)
# 导出到excel表格
data.to_excel('心理学-贴吧.xlsx')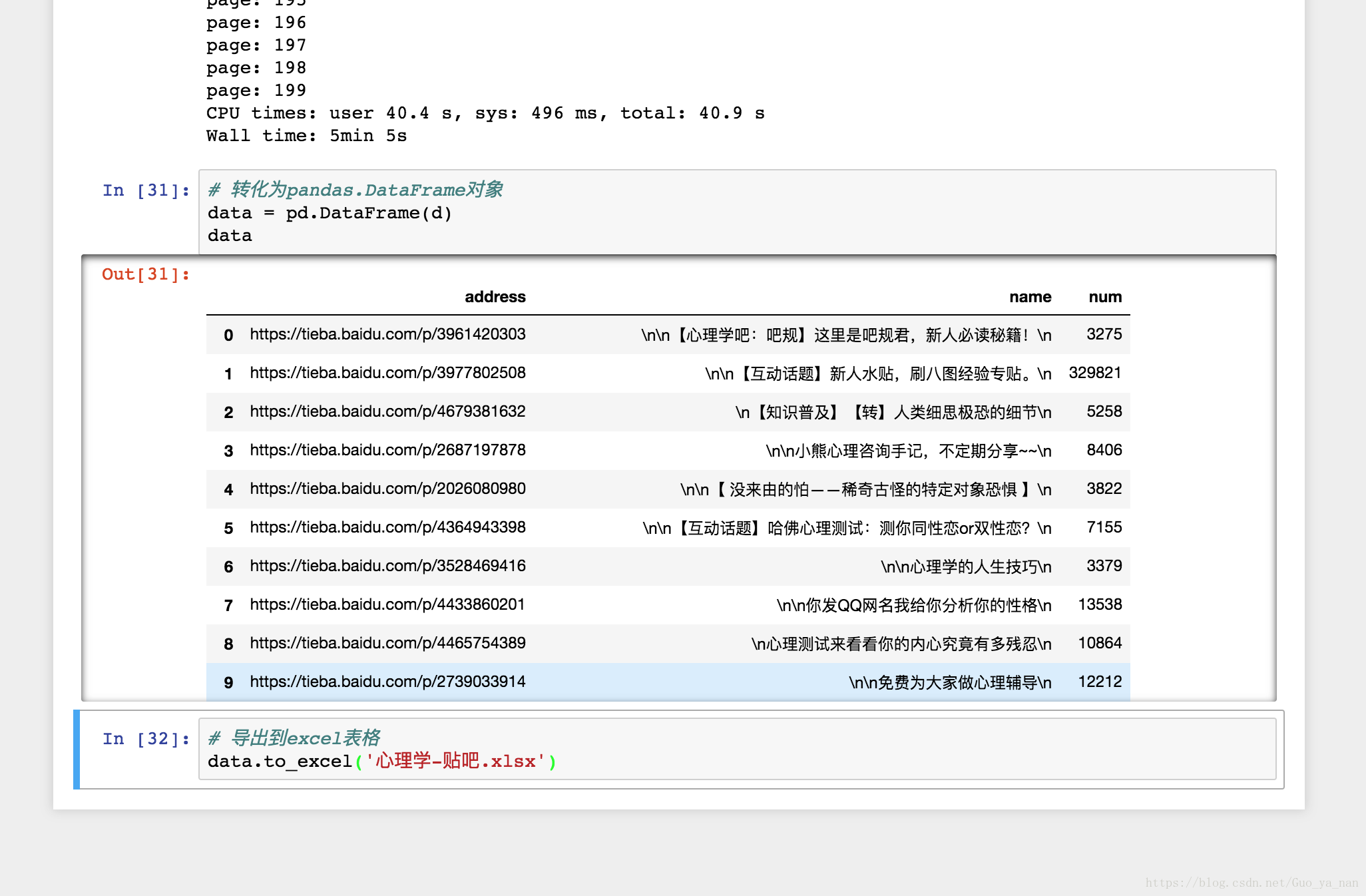
得到结果之后就可以想个哪个点哪个了,节省了很多人工检索的时间~