写在前面
本篇文章主要介绍美团美食页面爬取(web版)
整体思路
通过分析,我们发现美团美食的数据是通过ajax请求来的。
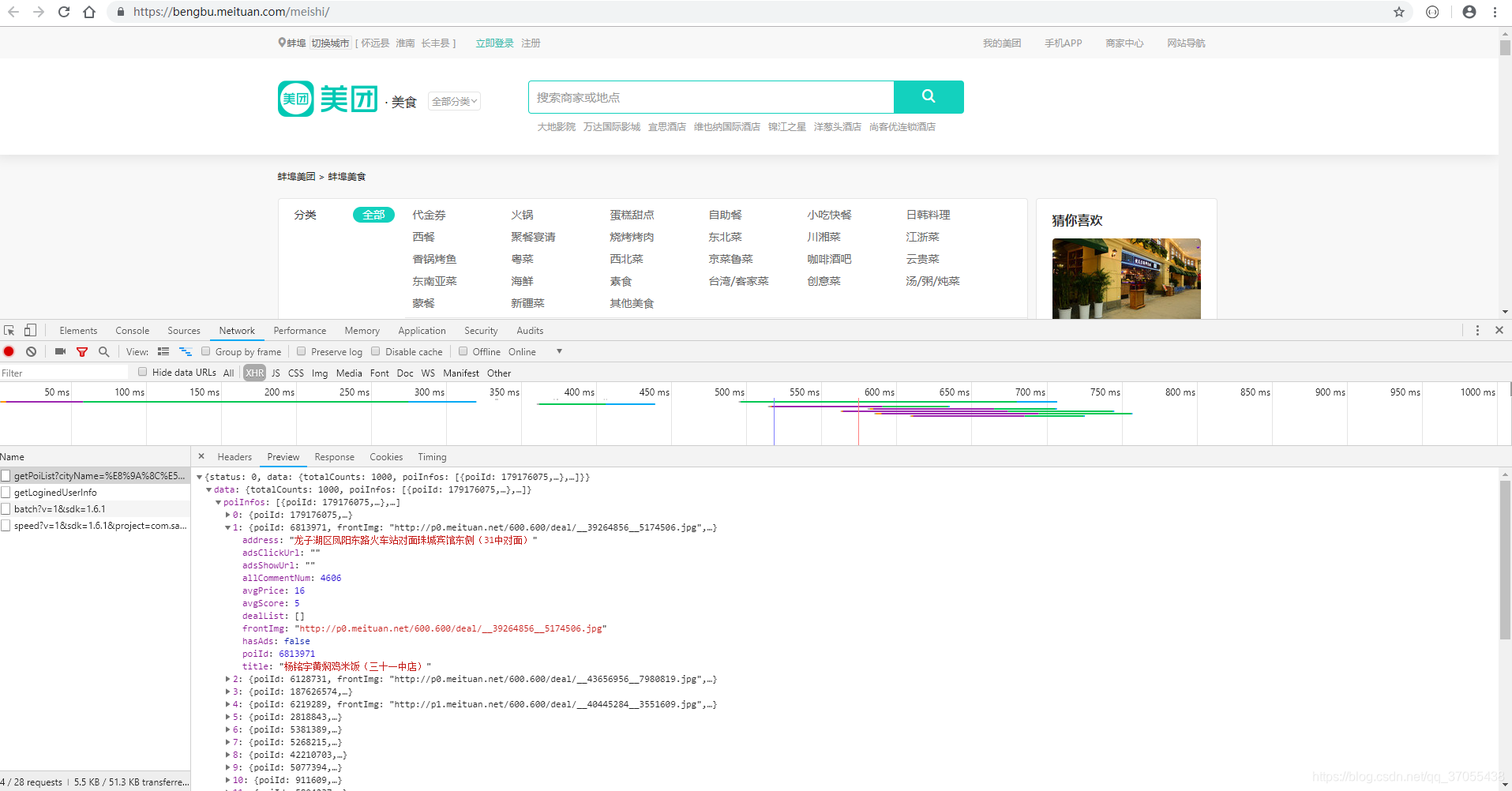
所以接下来,我们只需要请求这个接口就行了。分析下这个接口的request-header。发现有一点复杂欸(别慌,马上告诉你答案)
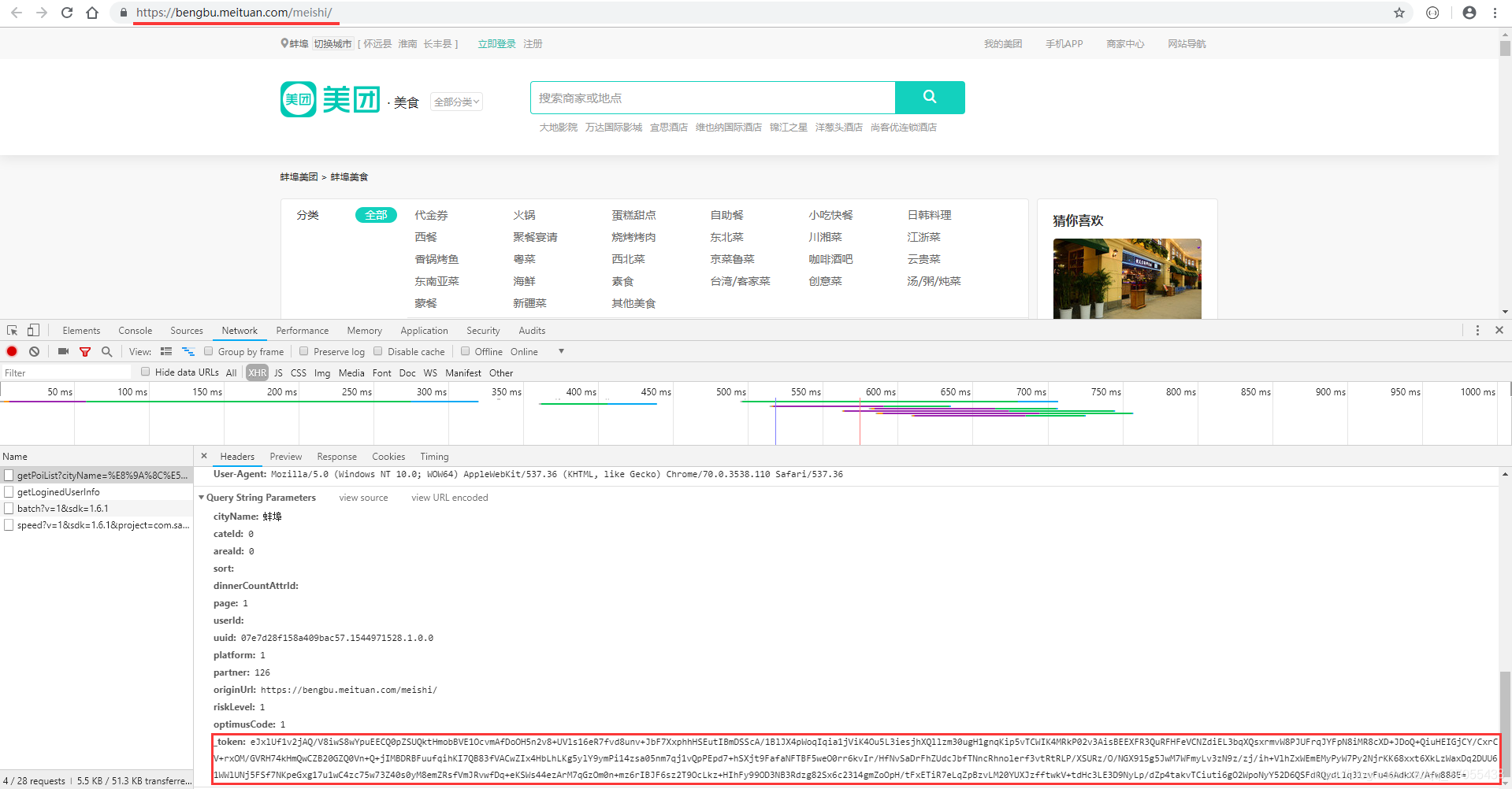
说一下图片中我标记的地方
- url 栏里面的地址可以在城市切换页面爬取到(
这个很简单) - 主要是token是加密的
- token是先用的
zlib加密,然后再base64加密(通过看加密字符类型和字符长度可以大概推断是哪种加密),当然,解密也就是反着来啦。对了,token解密后里面还有个sign参数,也是用的同样的加密方式。
- token是先用的
我把token拿出来大概做个示范,你一看就懂了

拿到解密后的token,整个ajax请求在你面前可以算是透明的了,接下来就是自己造token然后请求api拿到商家信息了
代码参考
下面附上我写的代码(防反爬还没怎么写,但用上随机ua头和代理应该还行)
from requests import RequestException
from fake_useragent import UserAgent
from lxml.html import etree
import base64, zlib, json
import requests
from urllib import parse
import time
class Spider(object):
def __init__(self):
self.headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Proxy-Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1',
}
# 请求城市列表
def get_cities(self):
self.headers['User-Agent'] = UserAgent().random # 随机请求头
self.headers['Host'] = 'www.meituan.com'
self.headers['Referer'] = 'https://www.meituan.com/changecity/'
try:
response = requests.get('https://www.meituan.com/changecity/', headers=self.headers)
if response.status_code == 200:
return self.parse_cities(response.text)
except RequestException as e:
pass
# 解析城市列表
def parse_cities(self, html):
html = etree.HTML(html)
cities = html.xpath('//div[@class="alphabet-city-area"]//a')
for city in cities:
self.get_meishi('http:'+city.xpath('./@href')[0]+'/meishi/' ,city.xpath('./text()')[0])
# 构造token
def get_token(self, url, city, page):
sign = '"areaId=0&cateId=0&cityName={}&dinnerCountAttrId=&optimusCode=1' \
'&originUrl={}&page={}&partner=126&platform=1&riskLevel=1&sort=' \
'&userId=&uuid=5bb9712c812a4ee18eb2.1544868815.1.0.0"'.format(
city, url, page)
token = {
"rId": 100900,
"ver": "1.0.6",
"ts": int(time.time()*1000),
"cts": int(time.time()*1000)+100,
"brVD": [290, 667],
"brR": [[1920, 1080], [1920, 1040], 24, 24],
"bI": ["{}".format(url), ""],
"mT": ["255,230"],
"kT": [],
"aT": [],
"tT": [],
"aM": '',
"sign": str(base64.b64encode(zlib.compress(bytes(sign, encoding='utf8'))), encoding='utf8')
}
return str(base64.b64encode(zlib.compress(bytes(str(token).replace(' ','').replace("'",'"'), encoding='utf8'))), encoding='utf8')
def get_meishi(self, url, city):
for page in range(1, 33):
self.headers['User-Agent'] = UserAgent().random
requests_url = '{}api/poi/getPoiList?cityName={}&cateId=0&areaId=0&sort=&dinnerCountAttrId=&page={}&userId=' \
'&uuid=5bb9712c812a4ee18eb2.1544868815.1.0.0&platform=1&partner=126&originUrl={}&riskLevel=1' \
'&optimusCode=1&_token={}'.format(url, parse.quote(city), page, parse.quote(url+'pn{}/'.format(page)), parse.quote(self.get_token(url, city, page)))
print(requests_url)
try:
response = requests.get(requests_url, headers=self.headers)
if response.status_code == 200:
self.parse_meishi(response.text)
except RequestException as e:
pass
def parse_meishi(self, html):
try:
result = json.loads(html)
if result:
print(result)
except:
pass
def run(self):
self.get_cities()
if __name__ == '__main__':
Spider().run()