通过抓取乐有家房产公司的信息,研究下长沙的房价。最后用Pandas和Matplotlib进行了分析。
网页结构分析
乐有家长沙二手房信息网页(https://changsha.leyoujia.com/esf/)

接着用Scrapy shell验证二手房XPath表达式
#标题
response.xpath('./div[@class="text"]/p[@class="tit"]/a/text()').extract_first()
#总价
response.xpath('./div[@class="price"]/p[@class="sup"]/span[@class="salePrice"]/text()').extract_first()
#单价
response.xpath('./div[@class="price"]/p[@class="sub"]/text()').re(r'单价(.*?)元/㎡')[0]
#面积
reponse.xpath('./div[@class="text"]/p[@class="attr"]/span/text()').re(r'套内面积(.*?)㎡')[0]
#区域
response.xpath('./div[@class="text"]//a/text()').re(r'开福|雨花|岳麓|天心|芙蓉|望城|星沙')[0]
二手房爬虫
二手房的信息比较少,用一般的Scrapy就可以。
在目标文件夹中运行以下代码,创建一个爬虫:
scrapy startproject ershoufang_spider
在items.py文件中定义items:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class LeyoujiaItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
acreage = scrapy.Field()
distrct = scrapy.Field()
evprice = scrapy.Field()
根据上文构造的XPath表达式,写一个二手房页面的爬虫:
# -*- coding: utf-8 -*-
import scrapy
from LeyouJia.items import LeyoujiaItem
class ZufangSpiderSpider(scrapy.Spider):
name = "ershoufang_spider"
allowed_domains = ['changsha.leyoujia.com']
start_urls = ['https://changsha.leyoujia.com/esf/']
def parse(self, response):
for zu_items in response.xpath('//li[@class="item clearfix"]'):
yield {
'title':zu_items.xpath('./div[@class="text"]/p[@class="tit"]/a/text()').extract_first(),
'price':zu_items.xpath('./div[@class="price"]/p[@class="sup"]/span[@class="salePrice"]/text()').extract_first(),
'evprice':zu_items.xpath('./div[@class="price"]/p[@class="sub"]/text()').re(r'单价(.*?)元/㎡')[0],
'acreage':zu_items.xpath('./div[@class="text"]/p[@class="attr"]/span/text()').re(r'套内面积(.*?)㎡')[0],
'distrct':zu_items.xpath('./div[@class="text"]//a/text()').re(r'开福|雨花|岳麓|天心|芙蓉|望城|星沙')[0]
}
next_page_url = response.xpath('.//div[@class="jjs-new-page fr"]/a[last()-1]/@href').extract_first()
if next_page_url is not None:
yield scrapy.Request(response.urljoin(next_page_url))
使用以下命令运行爬虫,并将爬取结果保存为json格式:
scrapy crawl -o test2.json
这时候可以看到运行成功的界面

数据分析及可视化
使用的库是Pandas和Matplotlib。
二手房屋出售分布饼图:
import pandas as pd
import matplotlib.pyplot as plt
labels = '开福','雨花','岳麓','天心','芙蓉','望城'
df_zf = pd.read_json("../LeyouJia/test2.json")
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
kaifu_count =df_zf['distrct'].value_counts()['开福']
yuhua_count =df_zf['distrct'].value_counts()['雨花']
yuelu_count =df_zf['distrct'].value_counts()['岳麓']
tianxin_count =df_zf['distrct'].value_counts()['天心']
forong_count =df_zf['distrct'].value_counts()['芙蓉']
wangcheng_count =df_zf['distrct'].value_counts()['望城']
sizes = [kaifu_count,yuhua_count,yuelu_count,tianxin_count,forong_count,wangcheng_count]
explode = (0.1, 0, 0, 0,0,0)
plt.subplot(111)
plt.pie(sizes, explode=explode, labels=labels, autopct='%1.1f%%',
shadow=True, startangle=-90)
plt.axis('equal')
plt.title("长沙二手房屋出售分布")
plt.show()
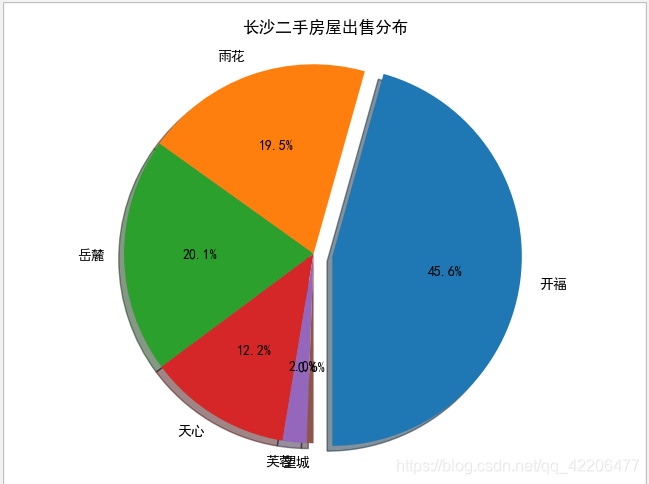
在二手房销售市场上,开福区销售二手房数量最多,占比45.6%
长沙房价分布区间
import numpy as np
import pandas as pd
import json
import matplotlib.pyplot as plt
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
df = pd.read_json("../LeyouJia/test2.json")
print(df.columns)
unitprice_values = df.evprice
plt.hist(unitprice_values,
bins=25
)
plt.xlim(5000,30000)
plt.title(u"房屋出售每平米价格分布")
plt.xlabel(u'价格(单位:元/平方米)')
plt.ylabel(u'套数')
plt.show()
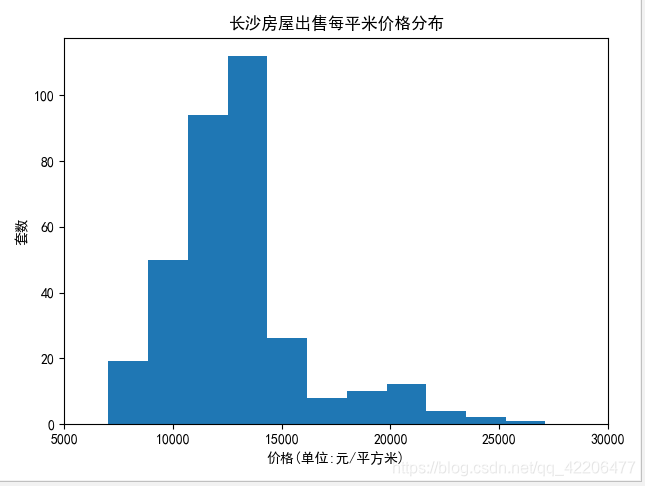
房屋单价分布在0.6万每平米到3万每平米之间。大部分处于1万到1.45万的区间之内。