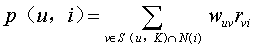主页 商品页 推荐页
协同过滤的过程分为这三步:一开始,收集用户信息,然后以此生成矩阵来计算用户关联,最后作出高可信度的推荐。这种技术分为两大类:一种是基于用户的协同过滤,一种则是基于物品的协同过滤。我们的系统采用的是基于物品的协同过滤方法。
基于物品的协同过滤算法核心思想是:给用户推荐那些和他们之前喜欢的物品相似的物品,值得注意的是,这里所说的物品A和物品B具有很大的相似度是因为喜欢物品A的用户大都也喜欢B。 实现算法主要分为两步:
计算物品之间的相似度:
其中,
∣
\mid
∣
∣
\mid
∣
∣
\mid
∣
∣
\mid
∣
∣
\mid
∣
⋂
\bigcap
⋂
∣
\mid
∣
这里面有个假设,就是每个用户的兴趣都局限在某几个方面。如果用户之间的兴趣广泛且不相交,那么即使存在同时喜欢物品i和物品j的用户数多,那也不能代表物品i和物品j的相似度大,因为很可能两种物品所属领域非常不同。
根据物品的相似度和用户的历史行为给用户生成推荐列表:
其中, p(u,i)表示用户 u 对物品 j 的兴趣, N(i)表示用户喜欢的物品集合(u是该用户喜欢的某一个物品), S(u,K)表示和物品 u 最相似的 K 个物品集合(i 是这个集合中的某一个物品), wuv 表示物品 u 和物品 v 的相似度,rvi 表示用户 v 对物品 i 的兴趣(这里简化rvi 都等于1)。
该公式的含义可以理解为:和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中获得比较高的排名。
连接数据库
def connectMongo ( host, port, username, password, db) :
if username and password:
mongo_url = "mongodb://%s:%s@%s:%s/%s" % ( username, password, host, port, db)
connection = MongoClient( mongo_url)
else :
connection = MongoClient( host, port)
return connection[ db]
构建一个二维数组,根据商品的浏览记录,购买记录,总浏览量等计算相关性
def getMatrix ( db) :
matrix = list ( )
goods = list ( db. goods. find( ) )
goodsTitle = list ( [ 'username' ] )
for good in goods:
goodsTitle. append( str ( good[ '_id' ] ) )
users = list ( db. users. find( ) )
for user in users:
userRow = list ( [ user[ 'username' ] ] )
for i in range ( len ( goods) ) :
userRow. append( goods[ i] [ 'sale' ] * 0.3 + goods[ i] [ 'view' ] * 0.1 )
for key in user[ 'goods' ] :
for i in range ( len ( goods) ) :
if str ( goods[ i] [ '_id' ] ) == str ( key) :
userRow[ i + 1 ] = user[ 'goods' ] [ key] [ 'bought' ] * 3 + user[ 'goods' ] [ key] [ 'view' ] * 0.5 + goods[ i] [ 'sale' ] * 0.3 + goods[ i] [ 'view' ] * 0.1
break
matrix. append( userRow)
return ( goodsTitle, matrix)
将得到的矩阵传给getRecommand函数,根据矩阵计算其他商品对于客户的推荐分,最后将得分最高的商品进行推荐
def getRecommand ( header, matrix) :
data = pd. DataFrame( matrix)
data. columns = header
data. set_index( 'username' , inplace = True )
corrMatrix = data. corr( method = 'pearson' )
recommandResult = list ( )
for row in matrix:
username = row[ 0 ]
myRatings = data. loc[ username] . dropna( )
simCandidates = pd. Series( )
for i in range ( 0 , len ( myRatings. index) ) :
sims = corrMatrix[ myRatings. index[ i] ] . dropna( )
sims = sims. map ( lambda x: x * myRatings[ i] )
simCandidates = simCandidates. append( sims)
simCandidates. sort_values( inplace = True , ascending = False )
simCandidates = simCandidates. groupby( simCandidates. index) . sum ( )
simCandidates. sort_values( inplace = True , ascending = False )
recommands = list ( )
for i in range ( 0 , len ( simCandidates. index) ) :
if i < 4 :
recommands. append( simCandidates. index[ i] )
elif i < 10 and i * 3 <= len ( simCandidates. index) :
recommands. append( simCandidates. index[ i] )
result = { }
result[ 'username' ] = username
result[ 'recommands' ] = recommands
recommandResult. append( result)
return recommandResult
将得到的数据写入数据库
def updateRecommandToDB ( db, recommandForEachUser) :
for recommand in recommandForEachUser:
db. users. update_one( { 'username' : recommand[ 'username' ] } , { '$set' : { 'recommands' : recommand[ 'recommands' ] } } )
姓名
学号
贡献度
锺文杰
15331429
50%
周锐
15331434
25%
朱薇薇
15331442
25%
 主页向用户展现了能够购买的物品的图片、价格以及库存。点击商品图片可以进入商品页,点击主页右下角的推荐图标可以进入推荐页。
主页向用户展现了能够购买的物品的图片、价格以及库存。点击商品图片可以进入商品页,点击主页右下角的推荐图标可以进入推荐页。 商品页能看到商品简介、价格、浏览量等信息,以及出现购买量与购买图标。
商品页能看到商品简介、价格、浏览量等信息,以及出现购买量与购买图标。 系统根据用户对某个商品的浏览次数、购买记录以及该商品的总访问量和销量而对用户进行的相关推荐。上图是在已经购买了主页的2种网球之后生成的,可以看到推荐系统基于我们的偏好,向我们推荐了可能会喜欢的Wilson护腕
系统根据用户对某个商品的浏览次数、购买记录以及该商品的总访问量和销量而对用户进行的相关推荐。上图是在已经购买了主页的2种网球之后生成的,可以看到推荐系统基于我们的偏好,向我们推荐了可能会喜欢的Wilson护腕