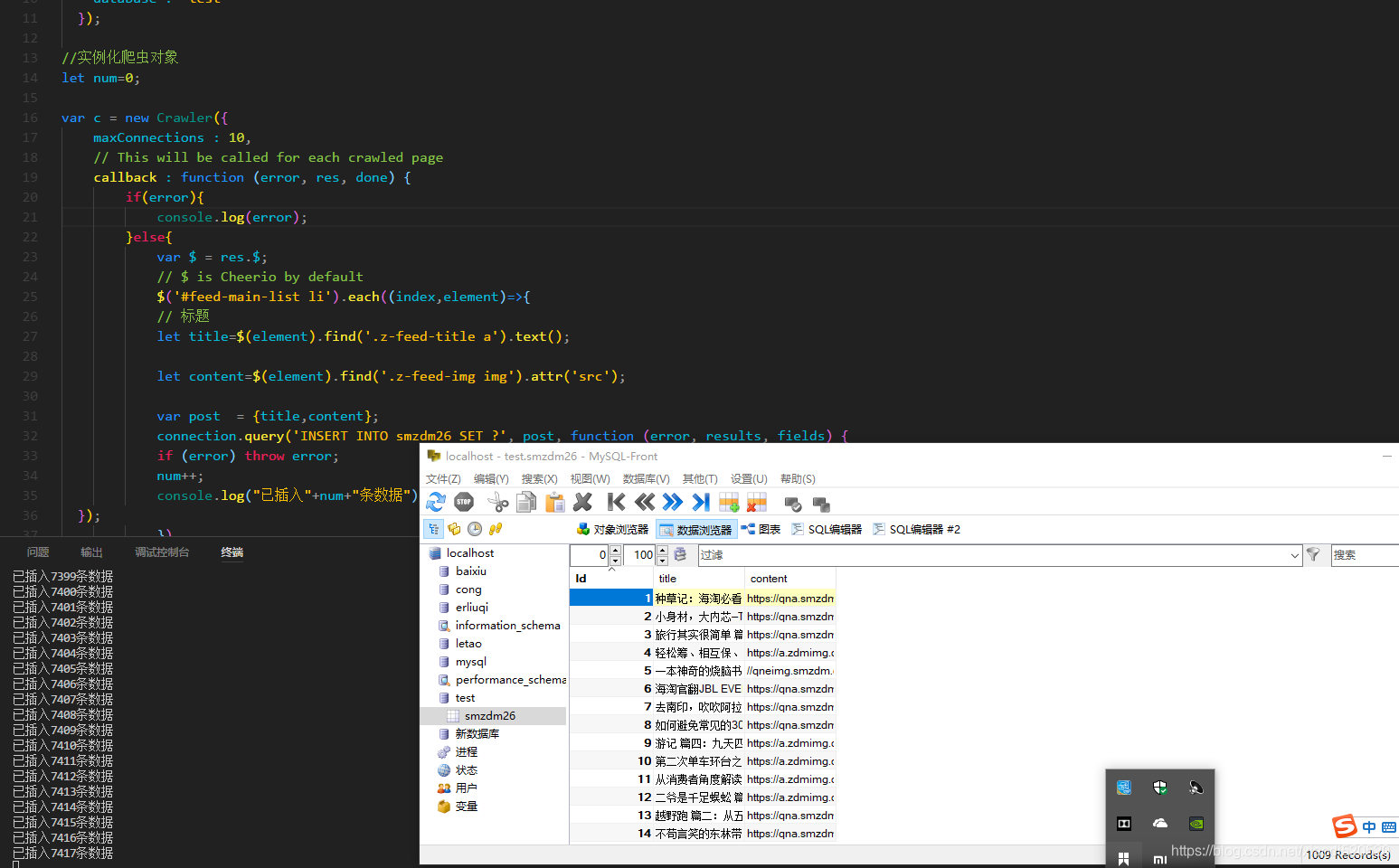
npm中有一个crawler模块是专门用来爬取数据的,可以上别人的网站爬取的数据保存在数据库中,代码使用过程如下:
// 导入模块 mysql
const mysql=require('mysql');
// 导入模块 Crawler
const Crawler=require('Crawler');
//创建数据库连接
var connection = mysql.createConnection({
host : 'localhost',
user : 'root',
password : 'root',
database : 'test'
});
//实例化爬虫对象
let num=0;
var c = new Crawler({
maxConnections : 10,
// This will be called for each crawled page
callback : function (error, res, done) {
if(error){
console.log(error);
}else{
var $ = res.$;
// $ is Cheerio by default
$('#feed-main-list li').each((index,element)=>{
// 标题
let title=$(element).find('.z-feed-title a').text();
let content=$(element).find('.z-feed-img img').attr('src');
var post = {title,content};
connection.query('INSERT INTO smzdm26 SET ?', post, function (error, results, fields) {
if (error) throw error;
num++;
console.log("已插入"+num+"条数据");
});
})
}
done();
}
});
// 爬取数据
// Queue just one URL, with default callback
for(let i=0;i<5000;i++){
c.queue('https://post.smzdm.com/p'+i);
}
效果图: