中文介绍:MatConvNet是一个MATLAB工具箱,提供了计算机视觉的卷积神经网络(CNN)。简单,高效,是一个先进的可以运行和学习的CNN。许多预测训练的CNN网络可以用于图像分类,分割,面部识别和文本检测。
下载官网:http://www.vlfeat.org/matconvnet/
下载后无需安装,只需解压,然后在Matlab中进行配置即可。
实验平台:win7 64位;Matlab R2015b;VS2013;matconvnet-1.0-beta20
(注意较新的版本如matconvnet-1.0-beta25,不支持vs2013)
配置GPU时,用的CUDA v7.5,cuDNNv5.0(开始装的CUDAv8.0,出现错误,卸载装7.5成功)
下载完成后解压到文件夹:

下面步入正题:
一、 CPU配置
1、打开MATLAB,进入解压的文件夹路径;
2、在命令窗口输入:mex –setup(注意中间有空格,不是下划线):
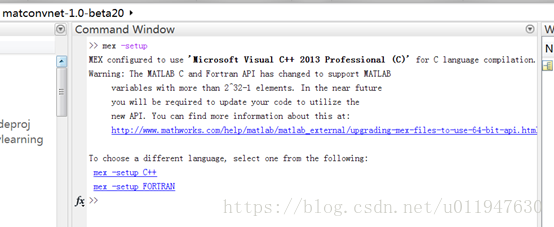
3、点击mex-setup C++

4、在matconvnet-1.0-beta20文件夹下新建Compile.m文件,并运行:
addpath matlab
vl_compilenn
5、结果如下,则表示成功:

二、 GPU配置
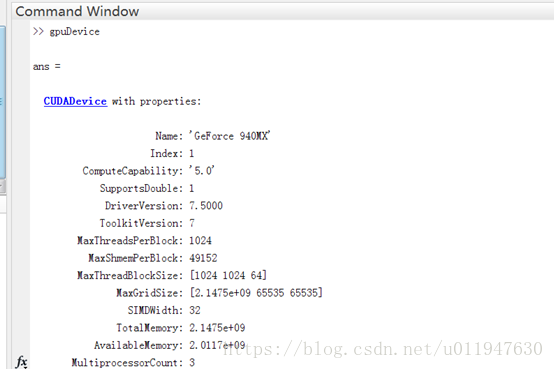
可以先在MATLAB中运行命令gpuDevice,查看电脑显卡属性;
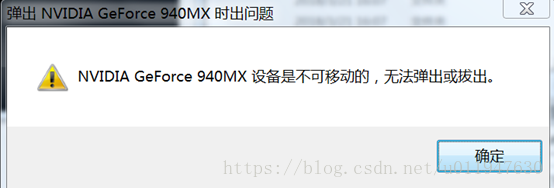
若弹出如下窗口,则可能显卡驱动版本不对,可以卸载驱动,然后用驱动精灵安装其推荐的版本,重启即可。
1、 需要先下载安装CUDA,下载地址:https://developer.nvidia.com/cuda-downloads
注意下载的CUDA版本要支持电脑上的GPU型号。安装最好安装在默认路径下。

【下面这一步可以跳过,但最好检查一下(检查是否安装CUDA成功):】
1. 在默认安装路径下,C:\ProgramData\NVIDIACorporation\CUDA Samples\v7.5中,打开Samples_vs2013.sln(即本机vs对应版本即可),在release下生成解决方案:
可能会遇到错误(这个错误在安装CUDAv8.0遇到,安装DXSDK_Jun10.exe后还是有错误,后来卸载8.0安装7.5直接成功):
找不到”d3dx9.h”、”d3dx10.h”、”d3dx11.h”头文件,网上的方法是百度下载DXSDK_Jun10.exe并安装(在第一次安装CUDA8.0时这样尝试没有用,后面卸载CUDA8.0装7.5直接没有问题了,不知道和安装了这个有没有关系)。
下载网址http://www.microsoft.com/en-us/download/details.aspx?id=6812
之后再重新编译。
2. 编译完成后,在文件夹C:\ProgramData\NVIDIACorporation\CUDA Samples\v7.5\bin\win64\Release下,利用cmd打开分别bandwidthTest.exe,以及deviceQuery.exe,判断是否安装成功,Result=PASS 即成功。
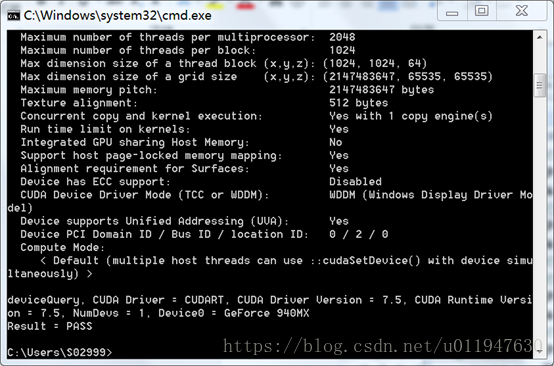
2、下载cuDNN。下载地址:https://developer.nvidia.com/cudnn
注意下载的cuDNN版本要与安装的CUDA版本对应:

3、将下载好的cuDNN解压,在你的matconvnet的路径下面新建文件夹local,将解压后的cuDNN文件夹放在local中。然后将cuDD里面的bin文件夹下面的cudnn64_5.dll文件复制至matconvnet的matlab里面的mex文件夹里面。
4、输入命令 mex –setup,等等(同CPU中2、3步骤);
5、为cuDNN搭建配置:
在matconvnet的路径下面创建一个名字为:compileGPU 的.m文件(CODE如下):
addpath matlab;
vl_compilenn('enableGpu', true, ...
'cudaRoot', 'C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v7.5', ... %填写CUDA安装路径
'cudaMethod', 'nvcc', 'enableCudnn', 'true', ...
'cudnnRoot', 'E:\matconvnet-1.0-beta20\local\cuda'); % cuDNN路径
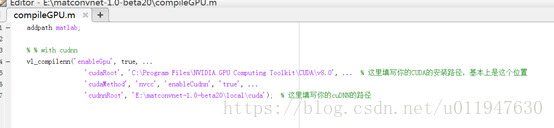
6、 运行该compileGPU.m文件,若无错误,则GPU配置完成。
本人遇到错误如下:Error: matlab/src/bits/impl/pooling_gpu.cu(163)
原因:这个的原因是CUDA6.0 后定义了atomicAdd 所以会出现重复定义的错误。 一共有两个文件里存在这个重复定义的问题,分别在
pooling_gpu.cu,line 163
(定义了atomicadd)
bilinearsampler_gpu.cu,line 25
(定义了atomicadd)
Solution: 这个的解决方式是在这两个文件里定义如下的宏:
#if!defined(__CUDA_ARCH__) || __CUDA_ARCH__ >= 600
#else
<... placehere your own pre-pascal atomicAdd definition ...>
#endif
将如上的定义复制到如上文件里的头部, 将文件里定义的atomicadd function 剪切放在<... place here your ownpre-pascal atomicAdd definition ...> 中。