统计学习三要素的理解
统计学习的方法是基于数据构建统计模型从而对数据进行预测和分析。
形式化的表达:
统计学习方法 = 模型 + 策略 + 算法
实现统计学习方法的步骤:
1. 得到一个有限的训练数据集合
2. 确定包含所有可能的模型的假设空间,即学习模型的集合
3. 确定模型选择的准则,即学习的策略
4. 实现求解最优模型的的算法,即学习的算法
5. 通过学习方法选择最优模型
6. 利用学习的最优模型对新数据进行预测或分析
上述的模型、策略和方法称为统计学习的三要素。
1. 模型
在监督学习过程中,模型主要分为两种:
- 基于条件概率分布 - 概率模型
- 基于决策函数 - 非概率模型
2. 策略
统计学习的目标在于从假设空间选取最优模型,而通过什么标准来选取最优模型,这个衡量标准就是 “策略”。
定义损失函数和风险函数
损失函数 - 度量模型一次预测和好坏,风险函数度量平均意义下模型预测的好坏。
对于一次预测,预测值和真实值可能一致也可能不一致,用损失函数或代价函数来度量预测结果错误的程度,损失函数是 非负实值函数,即损失函数度量错误程度,值越小就说明错误越小模型越好。常用的损失函数
(1)0-1损失函数
(2)平方损失函数
(3)绝对损失函数
(4)对数损失函数
风险函数 - 度量模型平均意义下预测结果的好坏程度。
风险函数就是损失函数的期望
学习的目标是选择期望风险最小的模型,但是 我们是没办法求解的,原因是联合分布 是未知的,如果 已知,就可以得到 也就没有学习的必要了。
我们在学习概率论时,用过一种思想:
当样本很大时,频率 概率。(我不太确定能不能这样表示-.-)
自然而然的,我们很容易想到用模型在已知训练数据上的平均损失 (也称经验风险或经验损失)对于训练集
来代替 ,还是因为根据概率论与数理统计中的大数定律,当样本容量 趋于无穷大时,经验风险 趋于期望风险经验风险最小化和结构风险最小化
当样本容量很大时,经验风险最小化能保证有很好的学习效果,极大似然估计就是经验风险最小化的例子,当模型是条件概率分布,损失函数是对数损失函数时,经验风险最小化也就对应着极大似然估计。
但是,当样本容量很小时,经验风险最小化未必是最好的,因为容易使模型”过拟合”,为了避免这种情况,就需要考虑模型的 结构风险最小化 问题了。结构风险最小化(SRM) 等价与正则化,结构风险的定义:
是模型 的复杂度函数,根据Occamd 剃刀原理,复杂度表示对复杂模型的惩罚, 是系数。
结构风险最小化同时需要经验风险和模型复杂度都小,往往对训练数据和未知的测试数据都有比较好的预测。通过求解
找到最有的模型,也就是监督学习的策略。
3. 算法
由上,我们可以把统计学习问题归结为一个最优化的问题,那么如何求解最优化就需要到具体的 算法。对于一些没有解析解的问题,我们需要用到数值分析中的一些数值计算的方法得到逼近最优解的次优解,数学上也有专门的最优化理论与方法来处理这些问题,这部分我想在后面的学习过程中不断总结。
以上参考自李航博士的《统计学习方法》
知识补充部分
1. 关于模型
1.1 概率模型有哪些
个人从事AI相关领域,感觉最popular的概率模型当属贝叶斯(Bayesian Models)和马可夫(Markov Models)两大类。
贝叶斯包含: Naive Bayes, Bayesian Networks, Dynamic Bayesian Networks (DBNs) 马可夫包含: Markov Chain, Hidden Markov Model (HMM), Markov decision process (MDP), Partially observable Markov decision process (POMDP)
除此以外, Expectation Maximization (EM), Kalman Filters, Particle filtering 应该也可算是概率模型的一部分吧。以上除了普通的概率模型外有的还可以细分到 Graphical Models 或者 Temporal Models,有时间再回来补充细节吧。
作者:Mos Zhang
链接:https://www.zhihu.com/question/56578864/answer/171485301
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1.2 概率模型和非概率模型的理解
分别是从概率论和决策论的角度考虑。概率模型又分为有参与无参方法,有参方法即最终都是做一个参数估计,一般做点估计,利用极大似然等方法进行估计,无参方法主要是核方法和近邻法,就是在一块区域里面进行概率估计,哪个类别的概率最大,那么分类的对象就属于这个类别。
决策论即是利用一些方法对后续的步奏做决策,如:利用熵的方式进行决策,决策树等方法。
现今采用的较多的是概率模型的方式,因为有比较好的数学描述,决策树的方法在很多方面都有其优势,在速率方面适合大型数据的处理。
来源:百度知道(侵删)
2. 关于正则化
正则化实际上约束的是模型的参数 ,目的是缩小参数的数目,减少因从噪声点学到不必要的特征而产生过拟合的现象。
在正则化里,我们要做的事情,就是把减小我们的代价函数(例子中是线性回归的代价函数)所有的参数值,因为我们并不知道是哪一个或哪几个要去缩小。
λ 这个正则化参数需要平衡拟合训练的目标和保持参数值较小的目标。但是不是越大越好,当λ非常大时,所有参数 都会接近于零,剩下 对于数据来说这只是一条水平线。
- 常用的正则化:
1 和
2 正则化
关于 向量范数
0范数, 向量中非零元素的个数。
1范数, 为绝对值之和。
2范数,
就是通常意义上的模。
如果我们用 0 范数来规则化一个参数矩阵 的话,就是希望 的大部分元素都是0。换句话说,让参数W是稀疏的。那我们再来看看L1范数是什么?它为什么可以实现稀疏?为什么大家都用L1范数去实现稀疏,而不是L0范数呢?
任何的规则化算子,如果他在 的地方不可微,并且可以分解为一个“求和”的形式,那么这个规则化算子就可以实现稀疏。
既然 0 可以实现稀疏,为什么不用 0 ,而要用 1 呢?个人理解一是因为 0 范数很难优化求解(NP难问题),二是 1 范数是 0 范数的最优凸近似,而且它比 0 范数要容易优化求解。
2 范数也不逊于 1 范数,有人把有它的回归叫“岭回归”(Ridge Regression),有人也叫它“权值衰减weight decay”。我们让 2 范数的规则项 最小,可以使得 的每个元素都很小,都接近于0,但与 1 范数不同,它不会让它等于0,而是接近于0,这里是有很大的区别的哦。而越小的参数说明模型越简单,越简单的模型则越不容易产生过拟合现象。
来源:http://blog.csdn.net/zouxy09/article/details/24971995
注释: 我的理解和上面作者一样,参数越小也就意味着对应的的特征在实际中发挥的作用越小,甚至到小到一定程度时可以忽略即相当于消除了这个特征。
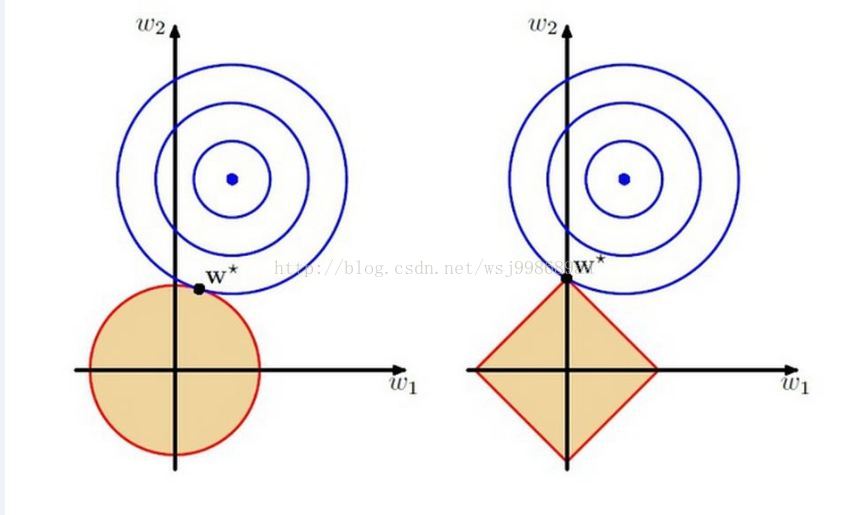
1 和 2 正则化的解空间直观理解
从左到右分别是 2 和 1 ,这里的w1,w2都是模型的参数,要优化的目标参数,那个红色边框包含的区域,其实就是解空间,正如上面所说,这个时候,解空间“缩小了”,你只能在这个缩小了的空间中,寻找使得目标函数最小的w1,w2。
来源:http://blog.csdn.net/wsj998689aa/article/details/39547771
为什么 2 叫权重衰减以及 1 稀疏作用的解释:
2 regularization(权重衰减)
2 正则化就是在代价函数后面再加上一个正则化项:(注意这里是
范数的平方!)
0 代表原始的代价函数,后面那一项就是 2正则化项,它是这样来的:所有参数w的平方的和,除以训练集的样本大小n。λ就是正则项系数,权衡正则项与C0项的比重。另外还有一个系数1/2,1/2经常会看到,主要是为了后面求导的结果方便,后面那一项求导会产生一个2,与1/2相乘刚好凑整。
对新的代价函数求导:
L2正则化项对b的更新没有影响,但是对于w的更新有影响:
因为 、 、 都是正的,所以 它的效果是减小w,这也就是权重衰减(weight decay)的由来。当然考虑到后面的导数项,w最终的值可能增大也可能减小。
1 regularization
代价函数:
计算导数:
上式中sgn(w)表示w的符号。
权重w的更新规则为:
比原始的更新规则多出了η * λ * sgn(w)/n这一项。当w为正时,更新后的w变小。当w为负时,更新后的w变大——因此它的效果就是让w往0靠,使网络中的权重尽可能为0,也就相当于减小了网络复杂度,防止过拟合。
来源:
https://zm12.sm-tc.cn/?src=l4uLj8XQ0IiIiNGSnpKWnJCbmtGckJLQlpGZkNKbmouelpPSys7Iys%2FL0ZeLkpM%3D&uid=f9d00c68c165e1deca2bfd92dbb31db1&hid=247a1ecb485d239ea9a69c3f4b62d99f&pos=6&cid=9&time=1520563799779&from=click&restype=1&pagetype=0200000000000400&bu=structure_web_kv&query=L2%E6%AD%A3%E5%88%99%E5%8C%96&mode=&v=1&uc_param_str=dnntnwvepffrgibijbprsvdsdichei
总结:
1 正则化可以产生一个稀疏权值矩阵,更擅长用在 特征选择。
2 正则化可以在训练的过程中防止过拟合,在一定程度上, 1 也可以防止过拟合。
- 神经网络中的 Dropout
Ng在深度学习中提到的,Droupout正则化采用随机删除节点的方式(在训练过程中删除,在验证过程中不删除)来达到防止过拟合的方式。另外深度学习中的正则化在《Deep Learning》 中是一个大专题,之后再详细讨论。