在跟着莫烦学完使用TensorFlow 实现 循环神经网络 RNN (https://www.bilibili.com/video/av16001891/?p=33),看着自己按照教程写的代码,一看,还有点懵… 在初步学习和研究之后,有了很多新的体会。
先上代码
# -*- coding: utf-8 -*-
"""
Created on Tue Mar 20 13:18:49 2018
@author: lyh
"""
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data',one_hot=True)
#超参数
lr = 0.001 #learning rate
training_iters = 100000
batch_size = 100
n_inputs = 28 #RNN 一行一行输入 一张照片28行
n_steps = 28 #28列
n_hidden_units = 128
n_classes = 10
#输入输出
x = tf.placeholder(tf.float32,[None,n_steps,n_inputs])
y = tf.placeholder(tf.float32,[None,n_classes])
#参数
weight = {
'in':tf.Variable(tf.random_normal([n_inputs,n_hidden_units])),
'out':tf.Variable(tf.random_normal([n_hidden_units,n_classes]))
}
biase = {
'in':tf.Variable(tf.constant(0.1,shape=[n_hidden_units])),
'out':tf.Variable(tf.constant(0.1,shape=[n_classes]))
}
#def RNN
def RNN(X,weight,biase):
#hidden layer for input to cell
#X (100 batth ,28 n_steps, 28 n_inputs) >> (100 * 28, 28)
X = tf.reshape(X,[-1,n_inputs])
#X_in ==> (100 batch * 28 steps,128 hidden)
X_in = tf.matmul(X,weight['in']) + biase['in']
#X_in ==> (100 batch, 28 steps,128 hidden)
X_in = tf.reshape(X_in,[-1,n_steps,n_hidden_units])
#cell
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(n_hidden_units,forget_bias=1.0,state_is_tuple=True)
#初始状态 一般可以取零矩阵
_init_state = lstm_cell.zero_state(batch_size,dtype=tf.float32)
#最基本的RNN 中 output = state
#dynamic_rnn 动态步进 避免反复调用cell.call()
outputs,states = tf.nn.dynamic_rnn(lstm_cell,X_in,initial_state=_init_state,time_major=False)
#hidden layer for output
#unstack 矩阵解体 to list[(bath,outputs)] * steps
outputs = tf.unstack(tf.transpose(outputs,[1,0,2]))
result = tf.matmul(outputs[-1],weight['out']) + biase['out']
return result
pred = RNN(x,weight,biase)
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred,labels=y))
train = tf.train.AdamOptimizer(lr).minimize(cost)
correct_pred = tf.equal(tf.argmax(pred,1),tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred,tf.float32))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
step = 0
while step * batch_size < training_iters:
batch_xs,batch_ys = mnist.train.next_batch(batch_size)
batch_xs = batch_xs.reshape([batch_size,n_steps,n_inputs])
sess.run([train],feed_dict={x:batch_xs,y:batch_ys})
if step % 20 == 0:
print(sess.run(accuracy,feed_dict={x:batch_xs,y:batch_ys}))
step += 1
假设,在都知道 RNN 大概是个什么东西的前提下,对 循环神经网络 和 递归神经网络 进行解释,广义上说,递归神经网络可以分为 结构递归神经网络 和 时间递归神经网络;狭义上,递归神经网络通常就是指结构递归神经网络,而时间递归神经网络则是我们通常说的 循环神经网络 (RNN)。
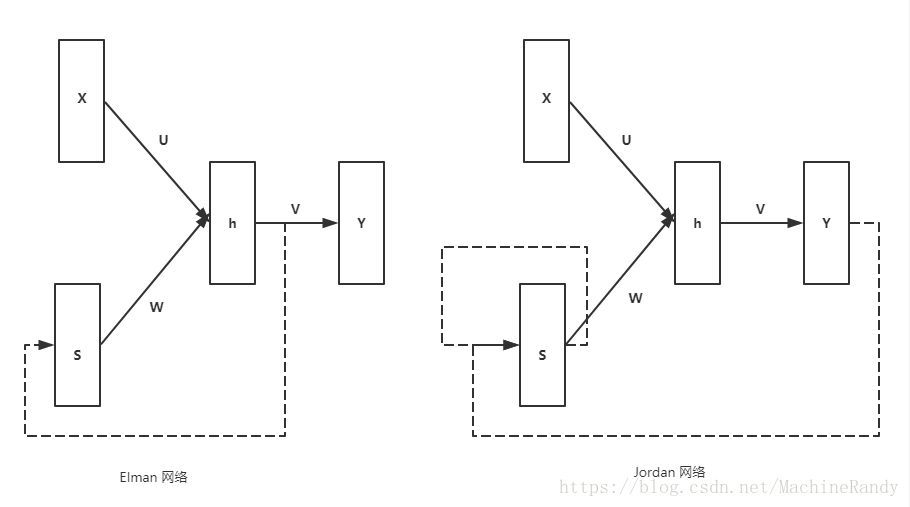
循环神经网络的变形多种多样,而最基本的标准循环神经网络有两种不同的结构类型:Elman 网络 和 Jordan 网络。
他们的共同点在与 上下文节点(S)的激活函数一般取恒等函数可以起到信息传递中介的作用,这里要讨论的以 Elman 网络为主。
Elman 网络在时间 0 - T 的计算过程可以描述为:
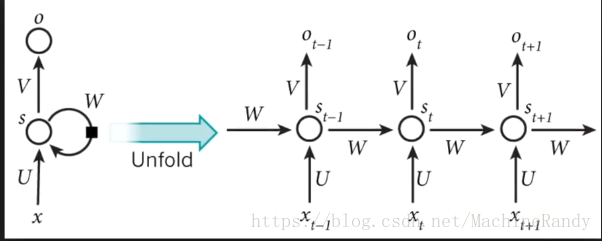
其中, , 是激活函数;循环神经网络可以采用按时间展开的反向传播算法来学习——BPTT(Backpropagation Through Time )算法,这里略
Jordan network和Elman network都是很久以前的奠基性工作了,所以都是基于最浅的三层网络结构定义的。Elman network就是指现在一般说的RNN(包括LSTM、GRU等等)。一个recurrent层的输出经过时延后作为下一时刻这一层的输入的一部分,然后recurrent层的输出同时送到网络后续的层,比如最终的输入层。一个Jordan network说的是直接把整个网络最终的输出(i.e. 输出层的输出)经过时延后反馈回网络的输入层,所以Jordan network的整个网络的所有层都是recurrent的。Elman network和Jordan network通常被统称为Simple recurrent network。个人认为可能是因为Elman network里相对独立的recurrent使用起来比较灵活(比如可以用作单独的层做不同类型层的堆叠等组合;同时Jordan network在网络输出层很大的时候可能需要降维来方便输入层接受前一时间的输出),所以Elman network现在基本上是主流,以至于大家都直接叫它RNN而它本来的名字。
作者:知乎用户
链接:https://www.zhihu.com/question/263966071/answer/275295727
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。在 TensorFlow 中,
#最基本的RNN 中 output = state
#dynamic_rnn 动态步进 避免反复调用cell.call()
outputs,states = tf.nn.dynamic_rnn(lstm_cell,X_in,initial_state=_init_state,time_major=False)代码中 tf.nn.dynamic_rnn 方法返回的实际上是 rnn_cell 的call() 方法返回的 outputs 和 states , 两者其实是一样的,
参考源码:
def call(self, inputs, state):
"""Most basic RNN: output = new_state = act(W * input + U * state + B)."""
output = self._activation(_linear([inputs, state], self._num_units, True))
return output, output真实输出 y 是
result = tf.matmul(outputs[-1],weight['out']) + biase['out']从维度上对循环神经网络整体进行辨析
循环神经网络中的状态是通过一个向量来表示的,这个向量的维度也称为循环神经网络隐藏层的大小,假设其为 ,假设输入向量的维度为 ,那么循环神经网络循环体的输入大小是 ,也就是将上一个时刻的状态与当前时刻的输入拼接成一个大的向量作为循环体中的神经网络的输入,因为该神经网络的输出为当前时刻的状态,于是在输出层的节点个数也为 ,循环体中的参数为 ,其中 是网络权重参数,后面的 为状态参数。
为了更好理解,我们用图来显示上面的表述:
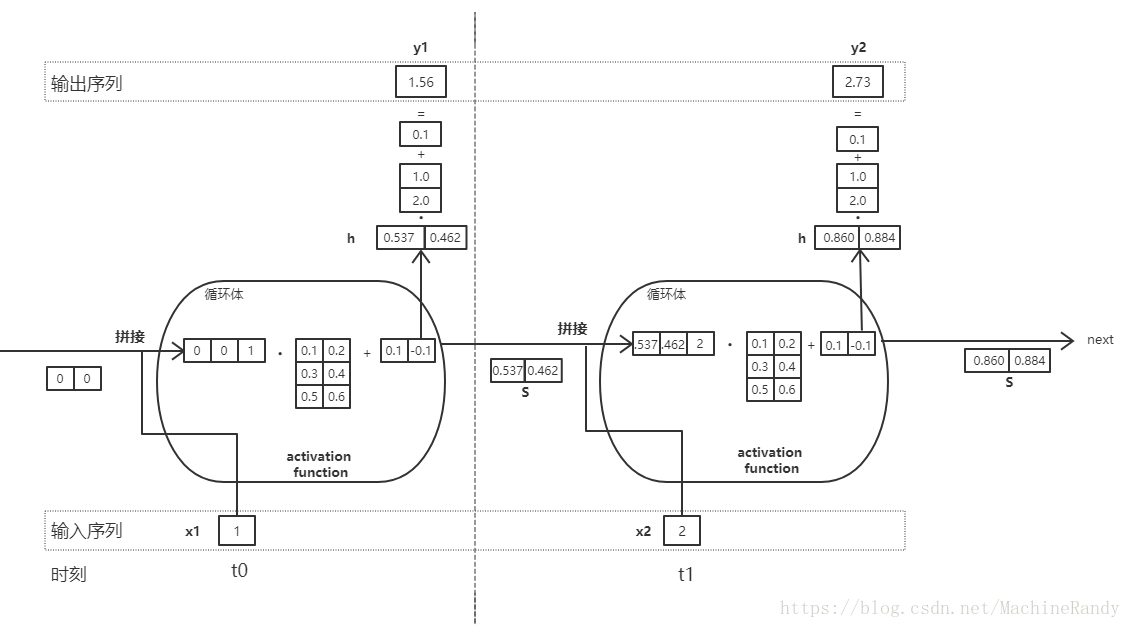
上图展示了一个 Elman 循环神经网络的一个计算小栗子,画了挺长时间,希望改天自己还能理解 …φ(๑˃∀˂๑)♪ 学习是我的全部
在最上面 TensorFlow 的例子中,关于各变量、参数 shape 的定义:
#输入输出
x = tf.placeholder(tf.float32,[None,n_steps,n_inputs])
y = tf.placeholder(tf.float32,[None,n_classes])
#参数
weight = {
'in':tf.Variable(tf.random_normal([n_inputs,n_hidden_units])),
'out':tf.Variable(tf.random_normal([n_hidden_units,n_classes]))
}
biase = {
'in':tf.Variable(tf.constant(0.1,shape=[n_hidden_units])),
'out':tf.Variable(tf.constant(0.1,shape=[n_classes]))
}
从 权重 weight 中仔细可以看出仅定义了 、 而没有 ,即没有隐藏层到隐藏层的权重 的定义,我个人看法是认为,这跟 RNN_cell 的定义有关,还没有仔细研究源码,也没有查到相关资料,目前猜测是 通过我们传入的state size 然后内部定义(瞎猜的,待查证,欢迎大佬们指出ヾ(๑╹◡╹)ノ”)