早就耳闻tensorflow-gpu与CUDA,cudnn三者之间版本匹配很复杂,今天算是见识到了。
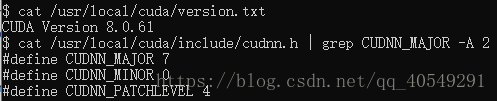
首先看了下服务器上的CUDA、cudnn版本,分别是CUDA8.0,cudnn7.0.4
这个匹配很奇怪,一般都是CUDA8 + cudnn6或者 CUDA9 + cudnn7
后来知道是要看软链接的(软链接的含义请自行百度),安装了cudnn7未必使用的就是7版本
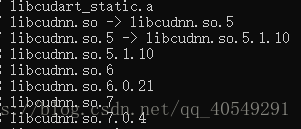
服务器上软链接情况是这样的
果然,软链接的是cudnn5。所以我的配置实际上是CUDA8 + cudnn5
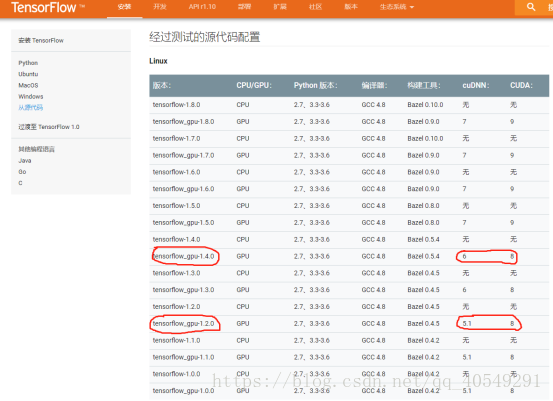
接着查阅到tensorflow官网上有介绍,如下图
那很自然就想到安装1.2.0版本的tensorflow了,结果是这样,运行import tensorflow as tf
Tensorflow都导入不了
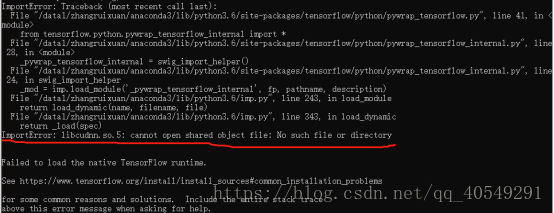
继续google…
期间尝试了更换GCC版本(失败,甚至产生了其他错误)
在我账号下的.bashrc中添加路径 export LD_LIBRARY_PATH=/usr/local/cuda/lib64/(失败,可以导入tensorflow,但不能使gpu)
更改cudnn的软链接(没敢试,因为会修改整个服务器)
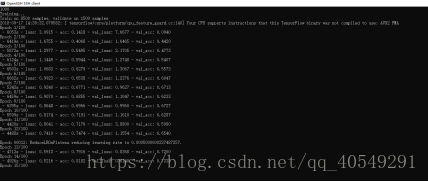
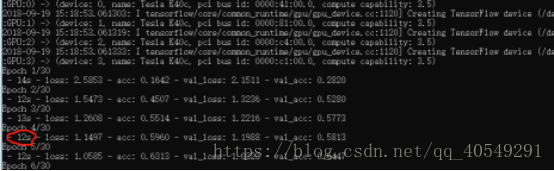
最后一气之下,我不用gpu了行吧,因为要使用dataset,所以重新下载了tensorflow1.4.0,虽然想着不用gpu,但因为某种执念,还是下载了gpu版本的,然后,跑了下程序,发现
能用gpu了
好了!
好了?
好了。。
之前
现在
所以最终是CUDA8 + cudnn5 + tensorflow-gpu1.4.0
注:只是记录了本人的经历与理解,如有错误之处,欢迎批评指正!