前言:
本次项目分为两部分。
第一部分编写的爬虫主要功能为爬取小说相关信息,例如小说标题、作者、简介以及小说链接等,并保存至mongoDB。随后对其增加了交互式界面,实现了小说种类的分类以及页面数限制,最后可获得感兴趣小说的完整小说内容并且自动创建文件夹保存至本地。
第二部分编写的爬虫主要是实现大规模的小说爬取,将小说网站上的所有小说爬取下来,自动创建好文件下保存至本地。
本篇文章仅介绍第一部分,对第二部分感兴趣可直接查看下一篇。
1、准备工作
本次爬虫使用的库主要是requests、使用xpath解析,数据库使用pymongo。
2、爬取目标
本次爬取得目标站点为起点网的免费小说,URL为https://www.qidian.com/free/all。需要爬取得内容为小说标题、作者、简介以及小说链接等。
3、提取信息
按照惯例,首先需要对网站进行分析。访问该网站很容易发现,小说所有信息都是属于静态加载,这样一来我们提取相关信息就非常简单了。

打开开发者模式,如图一。可以看到页面所有小说相关内容在data-rid为属性的li标签下。用xpath匹配出所有li节点即可。

图一
接下来,遍历出每一个节点,然后提取出每一个小说的相关信息。这里仅以小说标题为例子,其他信息的获取不再赘述。
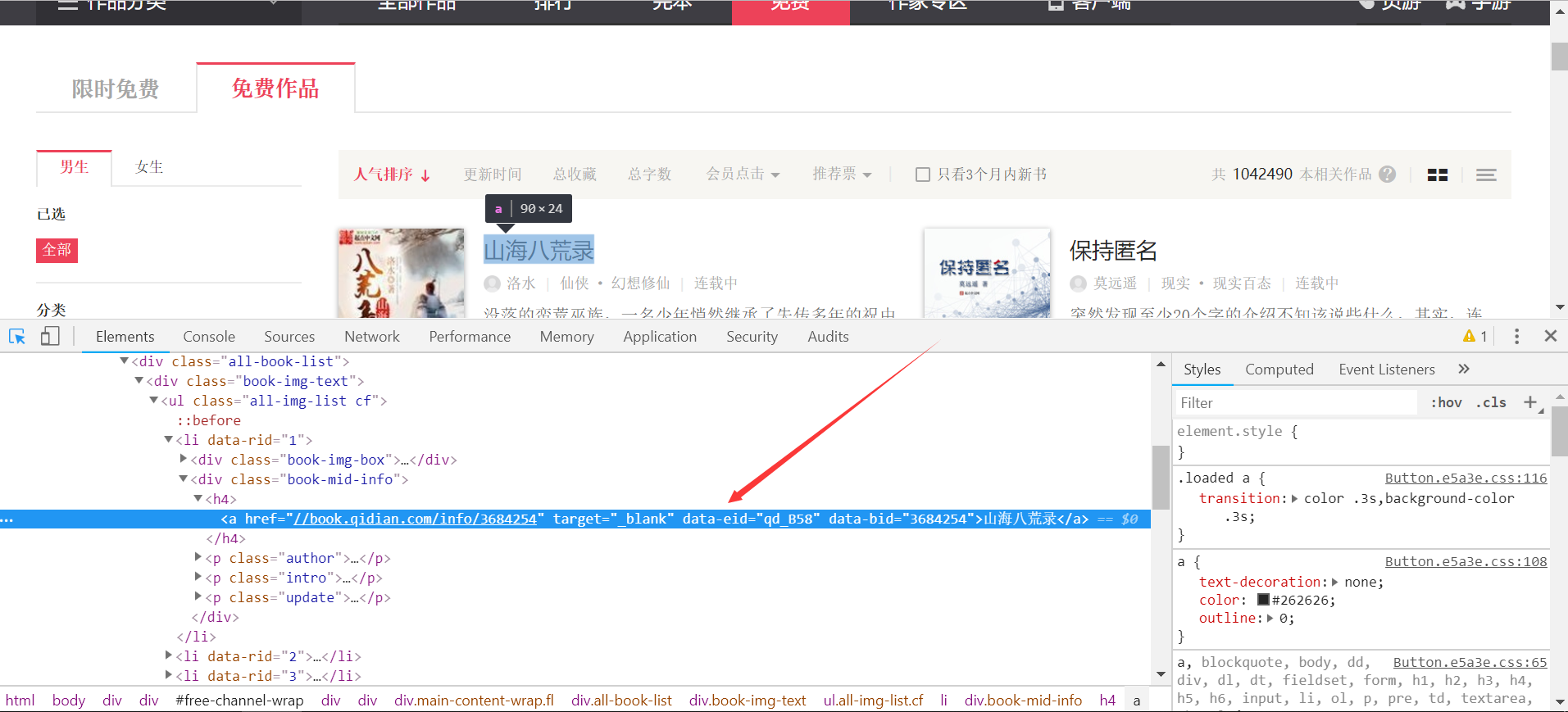
图二
如图二,小说标题title在div标签下的h4的标签下,运用xpath易得到title的匹配规则为//div[@class="book-mid-info"]/h4/a/text(),这样我们就很轻松的得到了小说标题。
下面只需要用同样的方法提取出所需要的信息,然后使用一个字典包含所有信息即可,代码实现如下:
1 html= etree.HTML(response.text) 2 # 所有小说 3 items = html.xpath('//li[@data-rid]') 4 # 遍历每个小说 5 for item in items: 6 # 标题 7 title = item.xpath('.//div[@class="book-mid-info"]/h4/a/text()')[0] 8 # 作者 9 author = item.xpath('.//p[@class="author"]/a[@class="name"][1]/text()')[0] 10 # 封面 11 cover = item.xpath('.//div[@class="book-img-box"]/a/img/@src')[0] 12 # 简介 13 intro = item.xpath('.//p[@class="intro"]//text()')[0].strip() + '...' 14 # 链接 15 link = item.xpath('.//div[@class="book-img-box"]/a/@href')[0] 16 # 包含各个信息的字典 17 novel = { 18 'title': title, 19 'author': author, 20 'cover': cover, 21 'intro': intro, 22 'link': link 23 } 24 yield novel
4、spider
编写好提取小说相关信息的方法后,接下来需要完善好一个spider类,要求能够得到页面的response,然后解析提取出小说信息,并且还要将信息保存到mongoDB中。实现代码如下:
1 class Spider(object): 2 mongo_uri = 'localhost' 3 mongo_db = 'xiaoshuo' 4 5 def __init__(self, url): 6 self.url = url 7 self.client = pymongo.MongoClient(self.mongo_uri) 8 self.db = self.client[self.mongo_db] 9 print('正在爬取第%s页..' % self.page) 10 11 def get_html(self): 12 """ 13 得到页面 14 :return: 返回响应体 15 """ 16 headers = { 17 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) ' 18 'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36', } 19 response = requests.get(url=self.url, headers=headers) 20 return response.text 21 22 def parse(self,html): 23 """ 24 解析页面,得到小说相关信息 25 :param html: 页面html 26 :return: 返回包含小说信息的字典novel 27 """ 28 html= etree.HTML(html) 29 # 所有小说 30 items = html.xpath('//li[@data-rid]') 31 # 遍历每个小说 32 for item in items: 33 # 标题 34 title = item.xpath('.//div[@class="book-mid-info"]/h4/a/text()')[0] 35 # 作者 36 author = item.xpath('.//p[@class="author"]/a[@class="name"][1]/text()')[0] 37 # 封面 38 cover = item.xpath('.//div[@class="book-img-box"]/a/img/@src')[0] 39 # 简介 40 intro = item.xpath('.//p[@class="intro"]//text()')[0].strip() + '...' 41 # 链接 42 link = item.xpath('.//div[@class="book-img-box"]/a/@href')[0] 43 # 包含各个信息的字典 44 novel = { 45 'title': title, 46 'author': author, 47 'cover': cover, 48 'intro': intro, 49 'link': link 50 } 51 yield novel 52 53 def write_to_mongoDB(self, novel): 54 """ 55 把结果保存到mongoDB 56 :param novel: 小说 57 """ 58 if self.db[self.collection].insert(novel): 59 print('保存成功!')
写好这个spider类后,需要创建一个实例对象,传入小说网站URL,再调用相关方法就可以得到最后的结果了。
1 spider = Spider(url=url) 2 # 调用相应方法 3 html = spider.get_html() 4 novel = spider.parse(html) 5 spider.write_to_mongoDB(novel)
打开mongoDB可以查看到获取的结果,如图三所示。
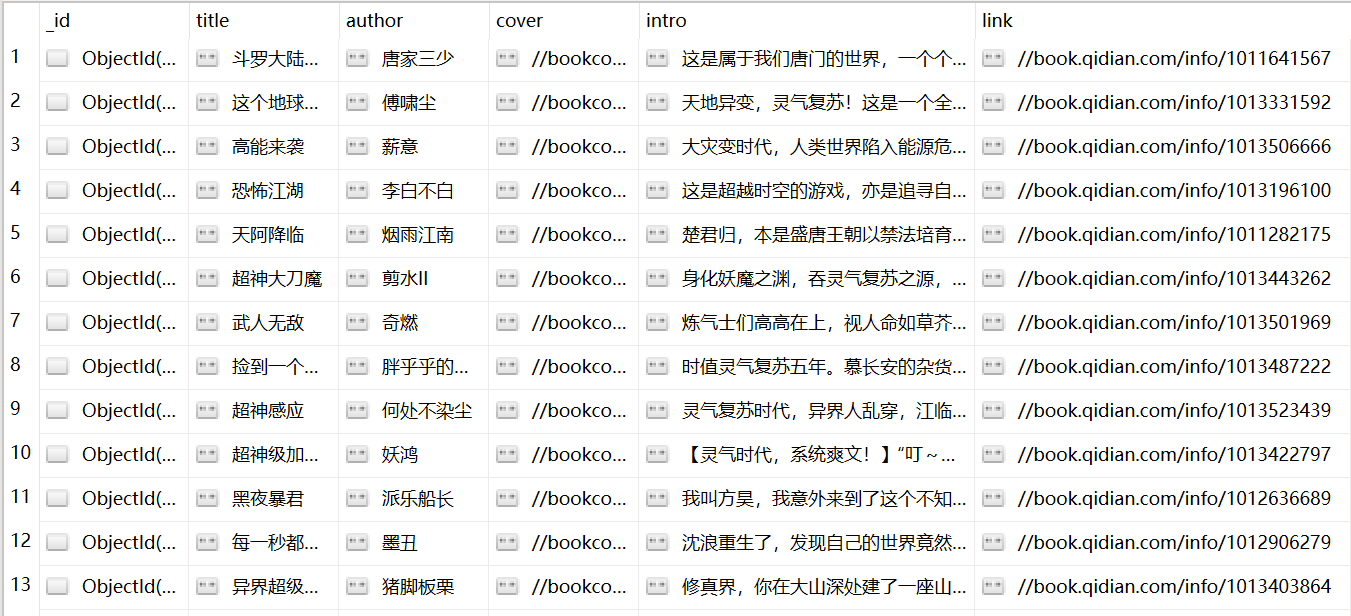
图三
6、interface
上述中,虽然我们得到了小说相关信息,但是得到的还只是一页的信息,而且没有小说分类,不太好分类整理信息。所以这里希望增加一个模块inter来实现交互式界面,提供一个可选择小说种类以及爬取的最大页面数的功能,这样就可以分类保存小说一定数量的小说了。
话不多说,首先来看小说网站,如图四。
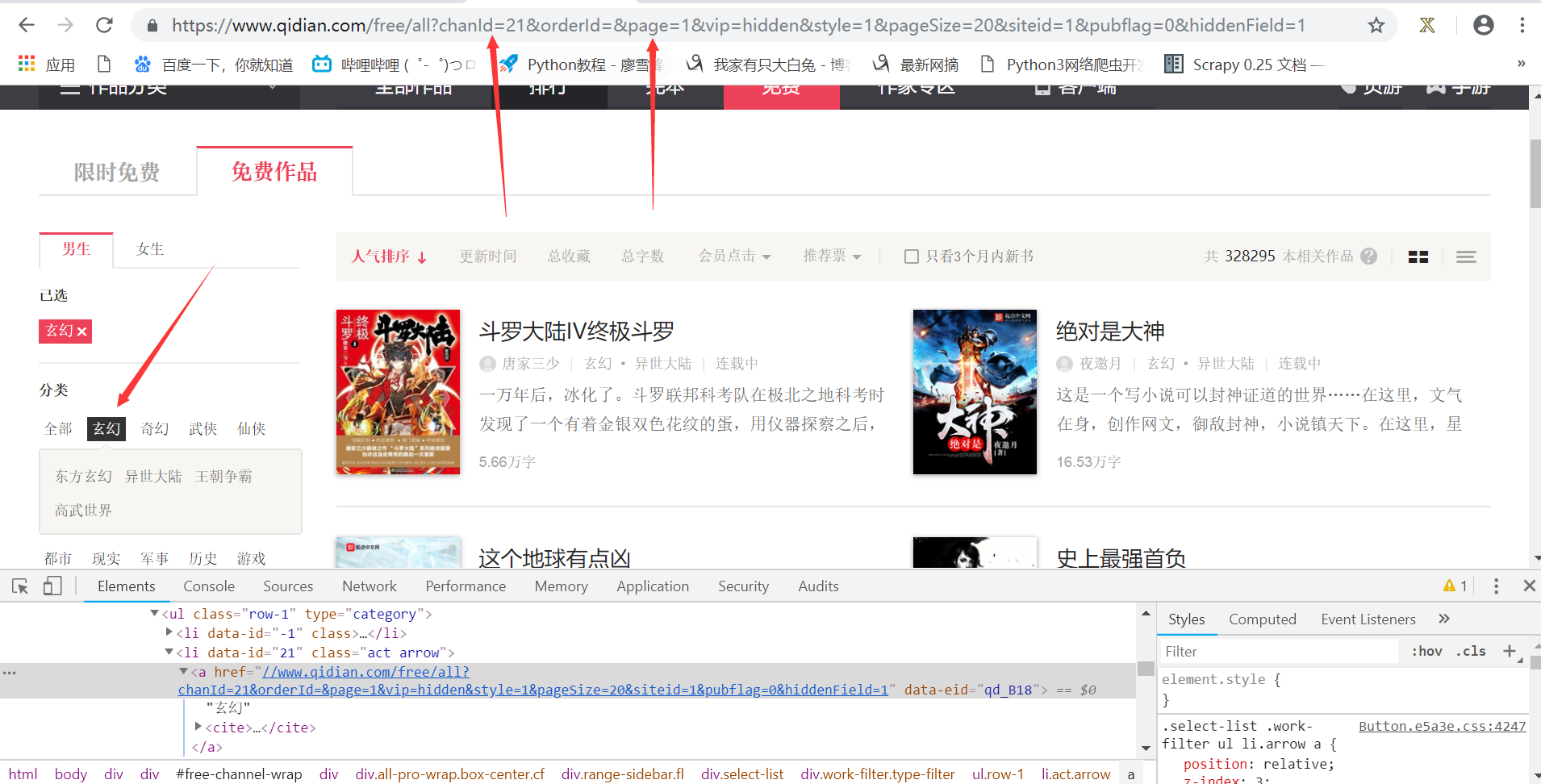
选择玄幻类的小说,可以看到页面的URL有两个比较重要的参数chanID和page。
chanID以及后面的数字就是代表就是小说的类别,如图五。

玄幻类的小说chanID=21,科幻类chanID=9,多选取几个小数类别,构建一个小说类别以及对应的chanID的值得字典novel_list,如下:
1 novel_list = { 2 '奇幻': '?chanld=1', 3 '武侠': '?chanld=2', 4 '仙侠': '?chanld=22', 5 '都市': '?chanId=4', 6 '历史': '?chanId=5', 7 '游戏': '?chanId=7', 8 '科幻': '?chanId=9', 9 '灵异': '?chanId=10', 10 '短篇': '?chanId=20076', 11 '玄幻': '?chanld=21' 12 }