有一天发现我关注了好多微信公众号,那时就想有没有什么办法能够将微信公众号的文章弄下来,而且还想将一些文章的精彩评论一起搞下来。参考了一些文章,通过几天的研究基本上实现了自己的要求,现在记录一下自己的一些心得。
整个研究过程如下:
1.了解微信公众号文章链接的组成,历史文章API组成,单个文章评论API组成,访问微信公众号的cookie组成;
2.分析历史文章API以及单个文章评论API的结构,构建爬虫进行爬取;
前面两点需要借助于抓包工具Fiddler,下面会详细介绍抓包结果的分析,上一篇文章有介绍“ Fiddler在PC/台式对Android进行抓包”
3.设计表结构,将爬虫获取的数据存入到mysql数据库;
4.对获取的数据库信息进行过滤整理,将相关内容输出,选择相应文章进行阅读并消化。
一、微信公众号图文消息的链接组成
微信公众帐号群发的图文消息一般情况下是在微信公众平台上编辑和产生的。
我们先从比较有名的公众号“逻辑思维”的图文消息看看一篇图文消息链接的组成元素:
逻辑思维有一篇每天60秒的文章【罗胖60秒:一个“智慧系统”是什么样的?】,在微信打开通过浏览器查看到链接
http://mp.weixin.qq.com/s?__biz=MjM5NjAxOTU4MA==&mid=3009217237&idx=2&sn=881c0a758a43348e2e7602110862f6ec&chksm=90460ec6a73187d00ebc007b1429609573ca42b9ef1dd74d860b4716f04b63661b15cbee2c6b&mpshare=1&scene=23&srcid=1202m2DVBW8OubvaR1DcXF0a#rd
上面链接中的参数有__biz,mid,idx,sn,chksm,mpshare,scene和srcid
其实主要参数只有__biz,mid,idx和sn四个参数,而这四个参数能唯一确定一篇微信公众平台的图文消息,所以以下链接就可以访问文章
https://mp.weixin.qq.com/s?__biz=MjM5NjAxOTU4MA==&mid=3009217237&idx=2&sn=881c0a758a43348e2e7602110862f6ec
这四个参数的含义是:
__biz可以认为是微信公众平台对外公布的公众帐号的唯一id,而这个__biz参数能用来生成公众帐号的二维码
mid是图文消息id,每篇文章这个消息id都唯一
idx是发布的第几条消息(1就代表是头条位置消息,2代表第二条)
sn是一个随机加密串(对于一篇图文消息是唯一的,如果你想问这个sn的生成规则是什么或者怎么破解,你基本上只能从微信公众平台开发团队才能得到答案)
另外,对于除了__biz之外的三个参数,mid/idx/sn 可以分别写成 appmsgid/itemidx/sign,比如还是之前文章,用如下链接一样可以访问到:
https://mp.weixin.qq.com/s?__biz=MjM5NjAxOTU4MA==&appmsgid=3009217237&itemidx=2&sign=881c0a758a43348e2e7602110862f6ec
其实在早期,只需要__biz, mid和idx三个参数即可确定一篇微信公众平台的图文消息,微信后来增加一个参数sn(sign),这样做的原因是:
微信公众平台的图文消息首先在后台保存为了一篇素材才能发布,而这个素材也会生成一个链接,在早期这个素材的链接就是后来要发布的文章的链接,而从上面这篇文章的链接你能猜出来,只需要改变mid(图文消息id)这个值,比如这篇文章的mid是10000382,对这个数字加上1或者2就极有可能是下一篇图文消息或者素材的链接,这样用户就有可能提前阅读到公众帐号已经写好并保存但还没群发的素材了。
所以分布文章时会加上一个随机生成的参数sn,确保文章无法被知道。
二、微信公众号历史文章API组成
在公众号主页,右上角有个人上半身图标,点击进入消息界面,下滑找到并点击“全部消息”,往下请求加载几次历史文章,然后回到Fiddler界面,不出意外的话应该可以看到这几次请求,可以看到返回的数据是json格式的,同时文章数据是以json字符串的形式定义在general_msg_list字段中:
https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=MjM5NjAxOTU4MA==&f=json&offset=10&count=10&is_ok=1&scene=126&uin=777&key=777&pass_ticket=pI3viTq3ke7q4XBuvPFfW04X1NN374CuTXRryqcWqIUGGXvrmHzytAth%2BMUWmDEv&wxtoken=&appmsg_token=985_CXzmkHn3e3dS9vsefAmdITS4irh69Rk351ye-w~~&x5=1&f=json

以下介绍几个主要参数:
- __biz:相当于是当前公众号的id(唯一固定标志)
- offset:文章数据接口请求偏移量标志(从0开始),每次返回的json数据中会有下一次请求的offset,这里一般是按10递增的
- count:每次请求的数据量(亲测最多可以是10) ,所以可以固定为10
- pass_ticket:可以理解是请求票据,而且隔一段时间后(大概几个小时)就会过期,失效后都需要重新抓包替换
- appmsg_token:同样理解为非固定有过期策略的票据,失效后都需要重新抓包替换
三、微信公众号访问的cookie组成:
访问微信公众号历史文章,我们是需要登录的,我们可以通过构建cookie去跳过登录过程
通过访问微信公众号文章,我们通过Fiddler抓包可以看到cookie的相关信息
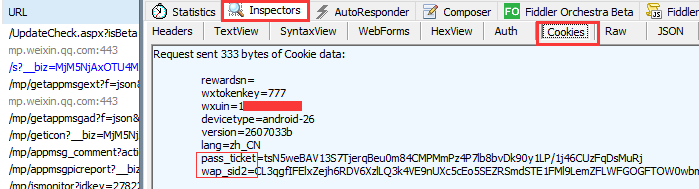
其中pass_ticket和wap_sid2不是固定的,经常有变化,失效了都需要重新抓包,而其他wxtokenkey,wxuin,devicetype,version等只要微信号不变,登录设备不变都不会改变。
四、微信公众号单个文章评论API组成
通过访问微信公众号文章,我们抓包可以得到文章评论的API,这个返回的也是json格式,评论存储在elected_comment
https://mp.weixin.qq.com/mp/appmsg_comment?action=getcomment&scene=0&__biz=MjM5NjAxOTU4MA==&appmsgid=3009217642&idx=2&comment_id=578089232589930496&offset=0&limit=100&uin=777&key=777&pass_ticket=v+7PaoESYfMrxgXJpqOkfXV4Y2+gYNPPJfSSmzPXfeiuNrNiBeEcs+8b//Yit5sd&wxtoken=777&devicetype=android-26&clientversion=2607033b&appmsg_token=986_jbuKqpV9lCZ1cb787Tem5V5n6JKpU9TrOFUZRE5esVxnBK7IR-TsZiXLRNaO1tnfx4rkIk1xyFHRlqI7&x5=1&f=json

还是介绍一下其中的主要参数:
- __biz:和历史文章列表中一致,微信公众号ID
- comment_id:评论的id,一篇文章唯一
- appmsgid:图文消息ID,与文章有关(文章链接中的mid)
- pass_ticket:请求票据,同一时间段内历史文章API和单个文章评论API一致
- appmsg_token:非固定有过期策略的票据,同一时间段内历史文章API和单个文章评论API不一致
以上主要介绍了整个研究过程的第一点,下面将会分析历史文章API和单个文章评论API的返回